在前面文章中介绍了二分类logistic回归分析(Binomial Logistic Regression Analysis)的假设检验理论,本篇文章将实例演示在Stata软件中实现二分类logistic回归分析的操作步骤。
关键词:Stata; 二分类logistic回归; 二项logistic回归; 二元logistic回归; 逻辑回归; EPV原则
一、案例介绍
探讨经皮内镜下腰椎间盘摘除术治疗腰椎间盘突出疗效不佳的主要影响因素,纳入146例治疗效果“不佳”(记录为1)的患者,278例治疗效果“良好”(记录为0)的患者,并收集其余变量信息。其余变量及编码为性别(0=女,1=男)、年龄(0=60岁以下,1=60岁及以上)、手术时间(min)、突出部位(1=单侧,2=中央,3=极外侧)、突出分类(1=膨出型,2=突出型,3=脱垂型)、Modic改变(1=I级,2=II级,3=III级)、是否钙化(0=未钙化,1=钙化)、矢状径(cm)、退变级别(1=I-III级,2=IV级,3=V级)。部分数据见图1。本文案例可从“附件下载”处下载。
二、问题分析
本案例的分析目的是探讨经皮内镜下腰椎间盘摘除术治疗腰椎间盘突出疗效不佳的主要影响因素,由于因变量是二分类变量,因此可以使用二分类logistic回归分析。但需要满足7个条件:
条件1:因变量为二分类变量。本研究中因变量是治疗效果“不佳”和“良好”,为二分类变量,该条件满足。
条件2:至少有1个自变量。自变量可以是分类变量也可以是连续变量。本研究中有多个自变量,类型各异,该条件满足。
条件3:各观测行间相互独立。对研究设计和数据收集的过程进行分析,可判断本案例中观测值之间不存在互相影响的情况。
条件4:例数较少类的因变量例数为自变量个数的10~15倍(EPV原则),且经验上两组的人数最好>30例,参照水平组不应少于30或50例。该条件需要通过软件分析后判断。
条件5:自变量之间无多重共线性。该条件需要通过软件分析后判断。
条件6:自变量不存在显著的异常值。该条件需要通过软件分析后判断。
