在前面文章中介绍了偏相关分析(Partial Correlations Analysis) 的假设检验理论,本篇文章将使用同样的案例演示在R软件中实现偏相关分析的操作步骤。
关键词:R语言; R软件; 偏相关分析; 偏相关系数
一、案例介绍
某高血压研究所收集了110例高血压患者的临床资料,包括年龄、BMI、同型半胱氨酸(Hcy)、胆固醇、尿酸(UA)和24小时收缩压标准差(24hSSD)和24小时收缩压变系数(24hSCV)等,研究Hcy与24hSSD或24hSCV的相关性。经过前期分析发现,Hcy、UA和24hSSD有相关性,现欲了解控制UA的影响后,Hcy与24hSSD的相关性。部分数据见图1。本文案例可从“附件下载”处下载。
二、问题分析
本案例的分析目的是考察控制某因素的影响后,两个连续性变量之间的相关性,可以使用Pearson偏相关性分析。但需要满足以下6个条件:
条件1:两个变量均为连续变量。本研究中Hcy与24hSSD均为连续性变量,该条件满足。
条件2:样本独立性。样本来自总体的随机样本,且被试者之间必须相互独立,该条件满足。
条件3:两个变量及需要控制的变量应当是配对的,即来源于同一个体的特征或属性。本案例中同时检测了研究对象的同型半胱氨酸、尿酸和24小时收缩压标准差,变量之间是对应关系,该条件满足。
条件4:两个变量服从正态(或近似正态)分布,该条件需要通过软件分析后判断。
条件5:两个连续变量之间存在线性关系,该条件需要通过软件分析后判断。
条件6:两个变量都不存在明显的异常值,该条件需要通过软件分析后判断。
三、软件操作及结果解读
(一) 导入数据
mydata <- read.csv("偏相关分析.csv") #导入CSV数据
View(mydata) #查看数据
在数据栏目中可以查看全部数据情况,数据集中共有3个变量和110个观察数据,3个变量分别为尿酸(UA)、同型半胱氨酸(Hcy)与24小时收缩压标准差(X24hSSD)。
如果数据集较大也可使用如下命令查看数据框结构:
str(mydata) #查看数据框结构

(二) 适用条件判断
1. 条件4判断(正态性检验)
(1) 软件操作
