在前面文章中介绍了独立样本Wilcoxon秩和检验(Wilcoxon Rank Sum Test)的假设检验理论,本文将实例演示在Python软件中实现独立样本Wilcoxon秩和检验的操作步骤。
关键词:Python软件; 非参数检验; 秩和检验; Wilcoxon秩和检验; 独立样本秩和检验; Mann-Whitney U检验
一、案例介绍
某医师对12例高血压患者和11例糖尿病患者血清总胆固醇(TCHO)含量(mmol/L)进行了测定,问高血压患者和糖尿病患者的血清总胆固醇含量是否不同?部分数据见图1。本案例数据可从“附件下载”处下载。
二、问题分析
本案例的分析目的是比较两组计量资料是否有差异,即判断高血压患者和糖尿病患者的血清总胆固醇含量是否不同。比较两组计量资料是否有差异可以使用两独立样本t检验或Wilcoxon秩和检验。如果数据满足正态性和方差齐性要求则可以使用两独立样本t检验。若满足正态性,不满足方差齐性,可使用校正t检验(Welch’s t检验)。但如果数据的方差相差太大,最好使用非参数检验(Wilcoxon秩和检验)。如果数据正态性和方差齐性都不满足,最好使用非参数检验(Wilcoxon秩和检验)。使用Wilcoxon秩和检验时,需要满足3个条件:
条件1:有1个观察变量,且观察变量为连续变量(不满足正态分布或方差严重不齐)或等级变量。该条件需要通过软件判断或专业判断。
条件2:有1个分组变量,且为二分类。本研究中分为高血压患者组和糖尿病组,该条件满足。
条件3:具有相互独立的观测值。本研究中各研究对象的TCHO含量都是独立的,不存在互相干扰的情况,该条件满足。
三、软件操作及结果解读
(一) 导入数据
import pandas as pd #导入pandas包
df = pd.read_csv('独立样本Wilcoxon秩和检验.csv') #导入CSV数据
pd.set_option('display.max_rows', 10)
df #查看数据

图1
在数据栏目中可以查看全部数据情况(图1),数据集中共有3个变量和23个观察数据,3个变量分别代表被调查者的编号(ID)、分组(group)及血清总胆固醇含量(TCHO)。
(二) 适用条件判断
1. 条件1判断(正态性检验)
(1) 软件操作
Wilcoxon秩和检验时,需要分别考察每一组数据的正态性情况,因此需要拆分数据。
##分组描述数据子集##
df.groupby('group').describe()