条件7:数据未出现完全分离或拟完全分离现象。该条件需要通过软件分析后判断。
三、软件操作及结果解读
(一) 适用条件判断
1. 条件4判断(因变量样本例数)
(1) 软件操作
*计算因变量中例数较少类的样本例数*
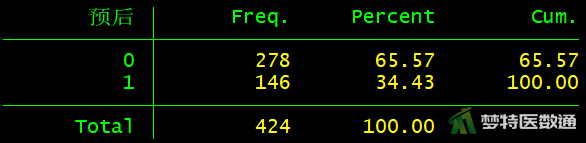
tab 预后
(2) 结果解读
由图2“预后频率表”可见,预后不佳为146例,预后良好为278例。根据“例数较少类的因变量例数为自变量个数的10~15倍(EPV原则)”,本案例可纳入10~15个自变量进行多因素二分类logistic回归分析。
2. 条件4判断(自变量样本例数)
(1) 软件操作
*逐一计算分类变量各类别的因变量例数*
tab 预后 性别

tab 预后 年龄
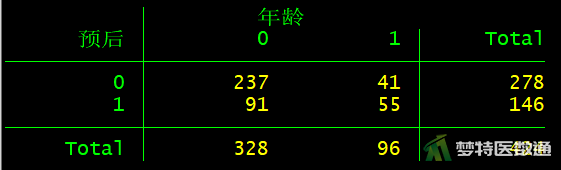
tab 预后 突出部位
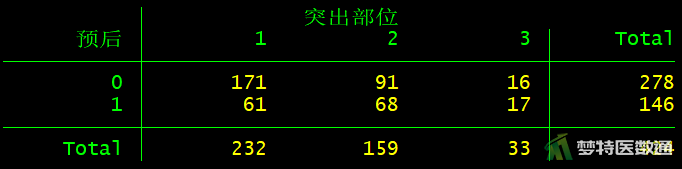
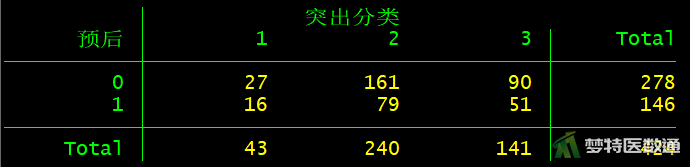
tab 预后 突出分类
tab 预后 Modic改变

tab 预后 是否钙化

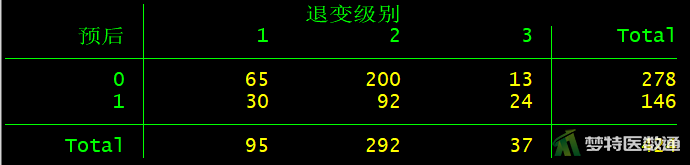
tab 预后 退变
(2) 结果解读
由图3—图9可知,突出部位水平为“极外侧”时、突出分类水平为“膨出型”时、退变级别水平为“V级”时,因变量的例数<30,如果这些变量在多因素分析过程中进入模型,应注意避免例数较少的水平被选为参照。
3. 条件5判断(多重共线性诊断)
详见本章后文。
4. 条件6判断(异常值检测)
详见本章后文。
5. 条件7判断(完全分离检测)
完全分离,指某一个自变量本身或者某几个自变量的线性组合,对因变量的预测结果与实际情况完全一致,常表现为OR值无穷大。通过图3—图9可见并不存在这种情况。该条件满足。
(二) 变量筛选
1. 软件操作
利用单因素logistic回归分析筛选纳入后续多因素分析的自变量。
*单因素logistic回归分析*
