在前面文章中介绍了多重线性回归分析(Multiple Linear Regression Analysis)的假设检验理论,本篇文章将实例演示在Stata软件中实现多重线性回归分析的操作步骤。
关键词:Stata; 多重线性回归; 多元线性回归; 多重共线性; 自变量选择; 逐步回归; 模型拟合评价; 哑变量设置
一、案例介绍
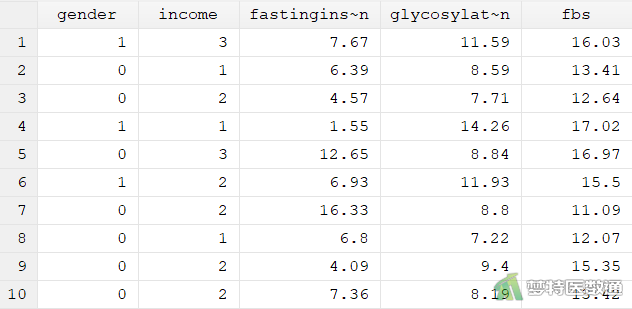
某社区医师从本社区的糖尿病患者中随机抽取50名,收集了他们的性别(Gender,0=女,1=男)、经济水平(Income,1=低收入,2=中等收入,3=高收入)、空腹胰岛素(Fasting insulin,mmol/L)、糖化血清蛋白(Glycosylated serum protein)和空腹血糖(FBS,mmol/L),欲探究空腹血糖是否受到其他几项指标的影响。部分数据见图1。本文案例可从“附件下载”处下载。
二、问题分析
本案例的目的是分析空腹血糖是否受到其他几项指标的影响,由于因变量是定量资料,初步考虑可使用多重线性回归分析。但需要满足以下7个条件:
条件1:样本量是自变量个数的5~10倍。本案例有4个自变量,样本量为50,满足该条件。
条件2:自变量若为连续变量,需要与因变量之间存在线性关系,可通过绘制散点图予以考察。
条件3:各观测值之间相互独立,即残差之间不存在自相关。通过研究设计和数据收集的过程分析,可判断本案例中观测值之间不存在互相影响的情况。该条件还可通过软件分析后辅助判断。
条件4:不存在显著的多变量异常值,该条件需要通过软件分析后判断。
条件5:自变量之间无多重共线性,该条件需要通过软件分析后判断。
条件6:残差符合正态(或近似正态)分布,该条件需要通过软件分析后判断。
条件7:残差大小不随所有变量取值水平的变化而变化,即方差齐性,可通过绘制残差图进行判断。
三、软件操作及结果解读
(一) 适用条件判断
1. 条件2判断(连续性自变量与因变量之间的线性关系)
(1) 软件操作
