在前面文章中介绍了负二项回归分析(Negative Binomial Regression Analysis) 的假设检验理论(链接),本篇文章将实例演示在SAS软件中实现负二项回归分析的操作步骤。
关键词:SAS; 负二项回归; 过离散; overdisp
一、案例介绍
某市抽样调查了146名学生某一学年的缺课天数(Days),同时收集了他们的民族(Race;1=汉族,2=少数民族)、性别(Sex;1=男,2=女)、年龄(Age;1=10-12岁,2=8-10岁,3=6-8岁,4=小于6岁)和学习状况(Study;1=良好,2=一般)等信息,拟探究上述因素对学生缺课天数的影响。部分数据见图1。本文案例可从“附件下载”处下载。
二、问题分析
本案例的分析目的是研究民族、年龄、性别、学习状况等对学生年缺课天数的影响。因变量为计数资料,服从Poisson分布或负二项分布,可以尝试使用负二项回归分析。但需要满足5个条件:
条件1:因变量为计数变量。本案例的因变量为年缺课天数,为计数变量,满足条件。
条件2:至少有1 个自变量,可以是分类变量,也可以是连续变量。本案例有民族、年龄、性别、学习状况共4个自变量,满足该条件。
条件3:各观测行间是非独立的,事件的发生有空间聚集现象;或因变量存在过离散现象,即方差远大于均数。由研究设计可知,学生缺课天数无空间聚集现象,但过离散现象可能存在,可通过软件分析后判断。
条件4:自变量之间无多重共线性。该条件需要通过软件分析后判断。
条件5:自变量不存在显著的异常值。由于本研究所分析的自变量为分类变量,暂不用查看异常值。
三、软件操作及结果解读
(一) 导入数据
①利用LIBNAME语句建立SAS逻辑库关联,注意逻辑库名称要求,即最大长度8字符,必须以字母或下划线“_”开始,可以是字母、数字和下划线的任意组合。具体代码如下:
libname mydata 'D:\mydata';
通过这一步骤,SAS能够识别引号中的物理位置,将逻辑库建立在该目录下,同时在以下过程中新建的SAS表格便可以永久储存在该位置,便于反复读取和使用。先运行该代码使其生效。
②利用PROC IMPORT语句导入文件,代码如下:
proc import out= mydata.example datafile=" D:\mydata\负二项回归.csv" dbms=csv replace; getnames=yes; run;
该过程在mydata逻辑库中生成example数据集,数据文件由DATAFILE=选项指定,DBMS=选项指定其数据库类型。该案例中初始数据集为csv文件,故而使用“dbms=csv”指定。如果已经存在相同名称的SAS数据集,即可使用REPLACE选项进行覆盖。GERNAMES=YES选项指定从第2行开始读取数据,将数据集的首行变量名作为SAS数据集的变量名。
(二) 适用条件判断
1. 条件3判断(过离散检验)
对于过离散现象的判断,需要先拟合Poisson回归。若Poisson回归中的过离散判断指标(Chi-square Value/df)值>3,则认为计数因变量存在过离散现象。
(1) 软件操作
运用GENMOD过程进行分析,具体过程如下所示:
proc genmod data = mydata.example; model days = Race Sex Age Study / link=log dist=Poisson; run;
该过程中MODEL语句指定“Days”为因变量,“Race” “Sex” “Age”和“Study”进入模型,“link=log”计算因变量的对数,“dist=Poisson”指定Poisson回归。
(2) 结果解读
由图2中的“Pearson Chi-square”的“Value/DF”可知,该值为14.1145>3,表示计数因变量存在过离散现象,数据满足条件3.。本案例也可计算因变量Days的均值为16.459,方差为264.167,方差远大于均数,也提示因变量存在过离散现象。

2. 设置哑变量
容忍度(Tolerance)或方差膨胀因子(VIF)可以用来诊断自变量之间的多重共线性。进行线性回归的共线性诊断前需要对多分类变量设置哑变量,以下将对多分类变量“Age”进行哑变量设置。
(1) 软件操作
运用DATA步骤新建哑变量。具体代码如下所示:
data mydata.example2; set mydata.example; if Age=2 then Age_1=1; else Age_1=0; if Age=3 then Age_2=1; else Age_2=0; if Age=4 then Age_3=1; else Age_3=0; run;
该步骤新建表格“mydata.example2”,在原表中加入新建的哑变量“Age_1” “Age_2” “Age_3” 。
(2) 结果解读
上述步骤运行结束后可以在“mydata.example2”看到新生成的3个哑变量(图3),随后就可以进行多重共线性诊断。
3. 条件5判断(多重共线性诊断)
(1) 软件操作
运用REG过程进行检验,具体代码如下所示:
proc reg data= mydata.example2;
model days = Race Sex {Age_1 Age_2 Age_3} Study / tol vif;
run;
该步骤以新表“mydata.example2”为对象,MODEL语句将“days”作为因变量,将“Race”“Sex”“Study”和“Age”的四个哑变量纳入模型。Tol选项计算“Tolerance(容忍度)”,vif选项计算“VIF(方差膨胀因子)”。
(2) 结果解读
