前面介绍了独立样本t检验的相关理论(独立样本t检验(Independent Samples t-test)——理论介绍),本文介绍独立样本t检验在jamovi软件中的操作过程。
关键词:jamovi; t检验; 独立样本t检验
一、案例介绍
某医生研究某生化指标(X)对病毒性肝炎诊断的临床意义,测得20名正常人和19名病毒性肝炎患者生化指标(X)含量(μg/dl),问病毒性肝炎患者和正常人生化指标(X)含量是否存在差异?对数据的变量和水平进行标签赋值后部分数据见图1。本文案例可从“附件下载”处下载。

二、问题分析
本案例的分析目的是比较两组数据均值是否有差异,即判断病毒性肝炎患者和正常人生化指标(X)含量是否存在差异。针对这种情况可以使用独立样本t检验。但需要满足6个条件:
条件1:观察变量为连续变量。本研究中的生化指标含量为连续变量,该条件满足。
条件2:观测值相互独立。本研究中各研究对象的观测值都是独立的,不存在互相干扰的情况,该条件满足。
条件3:观察变量可分为2组。本研究中分为病毒性肝炎患者和正常人,该条件满足。
条件4:观察变量不存在显著的异常值,该条件需要通过软件分析后判断。
条件5:各组观测值为正态(或近似正态)分布,该条件需要通过软件分析后判断。
条件6:两组观测值的方差齐,该条件需要通过软件分析后判断。
三、软件操作及结果解读
(一)适用条件判断
1. 条件4判断(异常值判断)
独立样本t检验时,需要分别考察每一组的异常值情况,因此需要使用“拆分”功能
(1) 软件操作
① 选择“分析”—“探索”—“描述”,将观察变量“X”选入右侧“变量”框,将“分组”选入右侧“拆分”框(图2)。

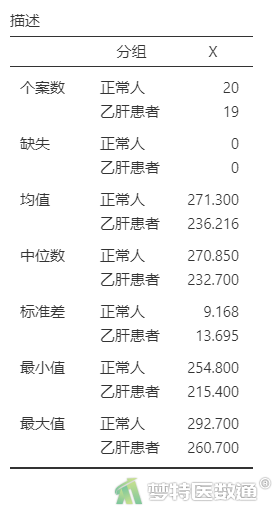
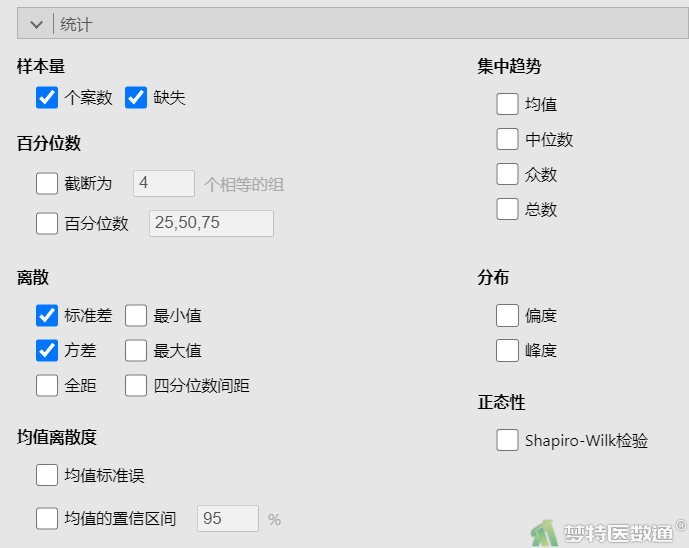
② 在“统计分析”下的“样本量”中勾选“个案数”、“缺失”,在“集中趋势”中勾选“均值”、“中位数”,在“离散趋势”中勾选“标准差”、“最小值”和“最大值”(图3),结果如图4所示。

③ 在“绘图”下的“箱线图”中勾选“箱线图”和“数据”,“数据”下拉菜单中选择“散点”(图5),结果如图6所示。
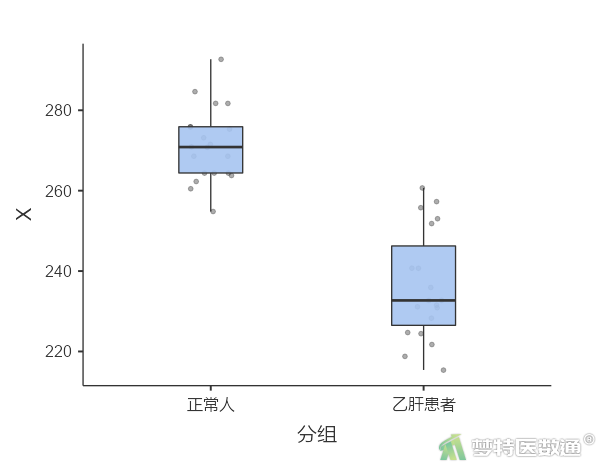
(2) 结果解读
图4“描述”表格中,列出了各组观察变量的最小值和最大值,依据专业可判断人体生化指标含量均可能存在215.4μg/dl和292.7μg/dl的情况;此外,图6中的箱线图也未提示任何异常值。综上,本案例未发现需要处理的异常值,满足条件4。
2. 条件5判断(正态性检验)
(1) 软件操作
独立样本t检验时,需要分别考察每一组的正态性情况,因此需要使用拆分功能 (见图2)。
① 在“绘图”下勾选“Q-Q图”(图7),结果如图8所示。