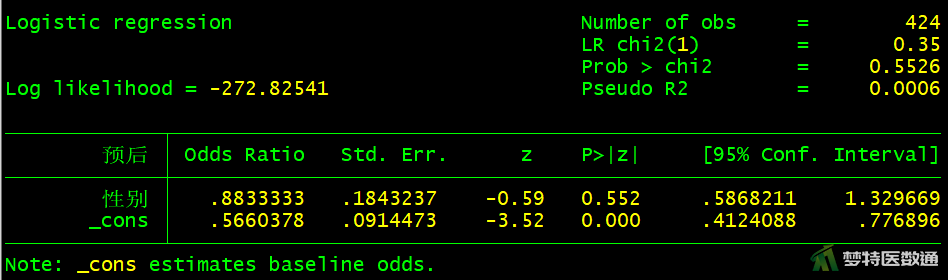
logistic 预后 性别
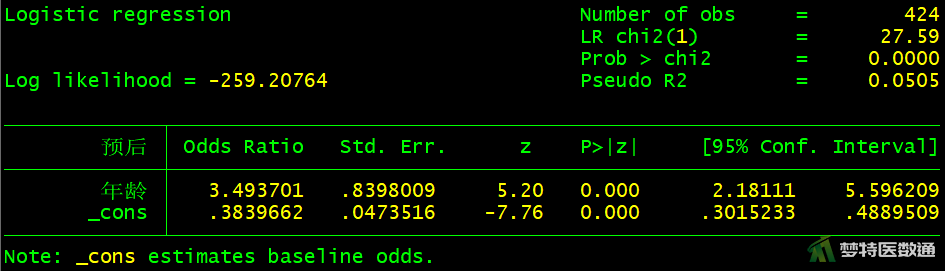
logistic 预后 年龄
logistic 预后 手术时间
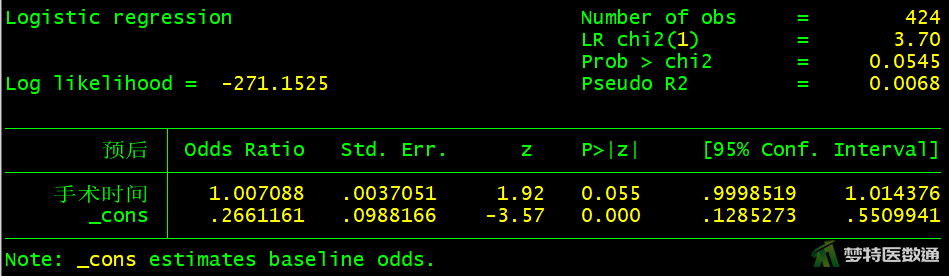
logistic 预后 i.突出部位
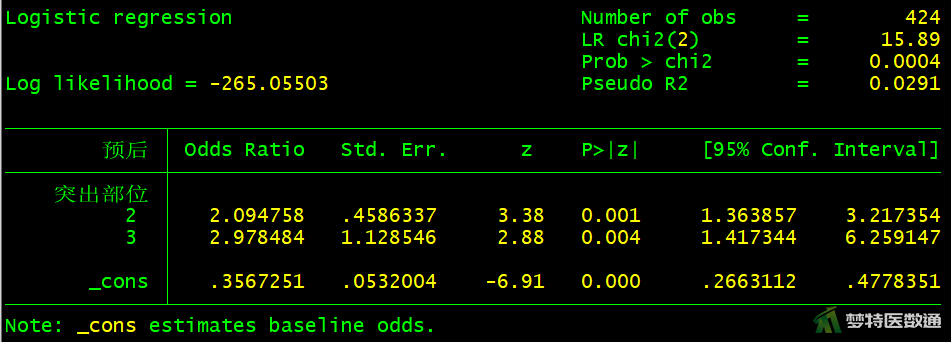
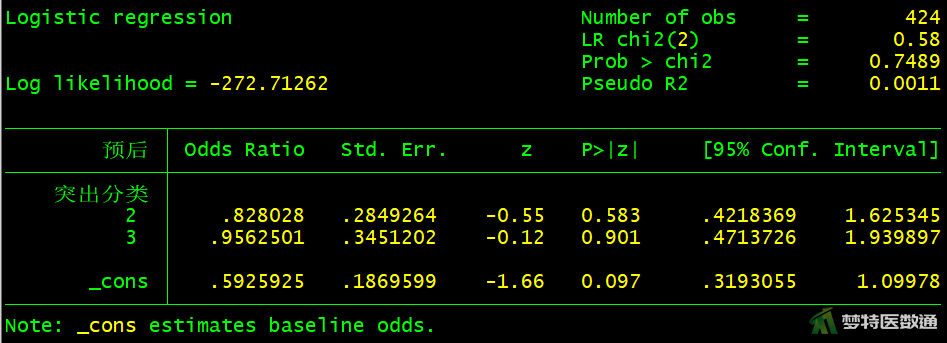
logistic 预后 i.突出分类
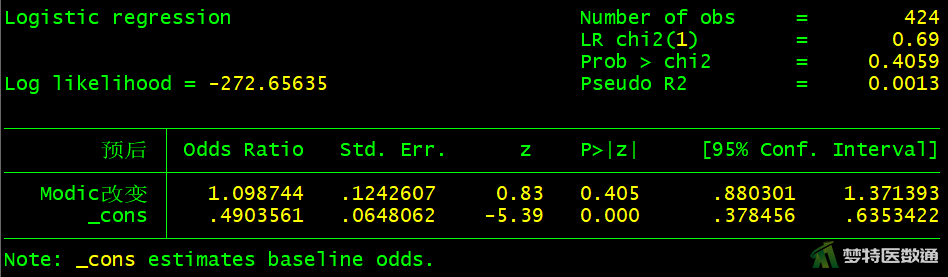
logistic 预后 Modic改变
logistic 预后 是否钙化
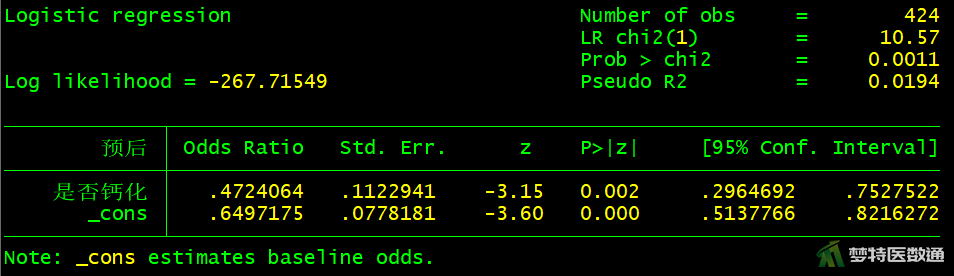
logistic 预后 矢状径
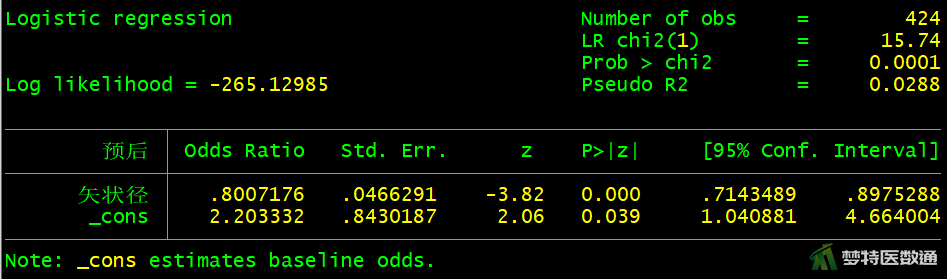
logistic 预后 退变级别
2. 结果解读
图10-图18中分别显示了每个自变量单因素分析的检验结果,可知,“性别(P=0.5526>0.05)”、“手术时间(P=0.0549>0.05)”、 “突出分类(P=0.7489>0.05)”、“Modic改变(P=0.4059>0.05)”四个变量无统计学意义,可不纳入多因素分析模型。
(三) 适用条件判断(补充)
将“性别”、“手术时间”、“突出分类”、“Modic改变”四个单因素分析无统计学意义的变量排除后,对其余变量进行多因素二分类logistic回归分析。
1. 条件5判断(多重共线性诊断)
(1) 软件操作
①*安装Collin模块*
输入
net describe collin, from(https://stats.idre.ucla.edu/stat/stata/ado/analysis)
结果如图19所示。
再输入
net install collin