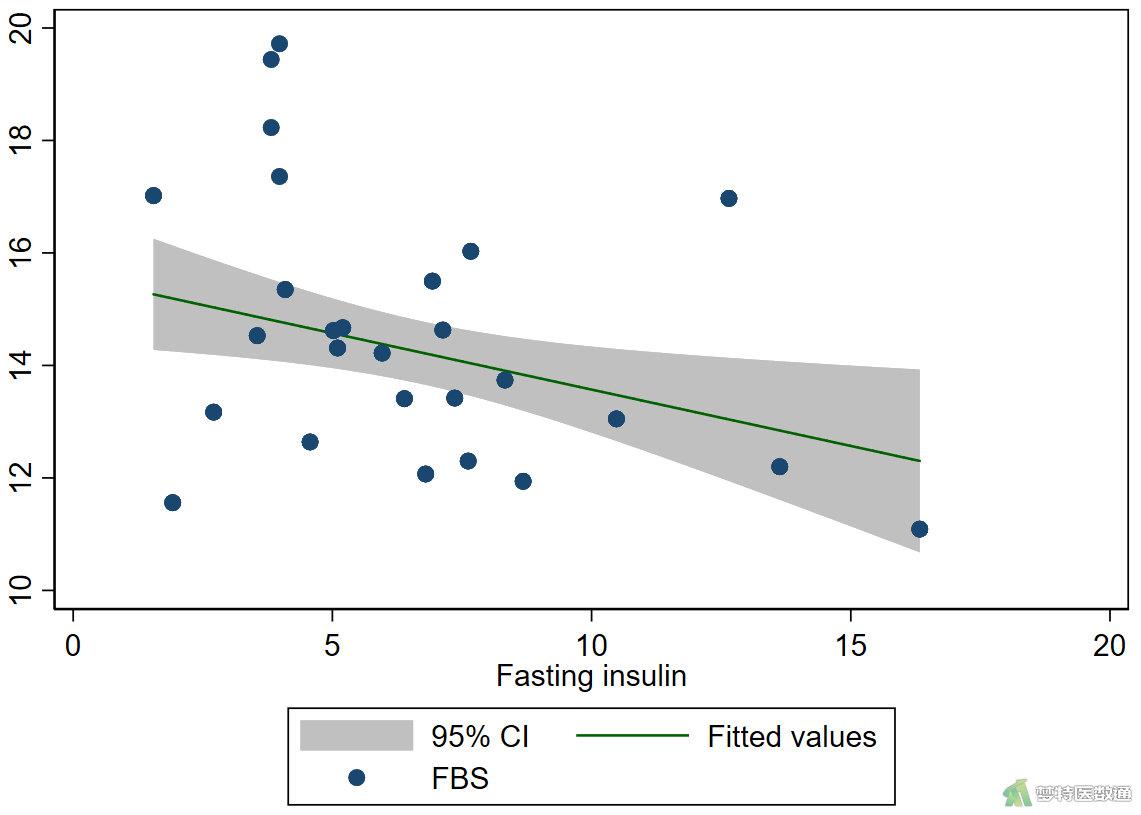
绘制散点图和带置信区间的一次拟合曲线图,结果如图2-1和图2-2所示。
*绘制fbs和fastinginsulin的散点图*
graph twoway lfitci fbs fastinginsulin || scatter fbs fastinginsulin
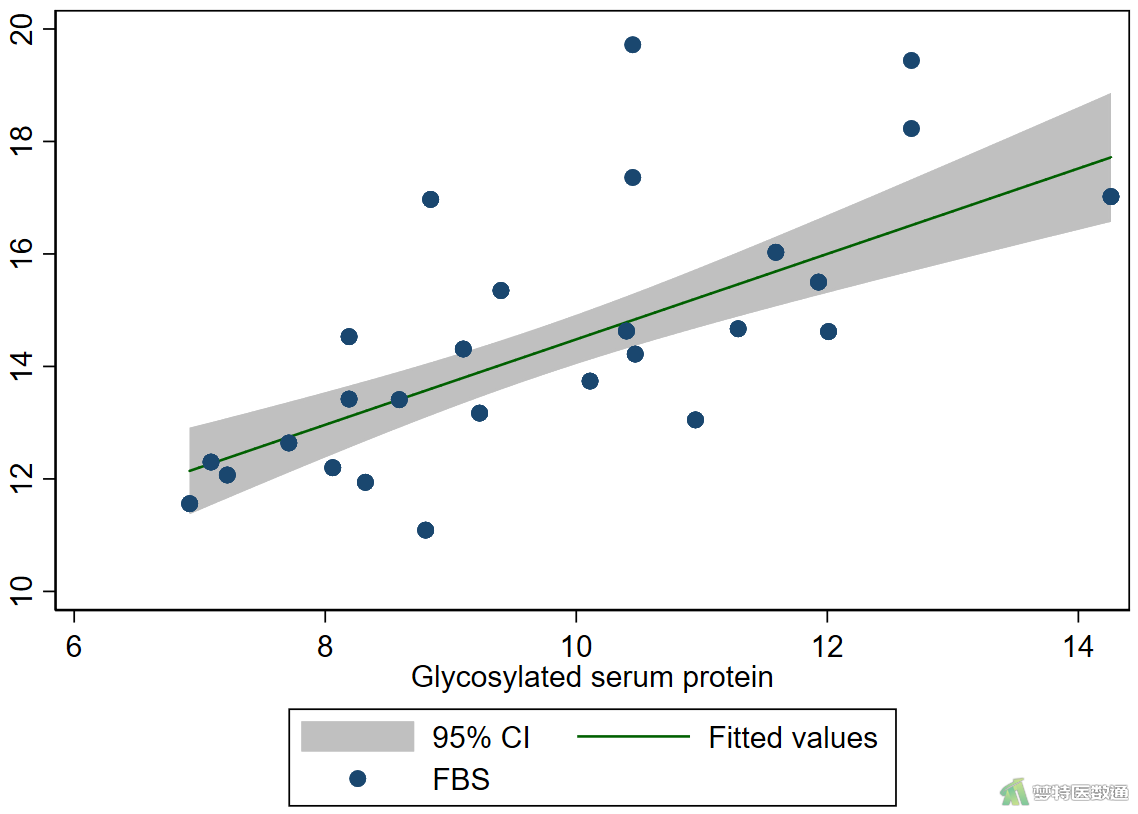
*绘制fbs和glycosylatedserumprotein的散点图*
graph twoway lfitci fbs glycosylatedserumprotein || scatter fbs glycosylatedserumprotein
(2) 结果解读
由图2-1和图2-2可知,“空腹胰岛素”、“糖化血清蛋白”与因变量“空腹血糖”之间均存在线性关系。案例数据满足条件2。
2. 条件3判断(各观测值之间的独立性)
(1) 软件操作
*生成一个顺序变量index*
gen index=_n
*将数据设置为时间序列数据格式*
tsset index

*进行回归分析*
regress fbs i.gender i.income fastinginsulin glycosylatedserumprotein
*进行自相关检验*
estat dwatson

(2) 结果解读
根据图5的结果可知,DW值为1.875,比较接近2,提示观测值相互独立,满足条件3。
3. 条件4判断(多变量异常值检测)
(1) 软件操作
*计算库克距离(Cook's Distance)*
predict cook, cooksd summarize cook

(2) 结果解读
库克距离用来判断强影响点是否为因变量的异常值点。一般认为当D<0.5时不是异常值点,当D>0.5时认为是异常值点。图6显示,本案例最大库克距离为0.234<0.5,提示不存在显著异常值,本研究数据满足条件4。
4. 条件5判断(多重共线性判断)
