在平行组设计的诊断试验研究中[诊断试验(Diagnosis Test)研究概述一——设计类型],研究对象随机分为两组,各组研究对象分别接受不同的待评价诊断试验,并均使用金标准进行确诊,两组样本之间彼此独立。其样本量的计算,可通过两独立样本的灵敏度检验(Tests for two independent sensitivities)或两独立样本的特异度检验(Tests for two independent specificities)方法实现。
关键词:样本量计算; PASS; 诊断试验; 两独立样本诊断试验的样本量计算;灵敏度和特异度比较的样本量计算
灵敏度和特异度是诊断试验研究中两个重要的衡量准确性的指标。灵敏度(Se)是指受试者实际有病且被诊断试验诊断为有病的概率,反映了诊断试验检出病例的能力;特异度(Sp)是指受试者实际无病且被诊断试验诊断为无病的概率,反映了诊断试验排除病例的能力。本文介绍两独立样本的灵敏度检验的样本量估算,如果要进行两独立样本的特异度检验,则需将所有条目中的Se替换为Sp,用无病率(1-P)代替疾病患病率(P)。
一、案例数据
已知某病在待评价人群中的患病率为30%,假设用现有诊断方法诊断该病的灵敏度为80%,而新方法成本更低。研究者希望设计一项前瞻性研究,使用双侧Z检验比较新方法与现有方法的灵敏度。以医疗机构公认的某检查为金标准,期望新方法灵敏度能达到90%。取双侧α=0.05、β=0.20,试估计所需的样本含量。
二、案例分析
本研究中受试者被随机分成两组,每个受试者分别接受一项诊断试验,并与金标准进行比较。欲比较两个诊断方法的灵敏度,可采用两独立样本的灵敏度检验,需要以下几个参数:
- 目前方法在两组受试者中的灵敏度Se1,本例为0.8
- 新方法在第二组受试者中的灵敏度Se2,本例为0.9
- 疾病的患病率P,本例为0.3
- 检验水准α (通常取0.01至0.1),本例取0.05
- 检验功效1-β (通常为0.8或更高),本例取0.8
- 脱失率(DR,通常不宜超过20%),本例取10%
三、软件操作
(一) 方法选择
在左侧界面中依次选择“Procedures (程序)”—“Proportions (比例)”—Sensitivity and Specificity (灵敏度和特异度检验)”—“ Tests for two independent sensitivities (两独立样本的灵敏度检验)”,见图1。

