在前面推文中我们分别介绍了2×2 χ2检验的假设检验理论,本篇推文将使用案例演示在R软件中实现2×2 χ2检验的操作步骤。
关键词:R语言; R软件; 卡方检验; 理论频数; 实际频数; 四格表
一、案例介绍
某中医院欲比较某经典名方控制高血压的效果。将200例高血压患者随机分到试验组(Trial group,用“1”表示)和对照组(Control group,用“2”表示),随访三个月后患者的血压控制情况[分为有效(Effective,用“1”表示)和无效(Noneffective用“2”表示)]。问该经典名方控制血压的效果如何?部分数据见图1。本文案例可从“附件下载”处下载。
二、问题分析
本案例的分析目的是探究某经典名方控制血压的效果,即比较试验组与对照组血压控制率是否有差异,针对这种情况可以制作四格表,并进行2×2 χ2检验。但需要满足3个条件:
条件1:分组变量与观察变量均为二分类变量。本案例的分组变量(Group)和观察变量(Effect)均为二分类变量,该条件满足。
条件2:观察变量相互独立。本研究中各研究对象的观察变量都是独立的,不存在互相干扰的情况,该条件满足。
条件3:总例数≥40,且所有期望频数(理论频数)≥5。该条件需要通过软件分析后判断。
本案例数据采用了频数资料录入方法,设置分组变量、观察变量及频数变量,该形式在进行χ2检验时较为常见,进行统计分析前需要进行数据的重新整理,形成可分析的矩阵格式。此外,数据还有一种非频数资料录入方式,只有分组变量和观察变量两列,每一行为一个患者的数据,该形式是在R软件中进行各种统计分析最常用的资料形式,进行检验前不需要进行数据的重新整理。
三、软件操作及结果解读
(一) 导入数据
mydata <- read.csv("2×2卡方检验.csv") #导入CSV数据
View(mydata) #查看数据
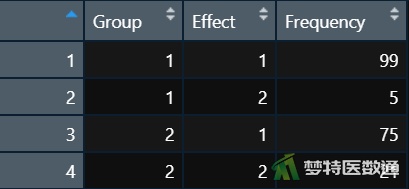
在数据栏目中可以查看全部数据情况,数据集中共有3个变量和4行观察数据,3个变量分别代表被调查者的分组(Group)、控制效果(Effect)及频数(Frequency)。
如果数据集较大也可使用如下命令查看数据框结构:
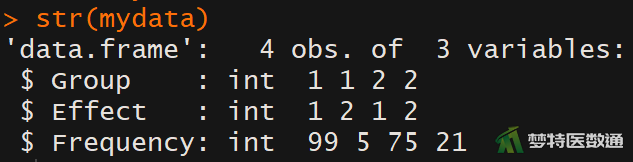
str(mydata) #查看数据框结构
(二) 适用条件判断
对于本案例数据,条件1和条件2均满足。但需要通过总例数和期望频数来选择具体的分析方法(Pearson χ2检验、连续校正χ2检验或Fisher确切概率法)。这一判断过程通过统计描述来完成,详见下文。
(三) 统计描述及推断
1. 数据整理
(1) 软件操作
## 数据整理 ##
compare<-matrix(c(99,75,5,21),nr=2,dimnames = list(c("Trial group","Control group"),c("Effective","Noneffective"))) #数据整理并编辑为矩阵格式
compare #查看数据
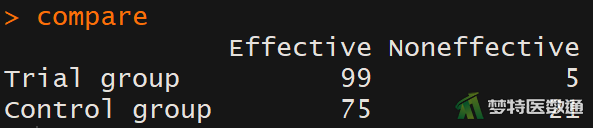
(2) 结果解读
图3的数据整理结果列出了卡方检验所需要的数据格式,并存储在“compare”数据框中。
2. 统计推断
(1) 软件操作
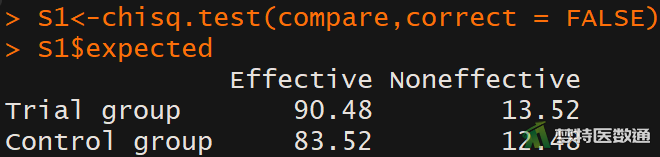
## 卡方检验 ## S1<-chisq.test(compare,correct = FALSE) #不进行连续性校正 S1$expected #查看期望频数
S1 #查看卡方检验结果
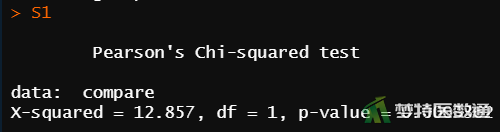
(2) 结果解读
由图4期望频数的结果可知,四格表的期望频数均>5。图5Pearson χ2检验结果表明两组高血压患者的血压控制率的差异有统计学意义 (\(x^2=12.857\),P=0.0003362)。
3. 计算构成比
(1) 软件操作
S2<-prop.table(compare,margin = 1) #计算行百分比 S2 #显示行百分比
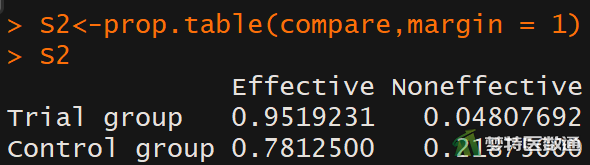
(2) 结果解读
图6给出了试验组 (Trial group)和对照组(Control group)的有效、无效百分比。由结果可知,试验组和对照组的血压控制率分别为95.2%和78.1%。
四、结论
本研究采用2×2 χ2检验(独立样本χ2检验)比较两组高血压患者血压控制率有无差别。数据满足2×2 χ2检验的条件,期望值均>5,采用Pearson χ2检验结果。结果显示,试验组和对照组的血压控制率分别为95.2%和78.1%,差异有统计学意义(\(x^2=12.900\),P<0.001),试验组的血压控制率高于对照组。