在前面文章中介绍了配对样本t检验(Paired Samples t-test)的假设检验理论,本篇文章将实例演示在Python软件中实现配对样本t检验的操作步骤。
关键词:Python; t检验; 配对样本t检验; 配对t检验; 成对t检验; 关联样本t检验; 差值正态性
一、案例介绍
为检测肌肉组织中某生化指标(X)的含量,分别使用A、B两种方法检测17只小白鼠肌肉组织中该生化指标(X)的含量,试问两种方法检测的结果是否有差异。
二、问题分析
本案例的分析目的是比较两种检测方法对同一批样本检测的结果是否存在差异,由于检测的指标是计量资料,因此可以使用配对样本t检验。但需要满足5个条件:
条件1:观察变量为连续变量。本研究中的生化指标(X)含量为连续变量,该条件满足。
条件2:观察变量为配对设计或具有相关性,即不满足独立性。本研究中,两组数据均是对同一批研究对象测量所得,因此属于配对样本,不满足独立性。该条件满足。
条件3:观察变量可分为2组,本研究中分为A方法和B方法两组,该条件满足。
条件4:观察变量不存在显著的异常值,该条件需要通过软件分析后判断。
条件5:两个配对(相关)组别间观察变量的差值服从正态或近似正态分布,该条件需要通过软件分析后判断。
三、软件操作及结果解读
(一) 导入数据
import pandas as pd #导入pandas包
import numpy as np #导入numpy包
df = pd.read_csv(r'D: \配对样本t检验.csv',index_col=0,encoding="ANSI") #导入数据
df.info() #查看数据结构图
df2 = df.rename(columns={'A':'A方法','B':'B方法'}) #对变量进行重命名
df2 #显示df

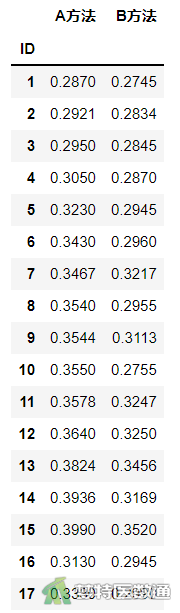
图1可查看数据框结构。图2可查看全部数据情况,数据集中共有3个变量和17个观察数据,3个变量分别代表被调查者的编号(ID) 、A方法(A)及B方法(B)。
(二) 适用条件判断
1. 条件4判断(异常值检测)
(1) 软件操作
#查看最大、最小值#
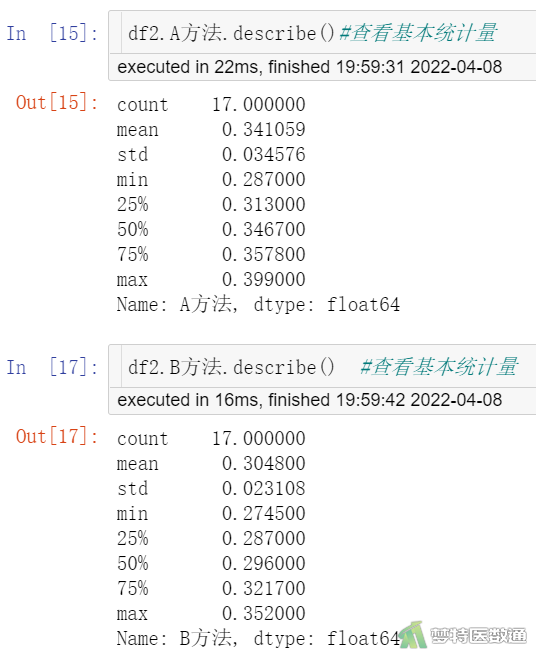
df2.A方法.describe() df2.B方法.describe() #查看基本统计量
#绘制箱线图#
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'SimSun' #设置中文字体
plt.boxplot((df2.A方法,df2.B方法),labels=('A方法','B方法'),vert = True)
plt.show() #展示箱线图
(2) 结果解读
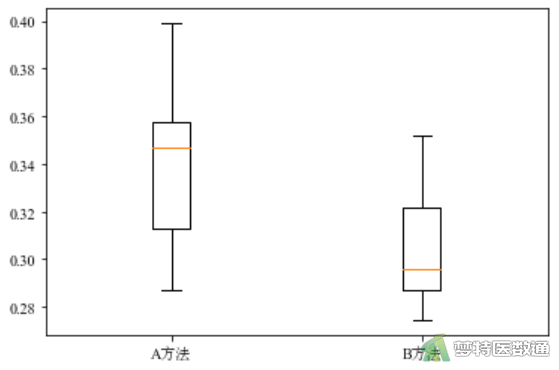
图3列出了观察变量的“Min (最小值)”、“1st Qu (P25)”、“Median (中位数)”、“Mean (平均值)”、“3rd Qu (P75)”和“Max (最大值)”,最小值和最大值分别为0.275和0.399,尚无专业依据认定为异常值;此外,图4中的箱线图也未提示任何异常值。综上,本案例未发现需要处理的异常值,满足条件4。
2. 条件5判断(正态性检验)
(1) 软件操作
#绘制QQ图#
df2['d'] = df2['A方法'] - df2['B方法'] #计算差值 df2.head() import statsmodels.api as sm import pylab sm.qqplot(df2['d'], line='s') pylab.show() #展示QQ图