如图20所示,安装完成。

*计算方差膨胀因子*
collin 年龄 突出部位 是否钙化 矢状径 退变级别
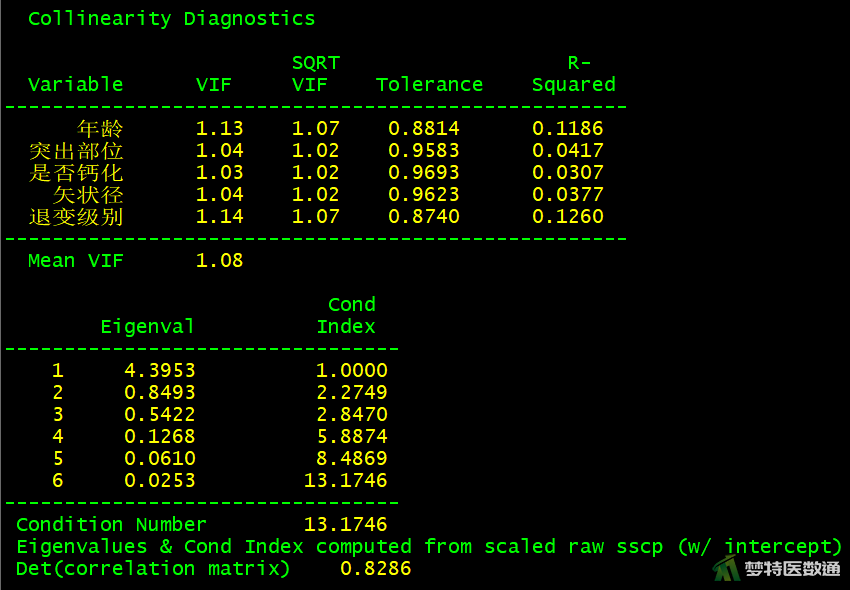
(2) 结果解读
图21结果中列出了自变量的方差膨胀因子(variance inflation factor,VIF)和容忍度(Tolerance)。可见,所有自变量的VIF均<10,容忍度均>0.1,提示自变量之间不存在严重共线性问题。
2. 条件6判断(异常值检测)
(1) 软件操作
*计算库克距离()*
quietly reg 预后 年龄 i.突出部位 ib1.是否钙化 矢状径 ib3.退变级别 predict new,cooksd sum new

(2) 结果解读
从图22可见,最大的库克距离值为0.0324<0.5,提示不存在显著异常值,本研究数据满足条件6。
(四) 模型拟合
1. 软件操作
*二分类多因素logistic回归分析*
logit 预后 年龄 i.突出部位 ib1.是否钙化 矢状径 ib3.退变级别
logistic 预后 年龄 i.突出部位 ib1.是否钙化 矢状径 ib3.退变级别
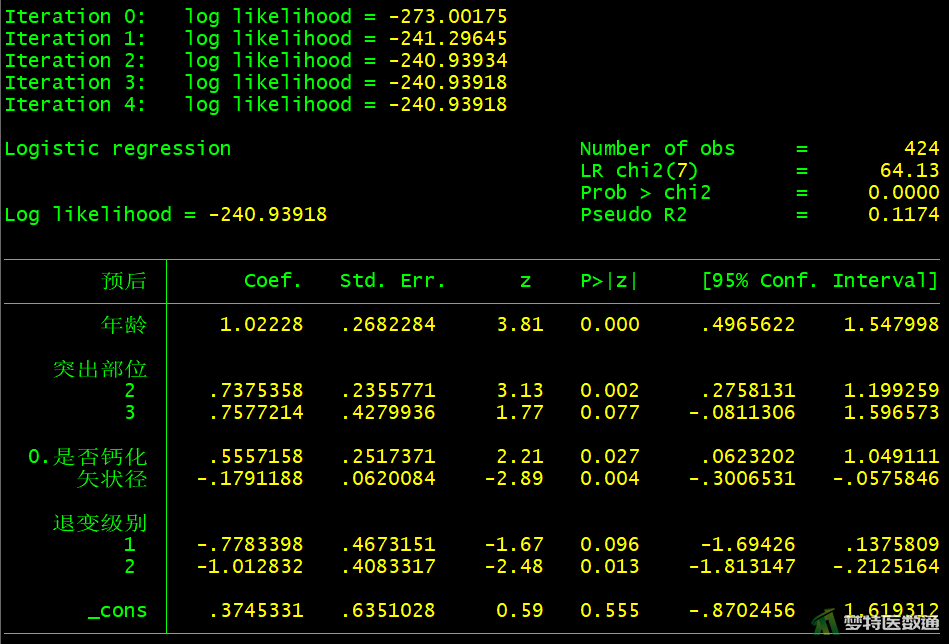
2. 结果解读
(1) 拟合优度
图23、图24中回归分析结果显示,拟合优度为平方(pseudo-R2)为0.1147。pseudo-R2越接近1说明回归方程的拟合度越高。
(2) 模型系数
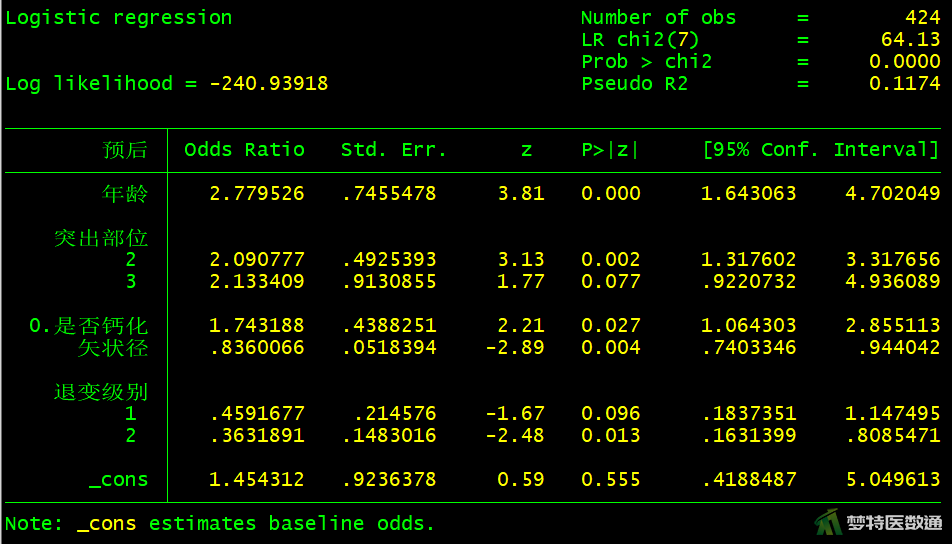
图23中“预后”模型系数列出了各自变量拟合后在模型中的“Coef(回归系数)”及其95%CI、“Std. Err. (标准误)”、“Z (统计量)”、“P (P值)”;图24中列出了“Odds Ratio (OR值)”及其95%CI。OR值为e(回归系数),如矢状径的OR=0.836=e(-0.179),表示矢状径每增加1 cm,术后效果不佳的风险降低16.4% (OR=0.836,95%CI:0.740~0.944;P=0.004)。