##绘制QQ图## par(mfrow = c(1, 2)) #设置1行2个图 qqnorm(mydata$Hcy, ylab="Hcy", main="Hcy") #绘制Hcy的qq图 qqline(mydata$Hcy) #增加趋势线 qqnorm(mydata$X24hSSD, ylab="X24hSSD", main="X24hSSD") #绘制X24hSSD的qq图 qqline(mydata$X24hSSD) #增加趋势线
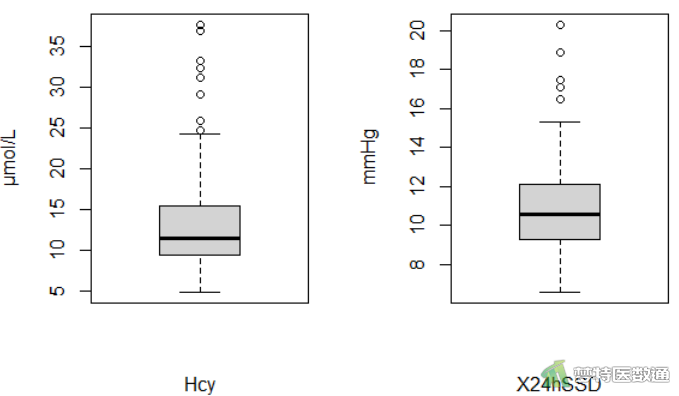
##正态性检验## shapiro.test(mydata$Hcy) shapiro.test(mydata$X24hSSD)
(2) 结果解读
图3分别列出了两个变量的Q-Q图,可见散点基本围绕对角线分布,提示两个变量服从正态分布。图4显示了Shapiro-Wilk (夏皮罗-威尔克正态性,S-W)正态性检验的结果,可见P值分别为0.5327和0.8363,均>0.1,提示两变量均服从正态分布。综上,本案例满足条件4。
2. 条件5判断(线性关系分析)
(1) 软件操作
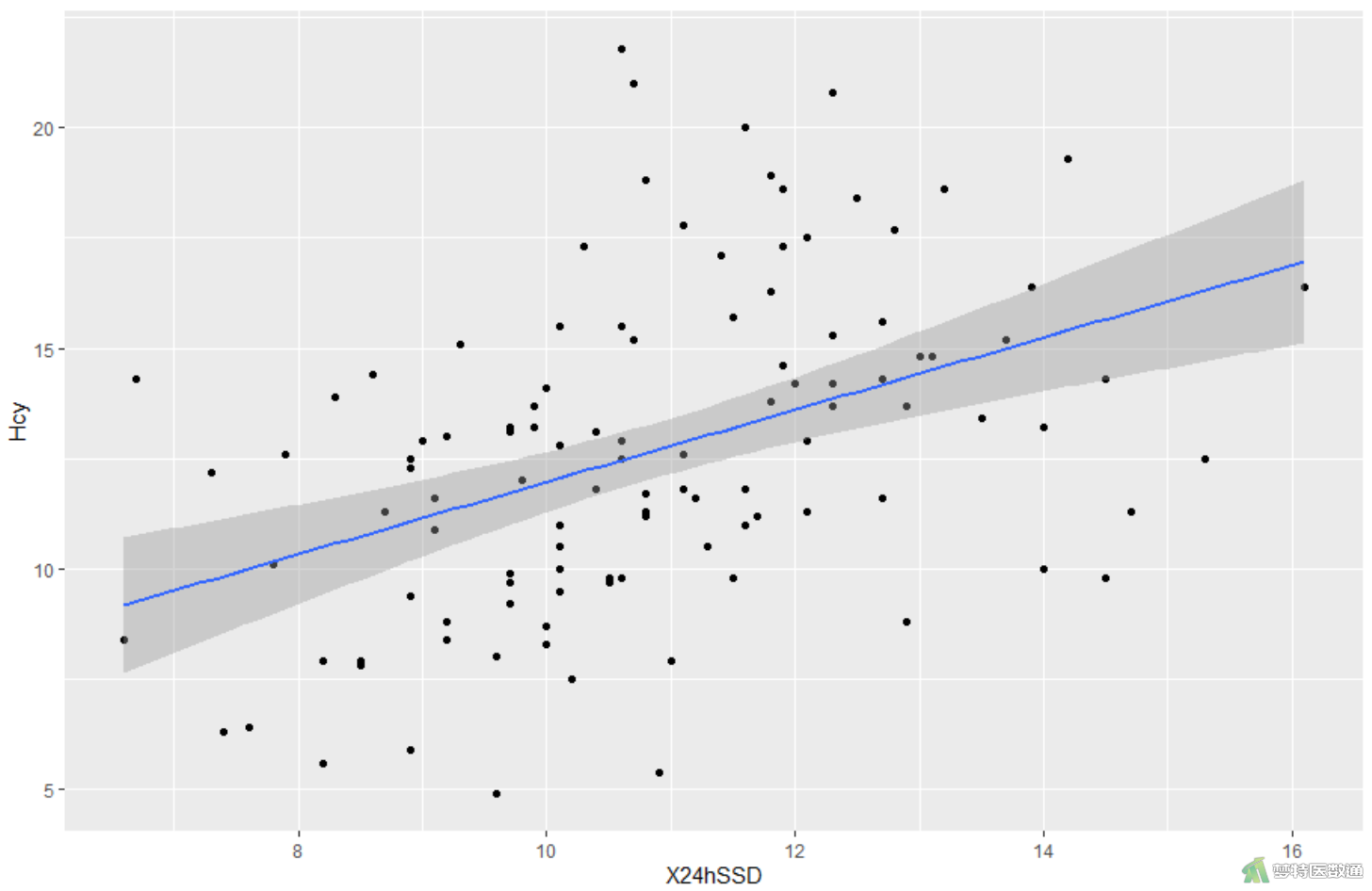
##线性关系判断## library(ggplot2) #启动ggplot2软件包 ggplot(data=mydata,aes(x=X24hSSD,y=Hcy))+geom_point()+stat_smooth(method="lm",se=TRUE) #绘制散点图
(2) 结果解读
图5为同型半胱氨酸和24小时收缩压标准差的散点图,散点大致呈一条直线,说明存在线性关系。该条件满足。
3. 条件6判断(异常值判断)
(1) 软件操作
##绘制箱线图##
par(mfrow=c(1,2)) #绘制一行2个图
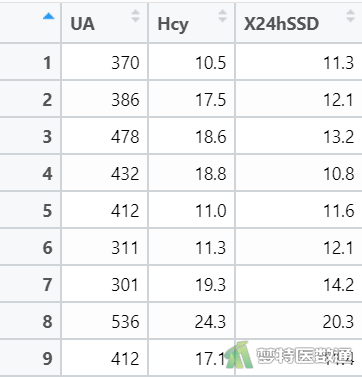
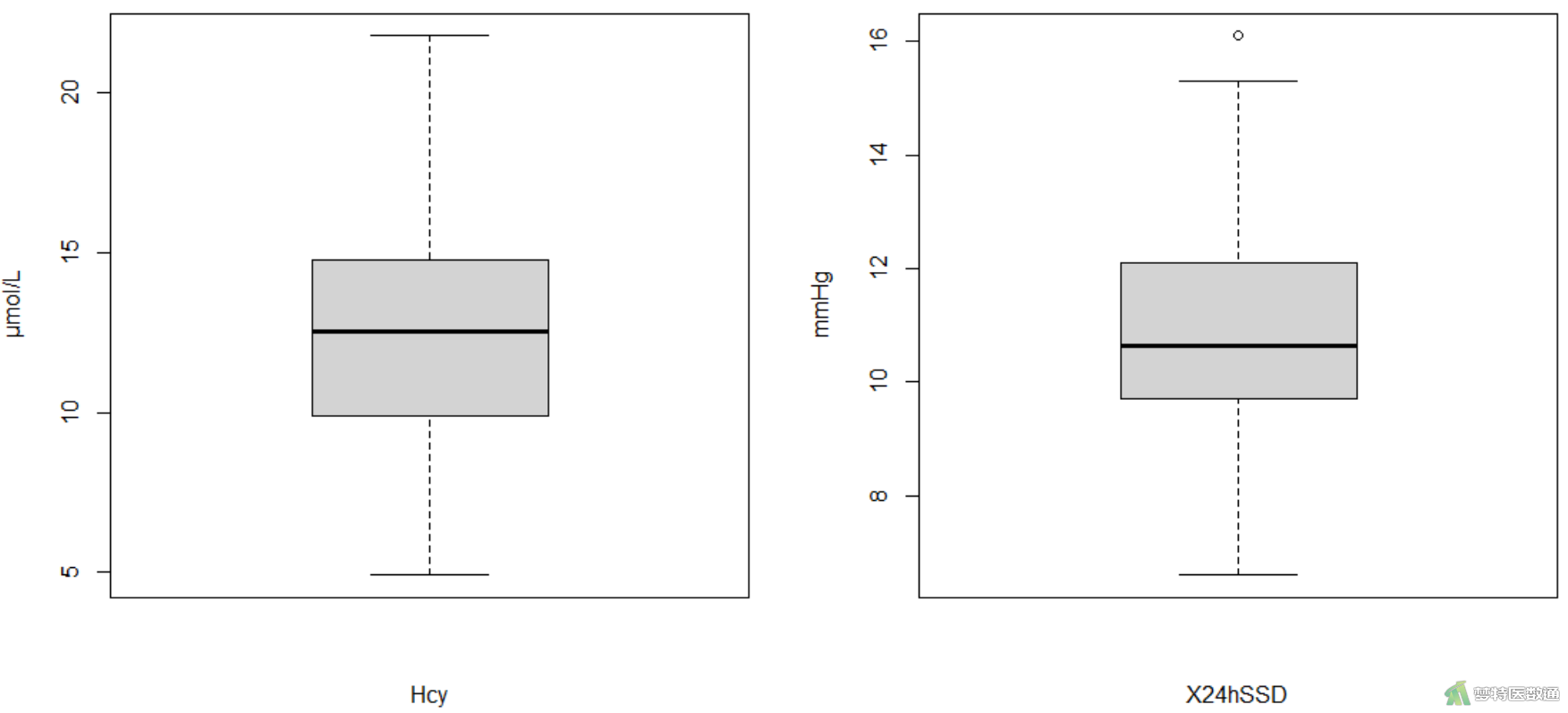
boxplot(mydata$Hcy,xlab = c("Hcy"), ylab = expression("μmol/L")) #绘制Hcy的箱线图
boxplot(mydata$X24hSSD,xlab = c("X24hSSD"), ylab = expression("mmHg")) #绘制X24hSSD的箱线图
