在前面文章中介绍了泊松回归分析(Poisson Regression Analysis)的假设检验理论,本篇文章将实例演示在SAS软件中实现泊松回归分析的操作步骤。
关键词:SAS; 泊松回归; Poisson回归; 等离散
一、案例介绍
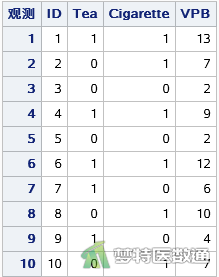
某临床医师对39名有胸闷症状的非器质性心脏病男性患者的24小时早搏数进行了临床研究记录,每个患者的研究影响因素包括是否喝浓茶、是否吸烟。请利用该资料对24小时早搏数的影响因素进行分析。部分数据见图1。本文案例可从“附件下载”处下载。Tea表示是否喝浓茶(0为不喝浓茶,1为喝浓茶);Cigarette表示是否吸烟(0为不吸烟,1为吸烟);VPB表示24小时早搏数。
二、问题分析
本案例的分析目的是了解有胸闷症状的非器质性心脏病男性患者24小时早搏数的影响因素。了解单位时间、单位面积或单位空间内某事件发生数的影响因素,可以考虑使用Poisson回归分析。但需要满足以下6个条件:
条件1:观察变量为计数变量。本研究中心脏病男性患者的24小时早搏数为计数变量,该条件满足。
条件2:观察变量的发生相互独立。本研究中各研究对象的每次早搏事件发生都是独立的,不存在互相干扰的情况,该条件满足。
条件3:至少有1个自变量,可以是分类变量,也可以是连续变量。本研究中有两个分类自变量,分别为是否喝浓茶和是否吸烟,该条件满足。
条件 4:观察变量不存在显著的异常值,该条件需要通过软件分析后判断。
条件5:观察变量服从Poisson分布,即满足等离散性,表现为计数值的平均值(近似)等于方差。该条件可以通过数据特征进行初步判断,本研究的观察变量为心脏病男性患者24小时早搏数(计数资料),从专业知识可知,早搏发生频数较低,各单位时间内的发生情况相互独立,基本满足Poisson分布的条件。同时还也可以结合软件分析进行判断。
条件6:自变量之间无多重共线性。该条件需要通过软件分析后判断。
三、软件操作及结果解读
(一) 适用条件判断
1. 条件4判断(异常值检测)
(1) SAS实现
首先导入数据,代码如下所示:
proc import datafile="G:\泊松回归---SAS实现\案例数据-possion回归.xlsx" dbms=xlsx out=data1 replace; run;
使用如下的proc univariate过程步,可以获得VPB变量每一组的描述性统计量(均值、标准差、最大最小值等)、绘制箱线图等结果:
proc univariate data=data1 plot; var VPB; run;
(2) 结果解读
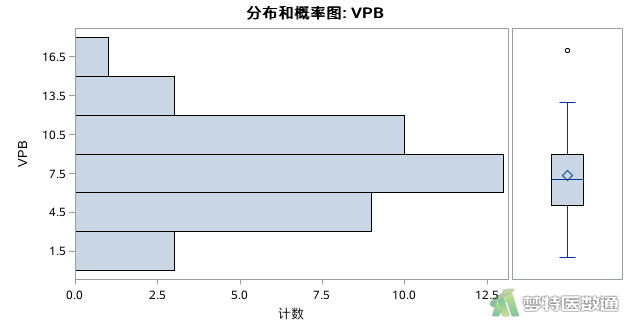
如图2所示,VPB(24小时早搏数)的最大值和最小值分别是17和1,图3的箱线图提示存在一个异常值17, 依据专业可判定该值可以保留。综上,本案例未发现需要处理的异常值,满足条件4。

2. 条件5判断(Poisson分布检验)
(1) SAS实现
proc univariate data=data1; var VPB; run;
(2) 结果解读
如图4所示,VPB(24小时早搏数)的均值为7.308,方差为10.692,可以认为均值和方差基本相等,提示服从Poisson分布,满足条件5。

3. 条件6判断(多重共线性诊断)
(1) SAS实现
使用线性回归过程步进行多重共线性诊断:
proc reg data=data1; model VPB=Tea Cigarette/tol vif; quit;
(2) 结果解读
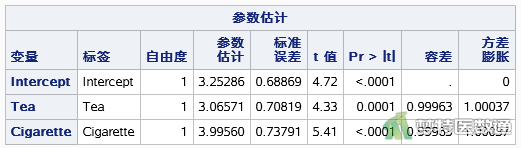
如图5所示,所有自变量的方差膨胀因子均<10,容忍度均>0.1,提示自变量之间不存在严重共线性问题,满足条件6。
(二) 模型拟合
1. SAS实现
使用proc genmod过程步进行Poisson回归,代码如下所示:
proc genmod data=data1; class Tea(param=reference ref="0"); class Cigarette(param=reference ref="0"); model VPB=Tea Cigarette/dist=poisson link=log type1 type3; ods output ParameterEstimates=PE; run; data OR; set PE; OR = exp(Estimate); LCI = exp(LowerWaldCL); UCI = exp(UpperWaldCL); keep Parameter OR LCI UCI; proc print; run;
class选项对分类变量设置参照,本例分别以不喝浓茶、不吸烟为参照。Dist指定分布为Poisson分布;link指定连接函数为log;type1和type3输出似然比的1型和3 型结果。ods output语句将模型参数估计值输出到PE数据集,用于计算OR值。
2. 结果解读
(1) 变量信息
如图6所示,该模型中Tea和Cigarette均为二分类变量。