如果“Tolerance(容忍度)”小于0.1或“VIF(方差膨胀因子)”大于10,则提示有严重共线性存在。本例中(图4),容忍度均远大于0.1,方差膨胀因子均小于10,提示自变量之间不存在严重多重共线性。如果数据存在严重多重共线性,需用复杂的方法进行处理,其中最简单的是剔除引起共线性的因素之一,剔除哪一个因素可以基于理论依据。满足条件5。
(三) 统计描述及推断
1. 软件操作
①用FREQ步骤计算分类变量的统计描述结果,具体代码如下:
proc freq data = mydata.example2; tables Race Sex Age Study; run;
②用MEANS步骤计算连续变量的统计描述结果,具体代码如下:
proc means data = mydata.example2; var days; run;
③用GENMOD步骤进行负二项回归分析,具体代码如下:
proc genmod data = mydata.example2 ; class Race(param=reference ref="1"); class Sex(param=reference ref="1"); class Study(param=reference ref="1"); class Age_1(param=reference ref="0"); class Age_2(param=reference ref="0"); class Age_3(param=reference ref="0"); model days = Race Sex Age_1 Age_2 Age_3 Study / dist=negbin link=log type1 type3; ods output ParameterEstimates=mydata.PE; run; data mydata.OR; set mydata.PE; OR = exp(Estimate); LCI = exp(LowerWaldCL); UCI = exp(UpperWaldCL); keep Parameter Level1 OR LCI UCI; proc print; run;
其中“dist= negbin”指定负二项回归(Negative Binomial Regression)的分析方法,“link=log”同样计算因变量的对数,type1和type3输出似然比的1型和3 型结果。ods output语句将模型参数估计值输出到PE数据集,用于计算OR值。
2. 结果解读
图5和图6分别是对模型中的分类变量和连续变量的统计描述结果。


如图7所示,1型和3型似然比检验的结果均表明,汉族和少数民族的缺课天数差异有统计学意义(1型似然比检验χ²=11.63,P=0.0006;3型似然比检验χ²=12.52,P=0.0004)。1型和3型似然比检验的结果均表明,年龄6-8岁与10-12岁者的缺课天数差异有统计学意义(1型似然比检验χ²=6.70,P=0.0097;3型似然比检验χ²=10.24,P=0.0014)。
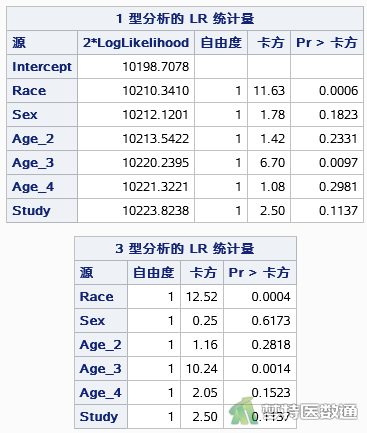
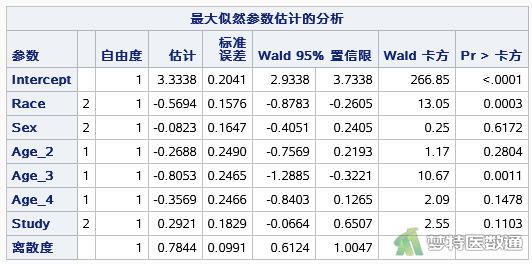
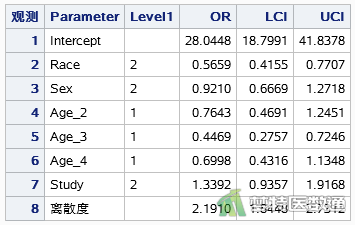
如图8所示,Race的参数估计值为-0.5694,Age_3的参数估计值为-0.8053。如图9所示,与汉族相比,少数民族学生缺课的发生率是汉族学生的0.5659倍(IRR=0.5659, 95%CI:0.4155-0.7707, P=0.0003),关联有统计学意义。年龄6-8岁与10-12岁者相比,缺课的发生率下降了0.5531倍(IRR=0.4469,95%CI:0.2757-0.7246,P=0.0011),关联有统计学意义。
四、结论
本研究采用负二项回归探究民族、性别、年龄和学习状态对学生年缺课天数的影响。通过Poisson回归的过离散指标可知,因变量存在过离散现象;通过共线性诊断可知,变量间不存在严重的多重共线性,满足负二项回归的条件。
由负二项回归分析的结果可知,民族和年龄在模型中有统计学意义,与学生年缺课天数相关。其中,少数民族学生缺课的发生率是汉族学生的0.5659倍(IRR=0.5659, 95%CI:0.4155-0.7707, P=0.0003);年龄6-8岁的与10-12岁的相比,缺课的发生率下降了0.5531倍(IRR=0.4469,95%CI:0.2757-0.7246,P=0.0011)。
五、知识小贴士
- Poisson回归与负二项回归
Poisson回归的应用条件之一是计数因变量服从Poisson分布,即因变量的平均值等于方差。但,很多事件的发生是非独立的,如传染性疾病、地方病、遗传病等,单位时间/空间内事件发生频数的方差远远大于平均值,即存在过离散现象。若用Poisson回归来分析这些事件的影响因素,会导致模型参数估计值的标准误偏小,参数检验的假阳性率增加。这时候宜选择负二项回归进行分析。
- 与线性回归的重要区别
①因变量的变量类型:Poisson回归/负二项回归的因变量为单位时间/空间发生的事件数,为服从Poisson分布或负二项分布计数资料;一般线性回归的因变量为服从正态(高斯)分布计量资料,如BMI、尿量等。
②在广义线性模型中,Poisson回归/负二项回归的连接函数为ln,即对方程左侧取对数;而线性回归的为恒等函数,不需要任何变换,直接等于右侧的线性组合。
- IRR的含义
IRR,为Incidence rate ratio的缩写,译为发病率的比值,是暴露组与非暴露组事件发生率的比值。当IRR>1时,说明暴露增加了事件发生的可能性;当IRR=1,说明暴露与事件的发生无关联;当IRR<1,说明暴露降低了事件发生的可能性。