② 在“统计”中勾选“Shapiro-Wilk检验 (夏皮罗-威尔克正态性检验)”(图9),结果如图10所示。


(2) 结果解读
图8和图10按照组别列出了两组的分析结果。图8的Q-Q图上两组散点基本围绕对角线分布,提示两组数据呈正态分布;图10的正态性检验结果分别显示两组的P=0.813和0.192,均>0.1,也提示两组数据服从正态分布。综上,本案例满足条件5。关于正态性检验的更多内容请阅读(医学统计学核心概念及重要假设检验的软件实现(2/4) ——正态性假设检验的SPSS实现)。
3. 条件6判断(方差齐性检验)
(1) 软件操作
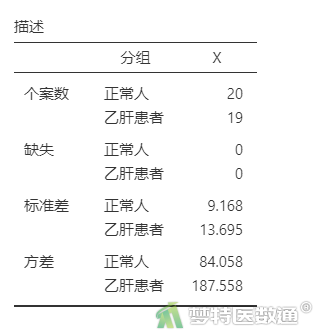
① 选择“分析”—“探索”—“描述”,在“离散趋势”中勾选“标准差”和“方差”(图11),结果如图12所示。
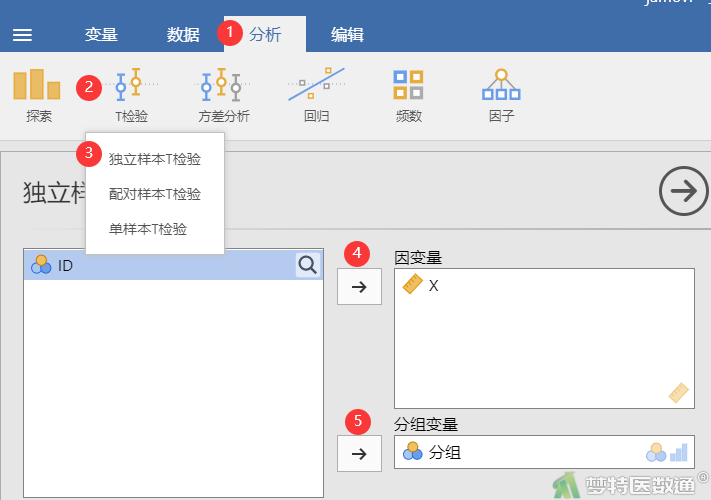
② 选择“分析”—“ T检验”—“独立样本T检验”,将“X”选入右侧“因变量”框,将“分组”选入右侧“分组变量”框(图13)。
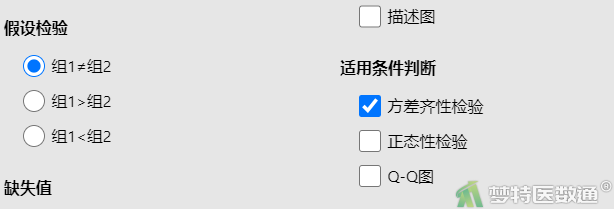
③ 在“假设检验条件判断”中勾选“方差齐性检验”(图14),结果如图15所示。

(2) 结果解读
由图12“描述”表格中“标准差”和“方差”结果可知,正常人和肝炎患者的标准差分别为9.168和13.695,方差分别为84.058和187.558,两组之间标准差和方差数值貌似存在差异,但还需要依据统计学检验的结果进行综合判断。
图15“方差齐性检验(Levene’s)”为方差齐性检验结果,可见F=3.883,P=0.056<0.1,提示两组数据方差不齐,不满足条件6。关于方差齐性检验的更多内容请阅读(医学统计学核心概念及重要假设检验的软件实现(4/4)——方差齐性检验及SPSS实现)。
(二) 统计描述及推断
1. 软件操作
选择“分析”—“ T检验”—“独立样本T检验”, 将观察变量“X”选入右侧“变量”框,将“分组”选入右侧“拆分”框(见图13),并按照图16勾选相应选项。