##检查数据最大最小值## summary(mydata$Hcy) #描述Hcy变量 summary(mydata$X24hSSD) #描述X24hSSD变量

(2) 结果解读
图7“Summary (描述性分析)”表格中,列出了观察变量的最小值和最大值,依据专业可判断同型半胱氨酸可能存在4.9 μmol/L和37.6 μmol/L,24小时收缩压标准差可能存在6.6 mmHg和20.3 mmHg的情况;此外,图6两个箱线图虽然提示存在部分异常值,但考虑到最大值和最小值都有可能发生,所以不需要进行特殊处理。综上,本案例未发现需要处理的异常值,满足条件6。
(三) 统计描述及推断
1. 软件操作
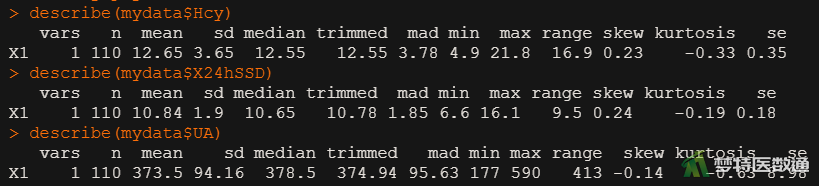
##描述统计## library(psych) #调用包“psych” describe(mydata$Hcy) #Hcy变量描述统计 describe(mydata$X24hSSD) #X24hSSD变量描述统计 describe(mydata$UA) #UA变量描述统计
##偏相关分析##
install.packages("ggm") #安装包“ggm”
library(ggm) #调用包“ggm”
s<-cov(mydata) #计算协方差
r<-pcor(c(2,3,1),s) #计算偏相关系数
n<-dim(mydata)[1] #计算样本量
pcor_test<-pcor.test(r,1,n) #偏相关系数显著性检验
cor_test<-cor.test(mydata$Hcy,mydata$X24hSSD) #计算相关系数显著性
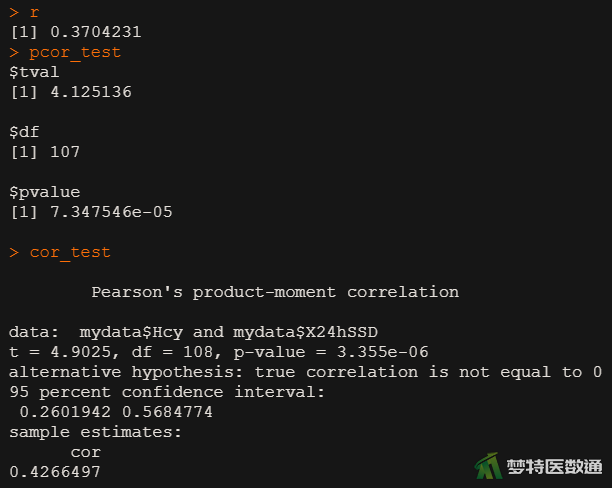
r #显示偏相关系数
pcor_test #显示偏相关系数P值
cor_test #显示相关系数及其P值
2. 结果解读
(1) 统计描述
从图8的“describe (描述性分析)”可知,高血压患者的同型半胱氨酸水平为12.65±3.65μmol/L,24小时收缩压标准差为10.84±1.9mmHg,尿酸为373.50±94.16 μmol/L。
(2) 统计学推断
由图9的结果可知,当不控制尿酸“UA”时,“Hcy”和“X24hSSD”之间的相关系数r =0.426,P<0.001。即同型半胱氨酸和24小时收缩压标准差相关性中等,且有统计学意义。当控制尿酸“UA”时,“Hcy”和“X24hSSD”之间的偏相关系数r =0.370,P<0.001。即同型半胱氨酸和24小时收缩压标准差相关性水平稍有降低,但仍有统计学意义。