其他自变量结果的解释分别为,年龄60岁及以上的患者术后不佳的风险是60岁以下患者的2.779倍(95%CI:1.643~4.702;P<0.001)。突出部位为“中央”和“极外侧”的患者术后效果不佳的风险分别是“单侧”患者的2.091倍(95%CI:1.318~3.318;P=0.002)和2.133倍(95%CI:0.922~4.936;P=0.077)。“非钙化”患者术后不佳的风险是“钙化”患者的1.743倍(95%CI:1.064~2.855;P=0.027)。与退变级别为“V级”的患者相比,“I-III级”患者术后效果不佳的风险降低54.1% (95%CI:0.184~1.147;P=0.096);“IV级”患者术后效果不佳的风险降低63.7% (95%CI:0.163~0.809;P=0.013)。
(五) 预测价值
1. 软件操作
①*分类统计量和分类表*
estat classification
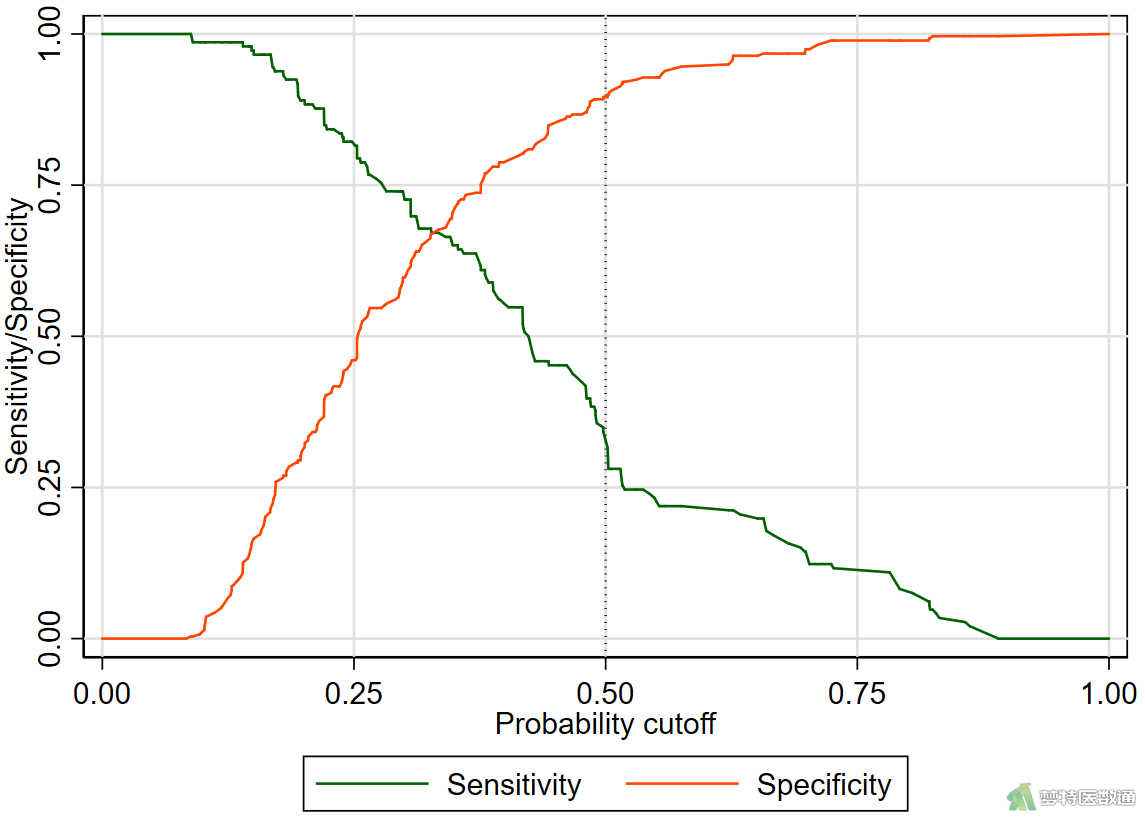
②*绘制预测概率对灵敏度和特异分割图*
lsens, recast(line) xline(0.5, lpattern(dot) lcolor(black))
③*绘制ROC曲线*
lroc, recast(line) lcolor(red) rlopts(lcolor(black))
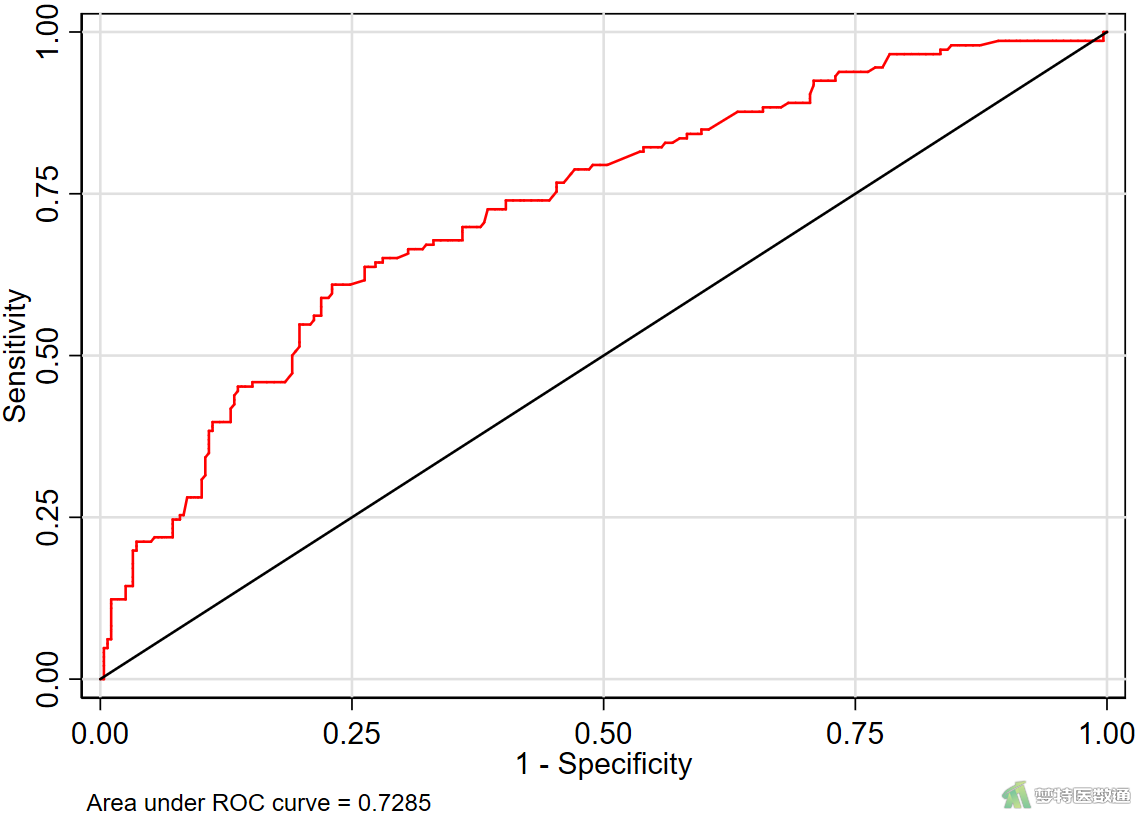
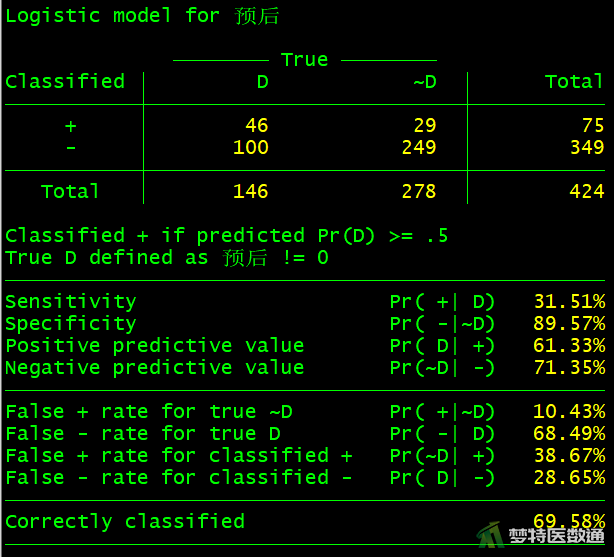
2. 结果解读
图25显示了自变量对因变量正确分类的“Accuracy (准确性)”、“Specificity (特异度)”、“Sensitivity (灵敏度)”和“AUC (ROC曲线下面积)”,可见进入模型的5个变量对因变量正确分类的准确性为69.58%,灵敏度为31.51%、特异度为89.57%,ROC曲线下面积为72.85%,该模型的判断效果一般。