(1) 软件操作
*计算方差膨胀因子(variance inflation factor,VIF)和容忍度(Tolerance)*
vif
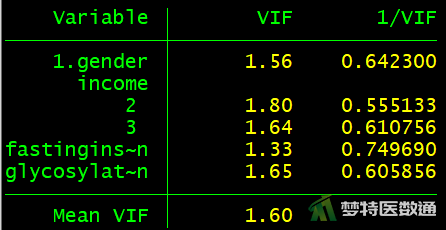
(2) 结果解读
图7结果中列出了自变量的方差膨胀因子(VIF)和容忍度(1/VIF)。可见,所有自变量的VIF均<10,1/VIF均>0.1,提示自变量之间不存在严重共线性问题。
5. 条件6判断(残差的正态性检验)
(1) 软件操作
*生成残差r*
predict r, resid
*正态性检验*
swilk r

*绘制正态分位图*
qnorm r
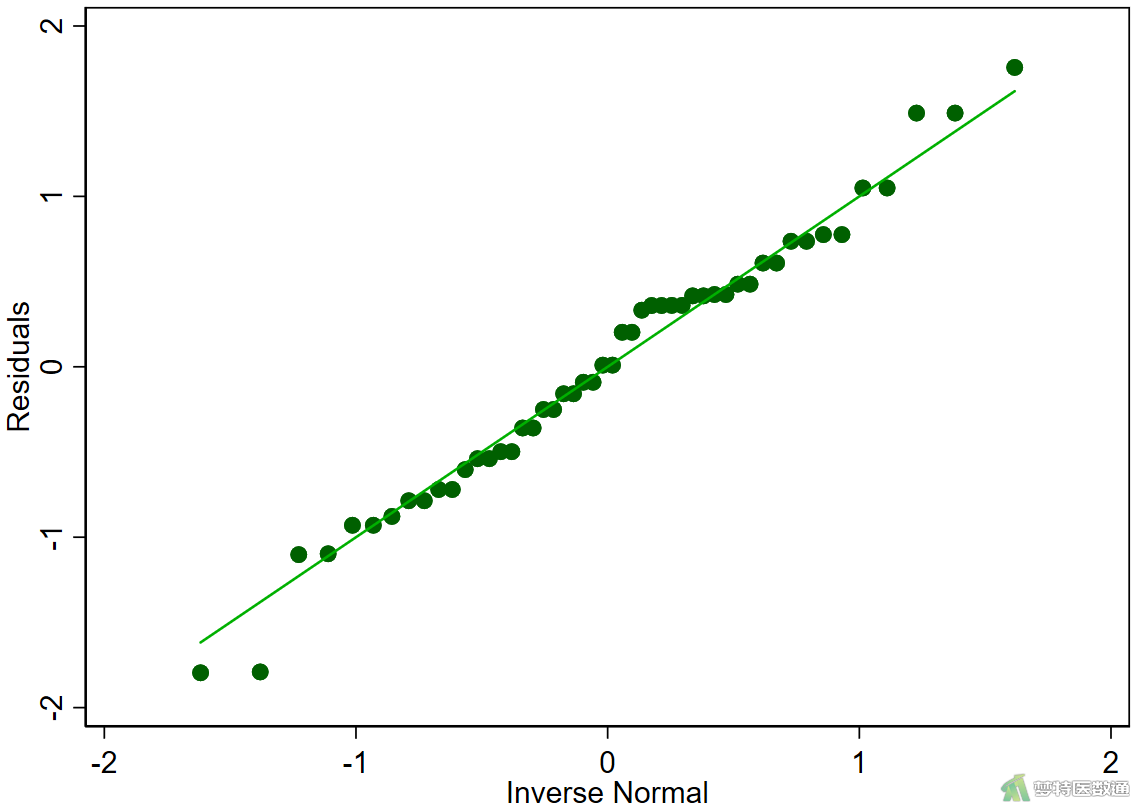
(2) 结果解读
图9结果显示,Shapiro-Wilk检验的 P=0.659>0.1,提示残差服从正态分布。图10残差的正态分位图中各散点基本围绕对角线分布,也提示残差服从正态分布。因此,本研究数据满足条件6。
6. 条件7判断(方差齐性检验)
(1) 软件操作
*绘制残差图*
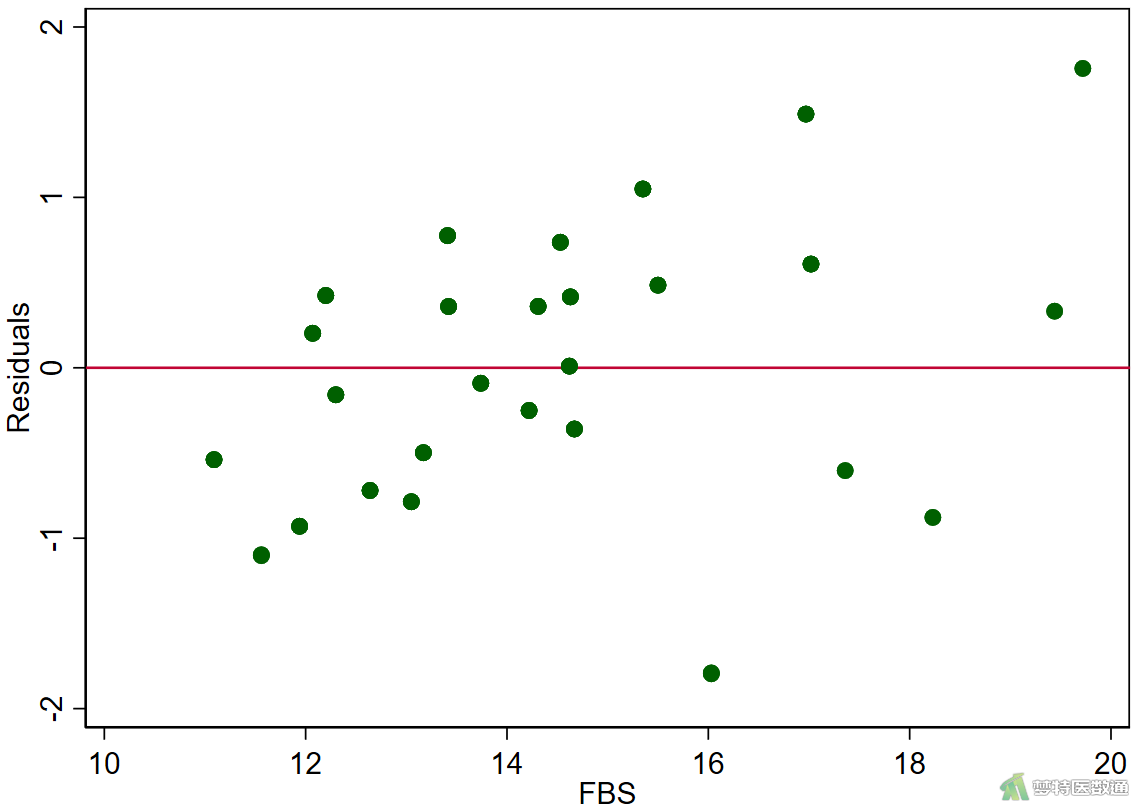
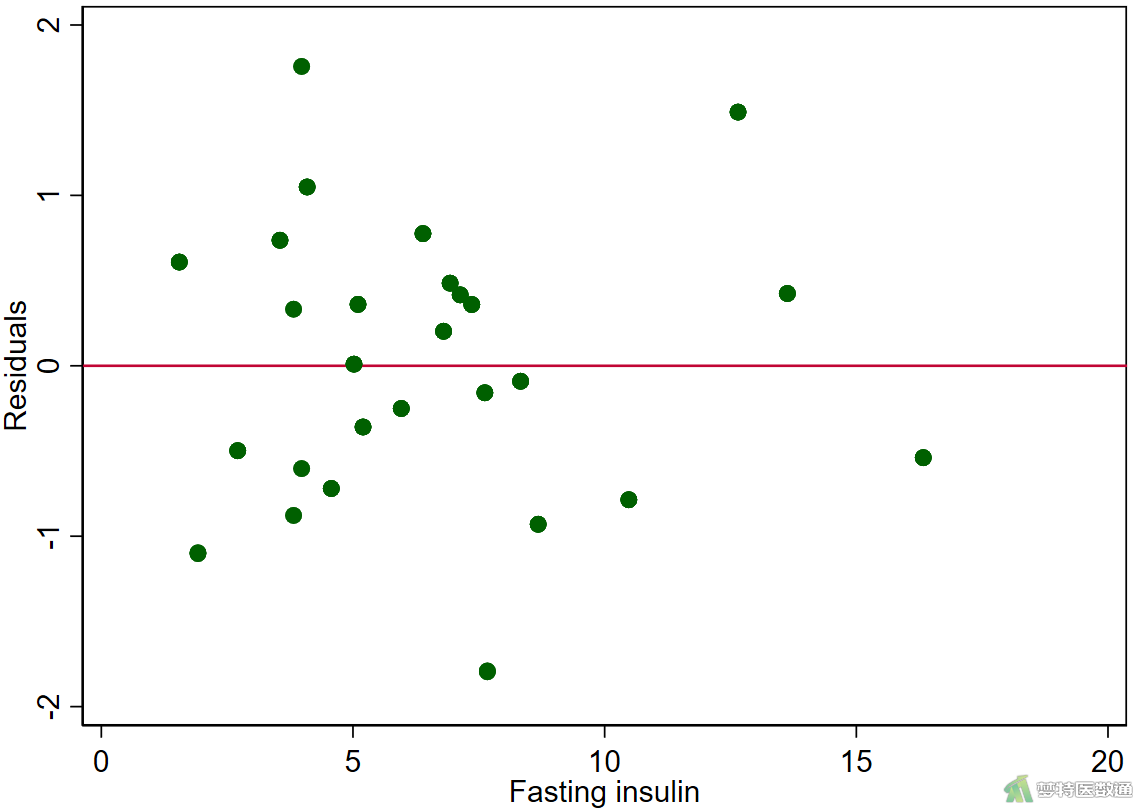
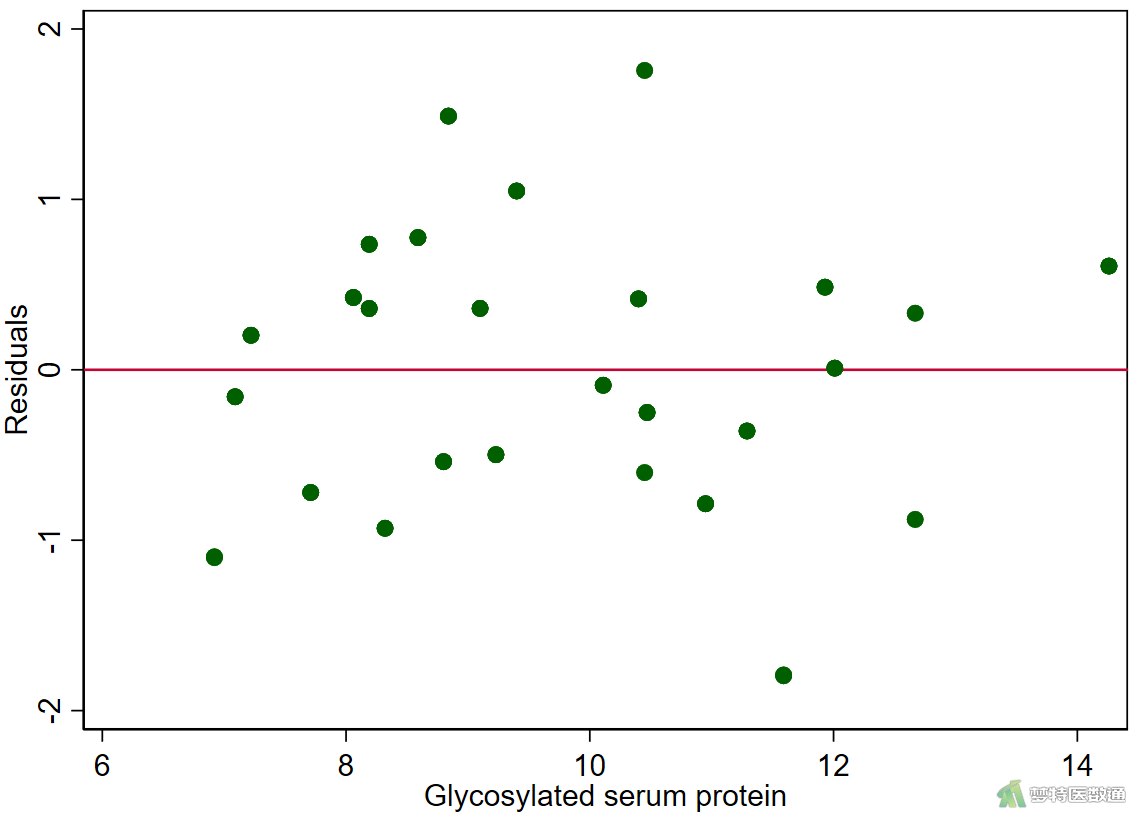
rvfplot, yline(0) scatter r fbs, yline(0) scatter r fastinginsulin, yline(0) scatter r glycosylatedserumprotein, yline(0)
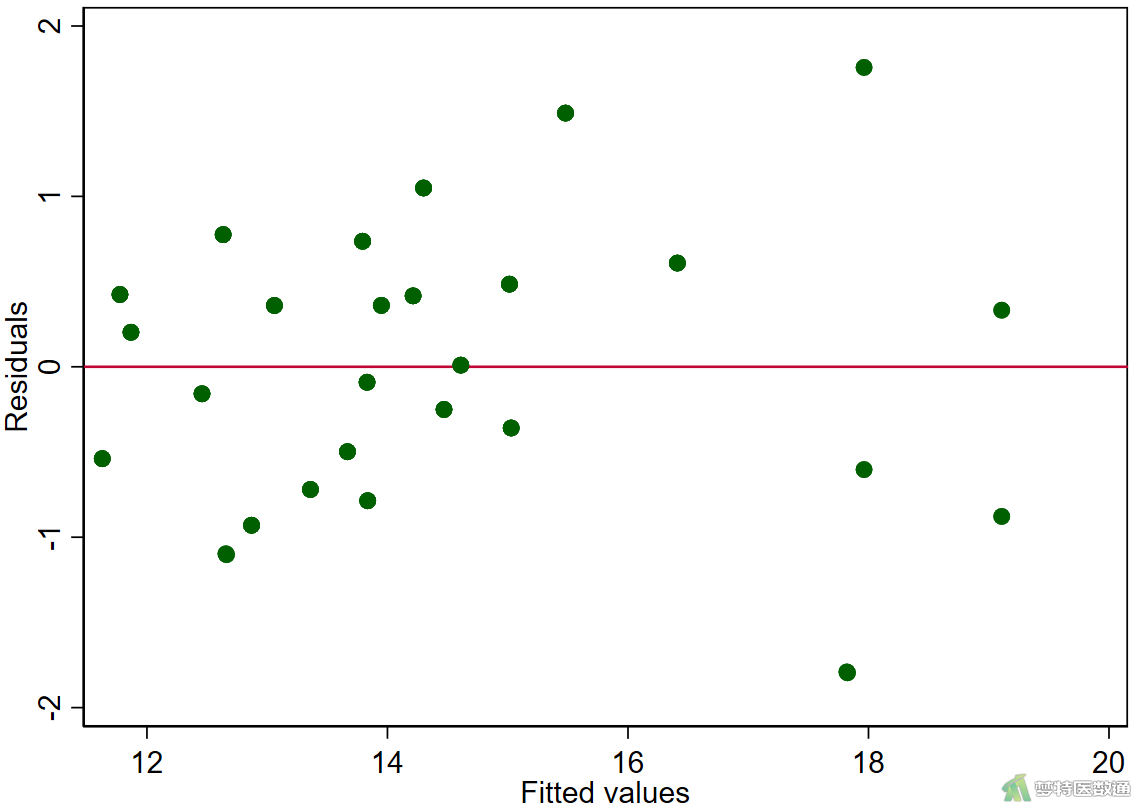
(2) 结果解读
图11-1—图11-4中预测值和各变量值的残差分布较为均匀,并未出现特殊的分布形式(如漏斗或者扇形),提示残差的方差齐,本研究数据满足条件7。
(二) 变量筛选
1. 软件操作
*安装“estout 包”*