2. 结果解读
(1) 统计描述
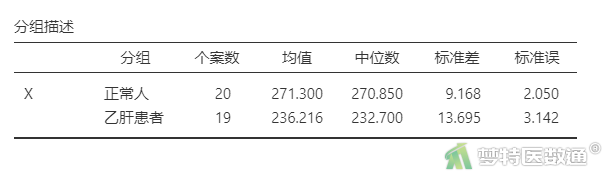
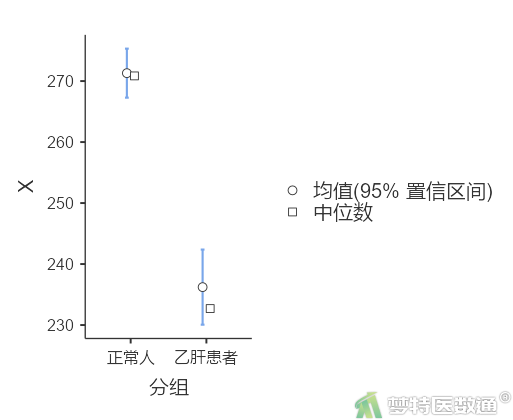
图17“分组描述”表格中提供了研究案例的“分组”、“个案数”、“均值”、“中位数”、“标准差”和“标准误”。可知,正常人群的生化指标含量为271.300±9.168 μg/dl,肝炎患者的生化指标含量为236.216±13.695 μg/dl。图18为两组人群生化指标含量的分布图。两组的生化指标含量存在差异,但还需要依据统计学检验的结果进行判断。
(2) 统计学推断
图19“独立样本t检验”表格中提供了t检验(Student’s t)和校正t检验(Welch’s t)两种方法分析的“统计量”、“自由度”、“P值”、“均数差”及其“95%置信区间”、“均数差标准误”及“效应量”。
由于本案例满足正态性要求,但不满足方差齐性要求,所以采用校正t检验(Welch’s t)分析结果。可知肝炎患者的生化指标含量平均值比正常人群低35.084 μg/dl,95%置信区间为-27.435~-42.733;差异有统计学意义(t'=9.352,P<0.001)。Cohen's d值为3.011,为高效应。

四、结论
本研究采用独立样本t检验判断病毒性肝炎患者和正常人生化指标含量是否存在差异。通过专业知识判断,两组数据不存在需要需要处理的异常值;通过绘制Q-Q图和Shapiro-Wilk检验,提示两组数据服从正态分布;通过Levene’s检验,提示两组数据间方差不齐,采用Welch’s t检验对数据进行分析。
结果显示,正常人群和肝炎患者的生化指标含量分别为271.300±9.168 μg/dl和236.216±13.695 μg/dl;肝炎患者的生化指标含量平均值比正常人群低35.084 μg/dl (95%置信区间:-27.435~-42.733),差异有统计学意义(t'=9.352,P<0.001);Cohen's d效应量为3.011,差异较大。因此,可以认为该生化指标含量对病毒性肝炎的临床诊断具有价值。
五、分析小技巧
- 在进行独立样本t检验时,正态性检验应分组进行,而不是对全部数据进行一次正态性检验。
- t检验对数据的非正态性有一定的耐受能力,如果资料只是稍微偏态,结果仍然稳健。
- 独立样本t检验时对两组数据之间的方差齐性要求较为严格,与数据违反正态性相比,方差不齐对结论的影响较大。
- 如果数据对条件1至条件5都满足,仅不满足方差齐,此时可使用校正t检验(Welch’s t检验)。但如果数据的方差相差太大,最好使用非参数检验(Mann-Whitney U检验)。如果数据正态性和方差齐性都不满足,最好使用非参数检验(Mann-Whitney U检验)。
- 如果两组数据之间方差的差异无统计学意义,此时student’s t检验比Welch’s t检验具有更高的统计学检验效能(发生第II类错误的概率更低),如果两组数据方差差异较大,此时Welch’s t检验发生第II类错误的概率更低,结果更为可信。
- 与数据违反正态性相比,方差不齐对结论的影响较大,所以主要依靠假设检验进行考察。然而“方差齐性检验(Levene’s)”的结果易受到样本量的影响,并不是很稳定。当样本量较大时,倾向于得出P值低于检验水准的结论,尽管可能组别之间的方差差异并不大;反之,当样本量较小时,尽管组别之间的方差差异可能较大,但倾向于得出P值高于检验水准的结论。因此,以统计描述的形式报告各组数据的具体标准差和方差,并将其纳入综合考量是必要的。