四、结论
本研究采用Pearson偏相关分析判断在控制高血压患者的尿酸水平时,患者同型半胱氨酸水平和24小时收缩压标准差是否有关。已知两个变量均为连续变量,样本独立,且两个变量及需要控制的变量分别来自同一个体;通过Q-Q图和正态性检验发现两个变量服从正态分布;通过箱线图及专业知识判断,数据不存在需要处理的异常值;通过散点图发现,两个变量之间存在线性关系。
描述性分析结果显示,高血压患者的同型半胱氨酸水平为12.65±3.65 μmol/L,24小时收缩压标准差为10.84±1.90 mmHg,尿酸为373.50±94.16 μmol/L。Pearson偏相关分析结果显示,高血压患者在不控制尿酸时,同型半胱氨酸和24小时收缩压标准差之间的相关系数r =0.427,P<0.001,控制尿酸时,同型半胱氨酸和24小时收缩压标准差之间的偏相关系数r =0.370,P<0.001。综上,高血压患者同型半胱氨酸和24小时收缩压标准差呈正相关。
五、分析小技巧
(一) 偏相关分析
- 偏相关分析也称净相关分析,是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析要探索的两变量间的相关程度的过程。当控制变量个数为1时,偏相关阶数为1;当控制变量个数为2时,偏相关阶数为2。偏相关分析包括Pearson偏相关性分析(适用于正态分布的计量资料)、Spearman偏相关性分析(适用于非正态分布的计量资料或总体分布未知的变量)和Kendall's tau-b偏相关性分析(适用于等级资料)。
(二) 偏相关系数
- 偏相关系数和简单相关系数的区别在于前者进行了变量控制;共同点在于两者都是表示两个随机变量之间线性相关程度和方向的统计量。r>0,为正相关;r<0,为负相关。r的绝对值大小表示两变量之间线性相关的密切程度。一般当0.9</r/<1,为高度相关;当0.7</r/<0.9,为强相关;0.4</r/<0.7,为中度相关;0.2</r/<0.4,为弱相关性;0</r/<0.2,为极弱相关或无相关性。但相关系数强弱的判断标准,对于不同专业存在差异,使用时需要结合专业背景综合决定。