ssc install estout, replace

因变量为空腹血糖(fbs),依次加入自变量进行线性回归,并将结果分别保存在model1—model4中,以便后续对比。
*构建回归模型*
regress fbs fastinginsulin eststo model1 regress fbs fastinginsulin glycosylatedserumprotein eststo model2 regress fbs fastinginsulin glycosylatedserumprotein i.gender eststo model3 regress fbs fastinginsulin glycosylatedserumprotein i.gender i.income eststo model4
*模型对比*
esttab, r2 ar2 se aic bic scalar(rmse p) nobase
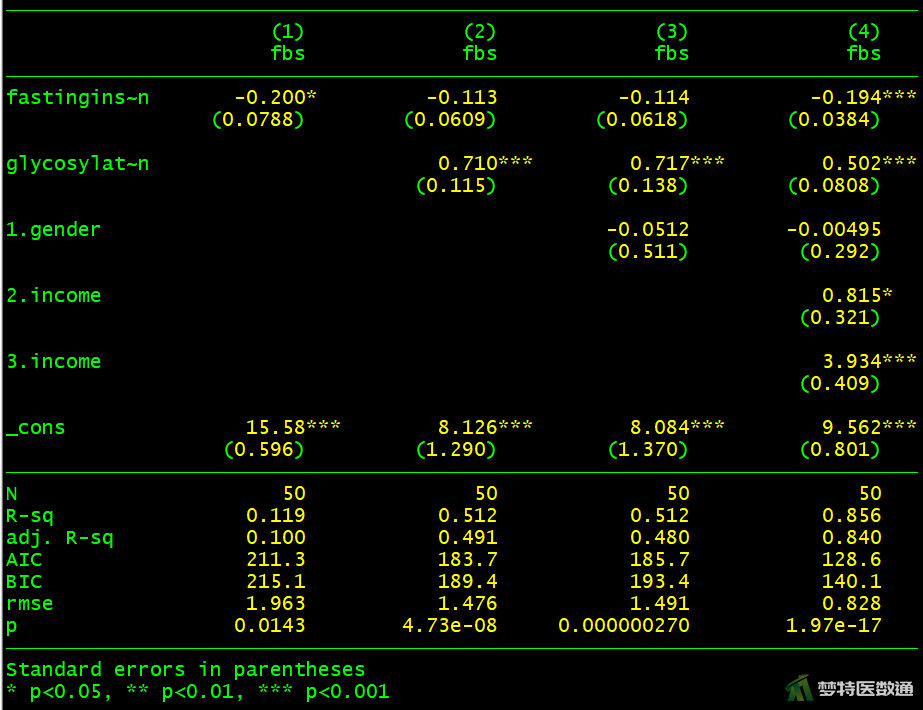
2. 结果解读
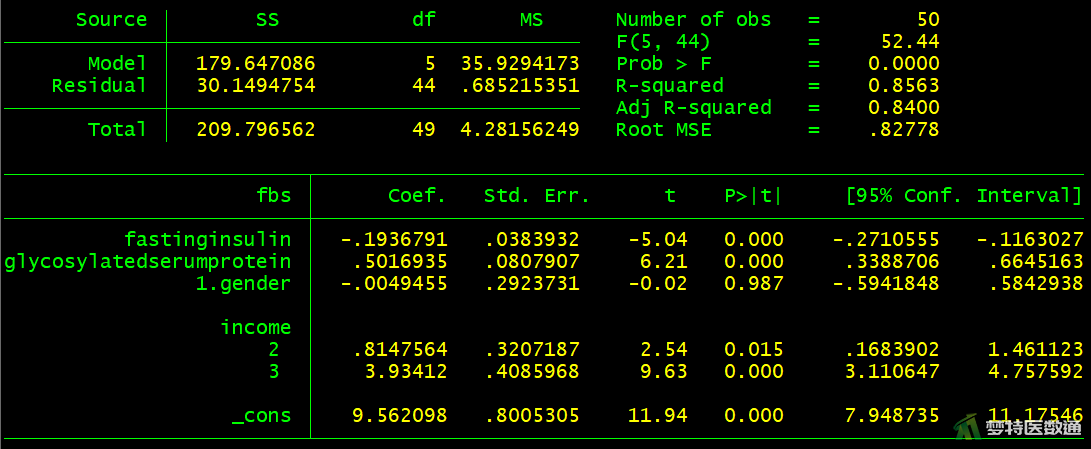
图13为模型4的分析结果,即包含了所有自变量在内的模型拟合结果。可知“性别”无统计学意义,应该被移除模型。
图14为4个模型的信息汇总结果。每个模型的P值均<0.05,可见所有模型均有统计学意义,说明所有模型中都至少存在一个自变量具有统计学意义。图14也列出了每个自变量在模型中是否有统计学意义,即是否应被纳入模型。可知,变量“性别”无统计学意义,与图13结果一致,应该被移除模型。
(三) 模型拟合
1. 软件操作
移除自变量“性别”后,进行回归分析,结果如图15所示。
regress fbs fastinginsulin glycosylatedserumprotein i.income
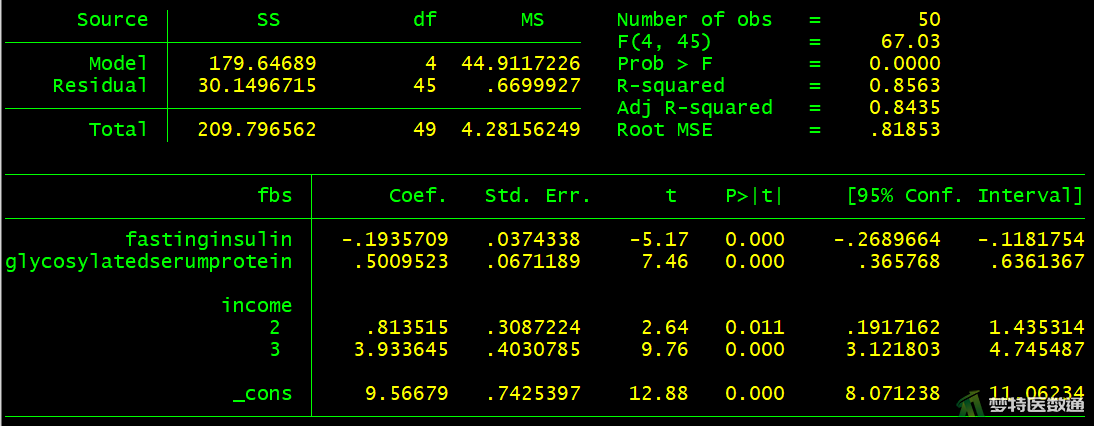
2. 结果解读
(1) 拟合优度