(二) 参数设置
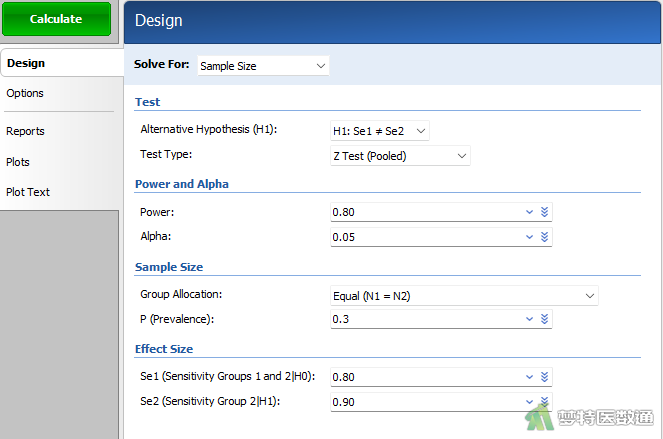
在“Design (设置)”模块中按以下参数设置相应选项(图2):
- Solve For:选择“Sample Size”,表示本分析的目的是用于计算样本量。
- Alternative Hypothesis (H1):指定灵敏度检验的备择假设。选择“H1: Se1≠Se2”,表示进行备择假设为H1: Se1≠Se2的双侧检验。
- Test Type: 表示两组之间比较的统计检验方法,本例选择“Z Test (Pooled)”。
- Power and Alpha:Power为把握度,填写“0.80”;Alpha为检验水准,填写“0.05”。
- Group Allocation: 选择“Equal (N1=N2)”,表示每组的样本量相等。
- P (Prevalence):指定疾病的患病率,范围介于0~1,本例填写“0.3”。
- Se1 (Sensitivity Groups 1 and 2 | H0):表示原假设H0下的灵敏度,即目前方法在两组受试者中的灵敏度。范围介于0~1,本例填写“0.80”。
- Se2 (Sensitivity Group 2 | H1):表示备择假设H1下的灵敏度,即新方法在第二组受试者中的灵敏度。范围介于0~1,本例填写“0.90”。
(三) 脱失率设置
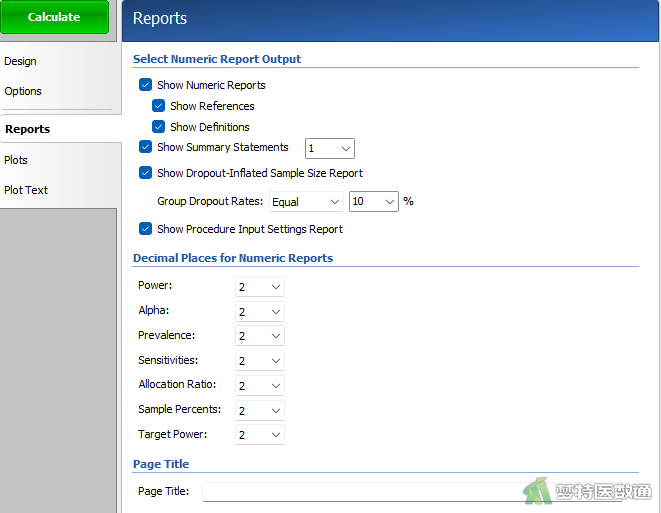
在“Reports (结果报告)”模块中,勾选“Show Dropout-Inflated Sample Size Report (报告脱失样本量)”,在“Group Dropout Rates (各组脱失率)”后选择“Equal (相等)”,填写“10%”(图3),表示两组均按照10%的脱失率计算样本量。设置好上述参数后点击“Calculate (计算)”。
四、结果及解释
图4列出了该研究设计的相关参数和样本量计算结果,可知计算的总样本例数(N)为1326。

图5“References (参考文献)”列出了该计算过程中参考的相关文献;“Report Definitions (报告定义)”列出了各个参数的具体解释;“Summary Statements (报告概述)”为整个分析报告的摘要。

图6中“Dropout-Inflated Sample Size (脱失样本量)”为考虑了脱失率的样本量(N'),也是研究实际开展过程中需要达到的最低样本量,本研究中总共至少需要1474例研究对象。
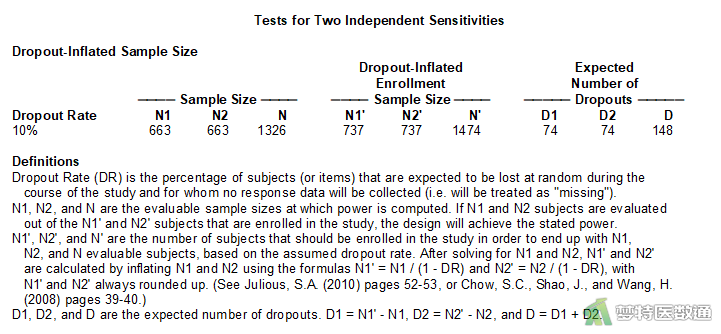
图7为此次样本量估算整个过程的详细参数设置汇总。

五、结论
本研究为平行组设计的灵敏度检验样本含量计算,可通过两独立样本的灵敏度检验法实现。需比较新方法和目前方法的灵敏度,已知目标人群患病率为30%,假设用目前方法的灵敏度为80%,期望新方法的灵敏度能达到90%。若取检验水准0.05、检验功效0.80,每组至少需要663例研究对象。若考虑10%的脱失率,则每组至少需要737例研究对象。