图2
##绘制Q-Q图##
import statsmodels.api as sm #导入statsmodels.api包 import pylab sm.qqplot(df.loc[df.loc[:,'group']=='Hypertension','TCHO'], line='s') #绘制子集1的Q-Q图 pylab.show() sm.qqplot(df.loc[df.loc[:,'group']=='Diabetes','TCHO'], line='s') #绘制子集2的Q-Q图 pylab.show()
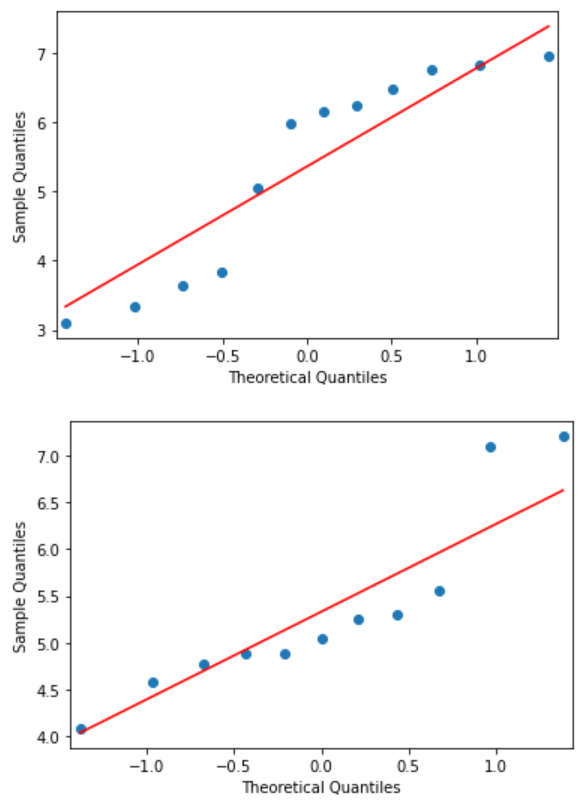
图3
##正态性检验##
from scipy import stats #导入scipy包 shapiro_test1 = stats.shapiro(df.loc[df.loc[:,'group']=='Hypertension','TCHO']) print(shapiro_test1) shapiro_test2 = stats.shapiro(df.loc[df.loc[:,'group']=='Diabetes','TCHO']) print(shapiro_test2) #分组进行Shapiro-Wilk正态性检验
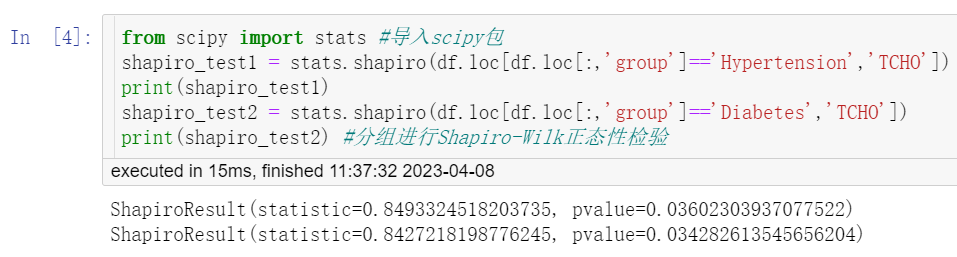
图4
(2) 结果解读
“describe (描述性分析)”命令运行结果(图2)列出了观察变量的“mean (均数)”、“std (标准差)”、“min (最小值)”、“25% (下四分位数)”、“50% (中位数)”、“75% (上四分位数)”和“max (最大值)”。
中的Q-Q图上两组散点偏离对角线较远(图3),提示两组数据不服从正态分布;正态性检验结果(图4)显示两组的P值为0.03602和0.03428,均<0.1,也提示两组数据不服从正态分布。关于正态性检验的注意事项详见“正态性假设检验(Normality Hypothesis Test)——SPSS软件实现”。
2. 条件1判断(方差齐性检验)
(1) 软件操作
## levene法方差齐性检验##
group0 = df.loc[df.loc[:,'group']=='Diabetes']['TCHO'] #选取第一组数据 group1 = df.loc[df.loc[:,'group']=='Hypertension']['TCHO'] #选取第二组数据 leveneTestRes = stats.levene(group0, group1, center='mean') #levene法齐性检验 print(leveneTestRes) #显示检验结果
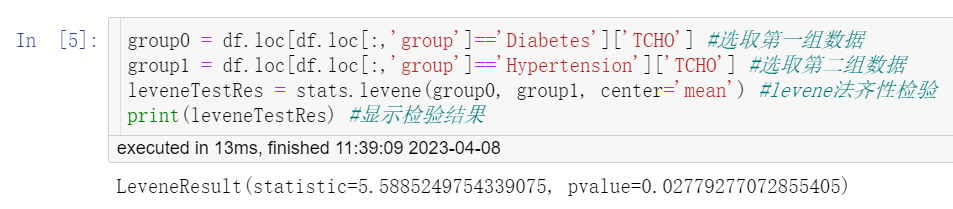
图5
(2) 结果解读
“describe (描述性分析)”运行结果(图2)显示,高血压组和糖尿病组的std分别为1.48和0.98,两组之间std数值貌似存在差异,但还需要依据统计学检验的结果进行判断。
方差齐性检验结果(LeveneResult,图5)显示statistic (F) = 5.5885,P=0.02779<0.1,提示两组数据方差不齐。关于方差齐性检验的更多内容详见“方差齐性检验(Homogeneity of Variance Test)——SPSS软件实现”。
综上,本案例中两组连续变量数据既不服从正态分布,也不满足方差齐性,可以考虑使用Wilcoxon秩和检验。
(三) 统计描述及推断
1. 软件操作
## Wilcoxon秩和检验##
from scipy import stats stats.mannwhitneyu(group0,group1,alternative='two-sided') #对比两组数据的排序是否相同

图6
2. 结果解读
Wilcoxon秩和检验结果(图6)显示,statistic (U) = 63.5, P = 0.902,差异无统计学意义(P>0.05),尚不能认为高血压患者和糖尿病患者的血清总胆固醇含量不同。
四、结论
本研究采用Wilcoxon秩和检验判断高血压患者和糖尿病患者的血清总胆固醇含量是否不同。通过Q-Q图和Shapiro-Wilk检验,提示两组数据不服从正态分布;通过Levene’s检验,提示两组数据总体方差不齐,符合使用Wilcoxon秩和检验的条件。
结果显示,高血压患者和糖尿病患者的TCHO含量分别为6.060 (P25~P75:3.790~6.540) mmol/L和5.040 (P25~P75:4.825~5.430) mmol/L。Wilcoxon秩和检验结果显示:U=63.5,P=0.902,差异无统计学意义((P>0.05)。本研究结果提示,尚不能认为高血压患者和糖尿病患者的血清总胆固醇含量不同。