四、结论
本研究采用二分类Logistic回归探讨经皮内镜下腰椎间盘摘除术治疗腰椎间盘突出疗效不佳的主要影响因素。因变量例数分布满足样本量需求,变量之间不存在严重共线性和异常值,数据不存在完全分离现象。
九个自变量经过分析后,最终有5个(矢状径、年龄、突出部位、是否钙化和退变级别)进入模型,其中矢状径每增加1 cm,术后效果不佳的风险降低16.4% (OR=0.836,95%CI:0.740~0.944;P=0.004);年龄60岁及以上的患者术后不佳的风险是60岁以下患者的2.780倍(95%CI:1.643~4.702;P<0.001);突出部位为“中央”和“极外侧”的患者术后效果不佳的风险分别是“单侧”患者的2.091倍(95%CI:1.318~3.318;P=0.002)和2.133倍(95%CI:0.922~4.936;P=0.077);“非钙化”患者术后不佳的风险是“钙化”患者的1.743倍(95%CI:1.064~2.855;P=0.027);与退变级别为“V级”的患者相比,“I-III级”患者术后效果不佳的风险降低54.1% (95%CI:0.184~1.147;P=0.096);“IV级”患者术后效果不佳的风险降低63.7% (95%CI:0.163~0.809;P=0.013)。所建立的模型有统计学意义(χ²=64.125,P<0.001),对因变量正确分类的准确性为69.6%,灵敏度为31.5%、特异度为89.6%,ROC曲线下面积为72.85%,该模型的判断效果一般。
五、多重共线性的判断及处理
- 多重共线性是指自变量间存在线性相关关系,容忍度越小、VIF越大,表明共线性越强。实际数据分析过程中,若容忍度<0.2或VIF>5则表明存在较强共线性,若容忍度<0.1或VIF>10则表明存在严重共线性问题。
- 在实际数据分析过程中,若存在以下情况,则暗示模型可能存在共线性问题:①整个模型的检验结果为P值≤检验水准a,但各自变量的偏回归系数检验结果却为P值>检验水准a。②专业上认为应该有统计学意义的自变量,检验结果确无统计学意义。③自变量的偏回归系数的取值大小甚至符号明显与实际情况相违背,难以解释。④增加或删除一个自变量或一个案例,自变量偏回归系数发生较大变化。