图15的结果列出了模型的“F检验”、 “P值”、 “R2 (决定系数)”、“Adjusted R2 (校正决定系数)”和“RMSE (均方根误差)”。可见,模型有统计学意义(F=67.03,P<0.001),决定系数为0.856,校正决定系数为0.844,均方根误差为0.819,表明模型整体拟合较好。
(2) 模型系数
图15的结果显示模型中所有自变量均有统计学意义。回归模型的截距为9.567,表示自变量取值为0时,因变量的取值,并无实际专业意义。变量“空腹胰岛素”的非标准化系数(即斜率)为-0.194 (95%CI:-0.269~-0.118,P<0.001),表示“空腹胰岛素”每增加1 mmol/L,空腹血糖减少0.194 mmol/L;变量“糖化血清蛋白”的非标准化系数(即斜率)为0.501 (95%CI:0.366~0.636,P<0.001),表示“糖化血清蛋白”每增加1%,空腹血糖增加0.501 mmol/L。相比“低收入”人群而言,“中等收入”人群的非标准化系数为0.814 (95%CI:0.192~1.435,P=0.011),表示“中等收入”人群比“低收入”人群空腹血糖高0.814 mmol/L;相比“低收入”人群而言,“高收入”人群的非标准化系数为3.934 (95%CI:3.122~4.745,P<0.001),表示“高收入”人群比“低收入”人群空腹血糖高3.934 mmol/L。
据此可以写出本案例的回归方程为:
fbs = 9.567 - 0.194fastinginsulin + 0.501glycosylatedserumprotein + 0.814income2 + 3.934income3
即:
空腹血糖 = 9.567 - 0.194×空腹胰岛素 + 0.501×糖化血清蛋白+ 0.814×(经济水平=中等收入) + 3.934×(经济水平=高收入)
根据此方程输入相关自变量数值即可对空腹血糖进行预测。
四、结论