(2) 拟合优度检验
如图7所示,模型AIC为176.7650,AICC为177.4507,BIC为181.7557。

如图8所示,1型和3型似然比检验的结果均表明,喝浓茶和不喝浓茶的早搏数差异有统计学意义(1型似然比检验χ²=11.98,P=0.0005;3型似然比检验χ²=12.57,P=0.0004)。1型和3型似然比检验的结果均表明,吸烟和不吸烟的早搏数差异有统计学意义(1型似然比检验χ²=20.91,P<0.0001;3型似然比检验χ²=20.91,P<0.0001)。

(3) 参数估计
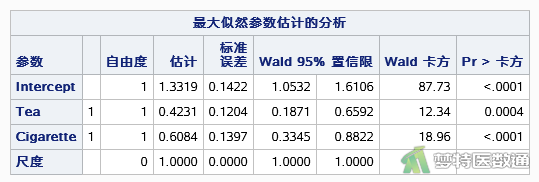
如图9所示,Tea的参数估计值为0.4231,Cigarette的参数估计值为0.6084,表明喝浓茶与吸烟对24小时早搏数均有正向影响。
如果用Y表示早搏数,用X1表示是否喝浓茶,X2表示是否吸烟,可以得到模型的公式为:
Log(Y)=1.3319+0.4231*X1+0.6084*X2
如图10所示,喝浓茶的患者早搏的概率是不喝浓茶患者的1.52672倍(95%CI:1.20573~1.93317;P=0.0004),吸烟的患者早搏的概率是不吸烟患者的1.83741倍(95%CI:1.39729~2.41615;P<0.0001)。
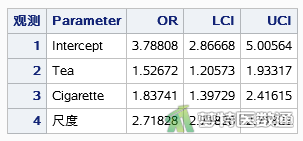
四、结论
本研究采用Poisson回归分析胸闷症状的非器质性心脏病男性患者24小时早搏数的影响因素。
结果显示,喝浓茶和不喝浓茶的早搏数差异有统计学意义(1型似然比检验χ²=11.98,P=0.0005;3型似然比检验χ²=12.57,P=0.0004)。吸烟和不吸烟的早搏数差异有统计学意义(1型似然比检验χ²=20.91,P<0.0001;3型似然比检验χ²=20.91,P<0.0001)。喝浓茶的患者早搏的概率是不喝浓茶患者的1.52672倍(95%CI:1.20573~1.93317;P=0.0004),吸烟的患者早搏的概率是不吸烟患者的1.83741倍(95%CI:1.39729~2.41615;P<0.0001)。
五、知识小贴士
(一) Poisson分布
- 人类稀有疾病或一些卫生事件,如恶性肿瘤、某地在一个月内因交通事故死亡人数、1ml水中大肠杆菌数等计数资料,具有发病率低或者不像二项分布资料有分母能计算比例等特点。因此,这些事件数的多少除了取决于事件的实际发生数,还取决于计数时研究者所观察的范围,即观察多长时间、多大人群、多大面积等。使用发病密度等密度指标描述这些事件的群体特征比较合适。对于此类罕见事件的发生,如果事件之间彼此相互独立,观察样本含量较大时,则具有平均计数等于方差的特点。这类事件的发生次数往往服从Poisson分布
(二) Poisson回归
- Poisson回归主要用于单位时间、单位面积、单位空间内某事件发生数的影响因素分析。在进行稀有事件等计数资料的影响因素分析时,应首先对资料的过离散情况进行判断或检验分析,然后选择正确的回归模型分析,才能得到正确的结果。一般先从专业方面判断,然后用统计学方法检验资料是否存在过离散现象。如果资料存在过离散情况,选用负二项回归模型;如果资料无过离散情况,选用Poisson回归模型分析。Poisson回归和多重线性回归、Logistics回归、Cox比例风险模型、负二项回归等都是医学领域中应用最多的广义线性模型之一。
- Poisson回归要求样本总体均数和总体方差相等,但是在实际分析问题过程中,常会出现方差大于均数的情况,即所谓的“过离散现象”,这会导致模型参数估计值的标准误偏小,参数检验的假阳性增加,此时宜选用负二项分布进行分析。