- 自变量若存在严重多重共线性,可采取以下措施进行处理:①基于专业知识直接确认优先选择哪些变量进入模型,而将相对次要的共线性变量从模型中剔除。②逐步回归,但是当共线性比较严重时,变量自动筛选的方法并不能完全解决问题。③岭回归/lasso回归,为有偏估计,但能有效地解决共线性问题。④主成分回归法,这种方法的代价是在提取主成分时会丢失一部分信息,收益则是大大降低了共线性对参数估计值的扭曲,而且自变量间的多重共线性越强,提取主成分时丢失的信息就越少。
- 需要注意的是,多重共线性的存在不一定必然影响模型的使用价值,其理论上共线性不应当降低模型的预测效果,其影响主要是使模型的偏回归系数发生改变,从而无法得到专业上合理的解释。
六、自变量进入模型的形式
- 无序多分类自变量需要以哑变量形式进入模型,在SPSS中通过选择参照水平实现哑变量的设置,但需要注意以下事项:①参照水平要具有实际意义,否则会失去比较的目标,如“其他”一般不适宜做参照水平。②参照水平应有一定的例数(不低于30或50例),否则将导致与其比较的其他组的置信区间较大。③哑变量整体分析无统计学意义时,所有哑变量都不用再纳入模型;整体分析有统计学意义时,尽管有些哑变量无统计学意义,但仍需要纳入模型,即“同进同出”原则。
- 有序多分类自变量进入模型有多种方式备选,但应选择最具合理性的方式:①直接以计量资料形式带入模型:此时得到的模型较为简洁,也容易解释。但应用的前提是自变量的每个水平对因变量的影响作用基本一致,可通过观察哑变量各水平的回归系数值是否存在等级变化关系进行判定。建议先将有序多分类资料分别以哑变量和连续变量的形式引入模型,观察每个哑变量的回归系数间是否存在等级关系,并对两个模型进行似然比检验,如果似然比检验无统计学意义,且每个哑变量的回归系数间存在等级关系,则可以将该自变量以连续变量形式引入模型,否则还是采用哑变量的方式引入模型。②设置哑变量:参照无序多分类资料。③当有序多分类变量的等级水平与因变量结局不成线性关系时,应采用最优尺度回归探讨效应拐点。