本研究采用多重线性回归模型考察“空腹血糖”是否受到性别、经济水平、空腹胰岛素和糖化血清蛋白的影响。通过绘制散点图,提示空腹胰岛素和糖化血清蛋白与空腹血糖之间存在线性关系,通过专业判断和Durbin-Watson检验提示数据之间相互独立,通过库克距离分析,提示数据不存在需要删除的异常值;通过方差膨胀因子和容忍度判断自变量之间不存在严重多重共线性,通过Shapiro-wilk检验及绘制正态分位图,提示残差符合正态分布;通过绘制残差图,提示残差方差齐。满足多重线性回归分析条件。
多重线性回归分析结果解读为,在其他变量不变的情况下,“空腹胰岛素”每增加1 mmol/L,空腹血糖减少0.194 mmol/L (β=-0.194,95%CI:-0.269~-0.118;P<0.001);“糖化血清蛋白”每增加1%,空腹血糖增加0.501 mmol/L (β=0.501,95%CI:0.366~0.636;P<0.001);“中等收入”人群比“低收入”人群空腹血糖高0.814 mmol/L (β=0.814,95%CI:0.192~1.435;P=0.011);“高收入”人群比“低收入”人群空腹血糖高3.934 mmol/L(β=3.934,95%CI:3.122~4.745,P<0.001)。
线性回归分析方程为:空腹血糖 = 9.567 - 0.194×空腹胰岛素 + 0.501×糖化血清蛋白+ 0.814×(经济水平=中等收入) + 3.934×(经济水平=高收入)。回归模型具有统计学意义,F=67.03,P<0.001;模型可以解释84.4%的因变量的变异(adjusted R2=0.844)。
五、分析小技巧
(一) 各观测值之间的独立性检测
- Durbin-Watson检验通常用来检测残差是否存在自相关,Durbin-Watson检验值分布在0~4之间,越接近2,观测值相互独立的可能性越大。需要注意的是,判断观测值是否独立,主要取决于研究设计和数据收集阶段的质量控制,Durbin-Watson检验最好用于辅助判断。
(二) 异常值检测