#正态性检验#
from scipy.stats import shapiro,ttest_rel shapiro(df2['d'])
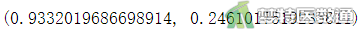
(2) 结果解读
图5 Q-Q图上散点基本围绕对角线分布,提示数据呈正态分布;图6的“shapiro (S-W正态性检验)”结果显示P≈0.2461>0.1,也提示两组数据差值均服从正态分布。综上,本案例满足条件5。
(三) 统计描述及推断
1. 软件操作
#配对样本t检验#
print(ttest_rel(df2.A方法, df2.B方法))
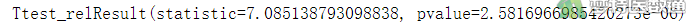
#计算均值差#
aa = np.mean(df2.A方法)
print('A方法均值:',aa)
bb = np.mean(df2.B方法)
print('B方法均值:',bb)
junzhicha = aa - bb
print('均值差:',junzhicha)

#计算置信区间#
from scipy import stats
t_ci=2.12
sample_mean=df2['d'].mean()
se=stats.sem(df2['d'])
a=sample_mean-t_ci*se
b=sample_mean+t_ci*se
print('差值的置信区间,95 CI=[%f,%f]'%(a,b))
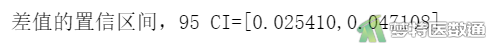
2. 结果解读
(1) 统计描述
由图3可知,A方法组含量为0.341±0.034,B方法组含量为0.305±0.022,图4为两种方法检测的生化指标(X)含量的分布图。两组检测结果存在差异,但还需要依据统计学检验的结果进行判断。
(2) 统计学推断
图7“ttest_rel (配对样本t检验)”运行结果中提供了统计学推断后的“statistic (统计量)”(即t值)、“pvalue (P值)”。可知A、B方法检测结果差异有统计学意义(statistics =7.085,P<0.001)。由图8、图9可知A方法检测结果比B方法平均高0.036,95%CI为0.025~0.047;
(四) 相关性检验
1. 软件操作
#绘制散点图#
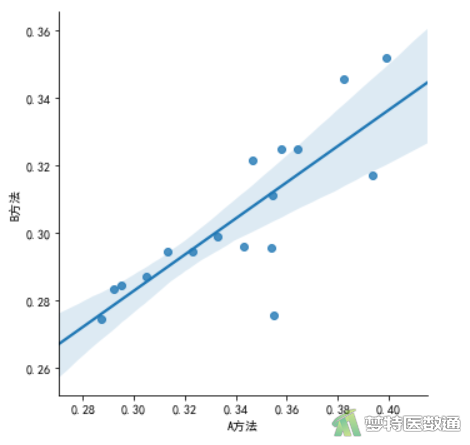
import seaborn import matplotlib.pyplot as plt plt.rcParams['font.family'] = " SimSun" seaborn.lmplot(y='B方法', x = 'A方法',data=df2) plt.show()
#进行相关性检验#
from scipy.stats import pearsonr
r = pearsonr(df2.A方法,df2.B方法)
print("pearson系数:",r[0])
print("P-Value:",r[1])

2. 结果解读
图10的散点图提示,两组之间存在线性相关。由图11相关性分析结果可知,两组Pearson相关系数为0.8036817,P < 0.001,提示两组数据之间的相关性有统计学意义,表明A、B两种方法之间的差异具有较好的稳定性。
四、结论
本研究采用配对样本t检验判断A、B两种方法检测肌肉组织中生化指标(X)的含量是否有差异。通过专业知识判断,数据不存在需要处理的异常值;通过绘制Q-Q图和Shapiro-Wilk检验,提示两组数据差值服从正态分布。
描述性分析结果显示,A、B方法检测肌肉组织中生化指标(X)的含量分别为0.341±0.035和0.305±0.022,A方法平均值比B方法高0.036 (95%CI:0.025~0.047),差异有统计学意义(statistics =7.085,P<0.001)。两组Pearson相关系数为0.804,P < 0.001;表明A、B两种方法之间的差异具有较好的稳定性。因此,本案例分析表明,使用A方法检测肌肉组织中生化指标(X)的含量通常会比B方法检测结果值要高。
五、知识小贴士
(一) 配对设计类型
临床研究过程中常见的两组配对设计包括:
- 同一组研究对象身体不同部位配对,如癌组织与癌旁组织某种基因的表达、左手和右手的血压比较。
- 条件配对,如在同一窝老鼠中选择性别和体重相同的2只作为一个对子,组成多个这样的对子;再将每个对子中的2只老鼠随机分配到2个处理组中去,然后比较两种处理方法的效果。
- 同一批标本不同检测方法配对,如同一批血液,被分成2份,分别用两种方法检测某种生化指标的含量(本案例属于该种类型)。
- 还有一类特殊的研究设计,同一组研究对象干预前后配对,如同一组病人使用降血糖药物前后空腹血糖值的比较。对于这类设计,尽管可使用配对样本t检验进行数据分析,但严格来说并不属于配对设计,而是属于干预前后的重复测量设计。
(二) 相关性的计算
相关性的计算是为了验证配对数据的一致性,可以说明研究因素作用的稳定性或一致性,可能存在四种情况。
- 相关性检验与配对t检验的P值均<0.05,说明数据一致性较好,差异有统计学意义,而且差异的产生就是研究因素作用的结果。
- 相关性检验P>0.05,配对t检验的P<0.05,说明两组数据间存在差异,但对子间均数差异变化不一致,均数差异可能还受其他因素的影响。
- 相关性检验P<0.05,但配对t检验的P>0.05,说明数据变化有一致性,但均数差异不显著,即研究因素未发挥作用。
- 相关性检验与配对t检验的P值均>0.05,说明数据在两组间不具备一致性,且差异也无统计学意义。
六、分析小技巧
- t检验,其结果与配对样本t检验结果完全一致。
- 对于干预前后配对和部位配对研究,也可使用重复测量方差分析实现研究目标。