- 定量资料进入模型有多种方式备选,但也应选择最具合理性的方式:如果某计量资料能以计量形式进入模型(有统计学意义),那么转化后应当同样能进入模型,且OR值会显著增加。①直接带入模型,尽管此种方法较为简单,但仍不做首选推荐。因为此时得出的OR值一般较小,即自变量变化一个单位对结局风险的影响其实是有限的,不能贴近专业解释。 如果资料分布严重失衡时(非均匀分布)尤其不能直接带入模型。但以计量资料形式直接进入模型往往模型的拟合效果较好。②根据专业意义降维后(如根据BMI指数分级标准降维为有序多分类资料),参照有序多分类资料或者二分类资料处理方式。③如果没有专业划分标准,可以资料分布形式根据四分位数间距或等分法降维或者标准化后按Per 1 sd (每一个标准差)降维。④建立自变量和因变量之间的ROC曲线,根据约登指数进行二分类降维。⑤中位数(非正态分布)或者均数(近似正态或正态分布)降维。⑥当自变量的单位不合适导致因变量的风险改变很小时,可对自变量采取缩小(如除以100)或扩大(如乘以10)相应倍数的方式。
七、自变量的选择策略
关于自变量是否纳入多因素分析模型除了根据本章节介绍的判定方法以外,还可采取以下策略:
- 专业原则:首先需要考虑的就是专业原则,这一点最为重要。如果目前专业知识有证据表明该变量与结局发生有关,那么不论该变量单因素分析结果是否有统计学意义,都应纳入多因素分析模型。
- 以单因素分析为基础:当分析的变量较多时,可先采取单因素分析方法,对有统计学意义的变量再纳入多因素分析。此时单因素分析检验水准可设置为0.1—0.2,如果样本量较大,可将检验水准设置为较为严格;如果样本量较小可将检验水准设置较为宽松。
- 比较原则:可以尝试多种方法对该变量进行分析,如采用多种自变量进入方法分析,或将计量资料降维后再分析,如果变量在多种进入方法和不同变量类型时,均能在多因素分析模型中有统计学意义,则表明该变量的确是因变量的真正影响因素。