- 库克距离用来判断强影响点是否为因变量的异常值点。一般认为当D<0.5时不是异常值点,当D>0.5时认为是异常值点。
- 并非所有的异常点都意味着结果不好,有时候发现异常点可能会提示有更重要的信息。如果出现异常点,首先应检查数据是否录入错误,也可以选择其他相应模型来拟合,或者需要收集更多的数据来证实。
(三) 残差的正态性检测
- 如果残差不符合正态分布,可以考虑对因变量进行数据变换,使其服从正态分布后再拟合线形回归模型。
(四) 残差的方差齐性检测
- 残差的方差齐是指在自变量取值范围内,对于任意自变量取值,因变量都有相同的方差。线形回归中,残差的方差齐实际上要比残差正态分布重要。如果这一条件不满足,可对因变量进行变量变换,使其满足残差方差齐,也可以采用加权回归分析,消除方差的影响。
(五) 共线性检测及处理
- 多重共线性是指自变量间存在线性相关关系,容忍度越小、VIF越大,表明共线性越强。实际数据分析过程中,若容忍度<0.2或VIF>5则表明存在较强共线性,若容忍度<0.1或VIF>10则表明存在严重共线性问题。
- 在实际数据分析过程中,若存在以下情况,则暗示模型可能存在共线性问题:①整个模型的检验结果为P值≤检验水准a,但各自变量的偏回归系数检验结果却为P值>检验水准a。②专业上认为应该有统计学意义的自变量,检验结果确无统计学意义。③自变量的偏回归系数的取值大小甚至符号明显与实际情况相违背,难以解释。④增加或删除一个自变量或一个案例,自变量偏回归系数发生较大变化。
- 自变量若存在严重多重共线性,可采取以下措施进行处理:①基于专业知识直接确认优先选择哪些变量进入模型,而将相对次要的共线性变量从模型中剔除。②逐步回归,但是当共线性比较严重时,变量自动筛选的方法并不能完全解决问题。③岭回归/lasso回归,为有偏估计,但能有效地解决共线性问题。④主成分回归法,这种方法的代价是在提取主成分时会丢失一部分信息,收益则是大大降低了共线性对参数估计值的扭曲,而且自变量间的多重共线性越强,提取主成分时丢失的信息就越少。
- 需要注意的是,多重共线性的存在不一定必然影响模型的使用价值,其理论上共线性不应当降低模型的预测效果,其影响主要是使模型的偏回归系数发生改变,从而无法得到专业上合理的解释。
(六) 模型评价指标
常见的回归模型评价指标有:决定系数R2、校正决定系数adjusted R2、赤池信息量准则AIC、贝叶斯信息准则BIC和均方根误差RMSE等。实际分析时,可以综合多个指标,并结合模型所反映的实际情况来判断。
- 决定系数R2 (determination coefficient)反映了因变量的变异能够被自变量解释的比例,或者说方程中的自变量解释了因变量变异的多少。R2越大,表示方程中自变量解释能力越强。但该指标有一缺陷,即其值随着自变量的增多而增加,即使加入无意义的变量,该指标值也会随之增加,因此不能较好地反映模型优劣。
- 校正决定系数adjusted R2(adjusted determination coefficient) 是对决定系数的修正。当有统计学意义的变量进入方程时,该指标随之增大,而当无统计学意义的变量进入方程时,其值减小。值越大表明模型越好,是衡量模型优劣的重要指标之一。
- AIC为赤池信息量准则(Akaike information criterion),BIC为贝叶斯信息准则(Bayesian Information Criterion),两者均是衡量统计模型拟合优良性(Goodness of fit)的一种标准,其值越小越好。
- AIC建立在熵的概念基础上,可以权衡所估计模型的复杂度和此模型拟合数据的优良性。BIC的惩罚项比AIC的大,考虑了样本数量,样本数量过多时,可有效防止模型精度过高造成的模型复杂度过高。AIC和BIC的原理是不同的,AIC是从预测角度,选择一个好的模型用来预测,BIC是从拟合角度,选择一个对现有数据拟合最好的模型,从贝叶斯因子的解释来讲,就是边际似然最大模型。
- 均方根误差RMSE主要反映模型的估计精度,值越小越好。一般会随模型中自变量个数增加而减小,这一性质与校正系数相似。