前面文章介绍了“医学研究之两独立样本定性资料样本量计算——率差的置信区间法”。本文将介绍两独立样本率比(相对危险度)的置信区间(Confidence Intervals for the Ratio of Two Proportions)样本量计算。相对危险度(Relative Risk,RR)又称为风险比或率比,是队列研究中暴露组发病率或死亡率与非暴露组发病率或死亡率的比值(φ=π1/π2),说明暴露者发生相应疾病的危险是非暴露者的多少倍。该指标直观易于解释,在大多数情况下,率比往往较率差更具实用性。可根据两组的率及置信区间的相关信息估算样本量,其计算过程及注意事项如下。
一、案例数据
为研究吸烟与冠心病事件发生的关系,研究者开展队列研究,以>40岁人群为研究对象,其中吸烟者作为暴露组,非吸烟者作为对照组。据以往研究可知,预估RR值为1.23,非暴露组发病率为10.2%,希望95%置信区间宽度不超过1.0,暴露组和对照组按非匹配1:2的比例,试估计该研究所需要的样本含量?
二、案例分析
“暴露组”和“非暴露组”是两个独立总体,结局指标为冠心病事件的发病率,希望为比例构建一个双侧95%置信区间,已知率比φ=1.23且置信区间宽度为1.0,宜采用两独立样本率比的置信区间估算样本含量。两独立样本率比的置信区间估算样本含量,需要以下几个参数:
1. 相对危险度RR,即暴露组发病率或死亡率与非暴露组发病率或死亡率的比值,本例φ为1.23。
2. 非暴露组比例π2,本例为非暴露组冠心病事件发病率10.2%。
3. 检验水准α (通常取0.01至0.1,本例取0.05)。
4. 置信区间,置信区间宽度或样本比例到置信区间下限或上限的距离
5. 脱失率DR (通常不宜超过20%,本例取10%)。
三、软件操作
(一) 方法选择
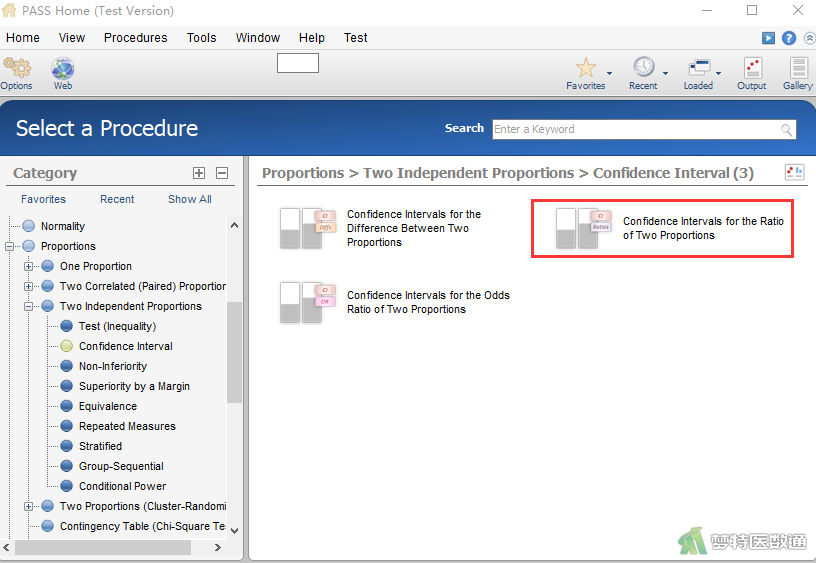
在左侧界面中依次选择“Procedures (程序)”—“Proportions (比例)”—“Two Independent Proportions (两独立样本比例)”— “Confidence Intervals (置信区间)”—“Confidence Intervals for the Ratio of Two Proportions (两独立样本相对危险度的置信区间)”,见图1。
(二) 参数设置
在“Design (设置)”模块中按以下参数设置相应选项(图2):
①Solve For:选择“Sample Size”,表示本分析的目的是用于计算样本量。
②Confidence Interval Method:表示置信区间计算方式,PASS软件有6种公式可以选择,分别为“Score (Farrington & Manning)”、“Score (Miettinen & Nurminen)”、“Score w/Skewness (Cart & Nam)”、“Logarithm (Katz)”、“Fleiss”和“Logarithm+1/2 (Walter)”,本例选择“Score (Farrington & Manning)”。
③One-sided or Two-sided Interval:“Interval Type”区间类型,本例选择“Two-Sided”双侧检验。
④Confidence:“Confidence Level (1-Alpha)”表示置信度,本例填“0.95”。
⑤Sample Size:“Group Allocation”表示研究对象如何分配到不同组别中,根据不同的需求选择,本例中选择“Enter R=N2/N1,solve for N1 and N2”R=2, 暴露组和对照组按非匹配1:2的比例。
⑥Precision:“Confidence Interval Width (Two-Sided)”表示双侧置信区间宽度,即从置信区间下限到上限的距离。该值必须为正数,本例填“1.0”。
⑦Proportions (Ratio=P1/P2):“Input Type”表示输入类型,本例选择“Ratios”比值,“P1/P2 (Ratio of Sample Proportions)”本例输入暴露组冠心病发病率与非暴露组冠心病发病率的比值φ,填“1.23”,“P2 (Proportion Group 2)”本例填写非暴露组冠心病发病率,填“0.102”。

(三) 脱失率设置
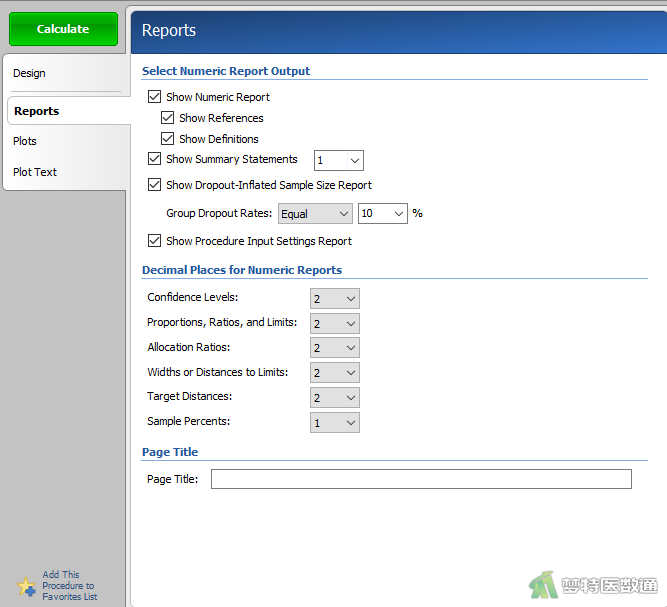
在“Reports (结果报告)”模块中,勾选“Show Dropout-Inflated Sample Size Report (报告脱失样本量)”,在“Dropout Rate”中填写“10%”(图3),表示按照10%的脱失率计算样本量。设置好上述参数后点击“Calculate (计算)”。
四、结果及解释
图4列出了该研究设计的相关参数和样本量计算结果,可知需要822例受试者,其中暴露组N1=274例,非暴露组N2=548例。

图5“References (参考文献)”列出了该计算过程中参考的相关文献;“Report Definitions (报告定义)”列出了各个参数的具体解释;“Summary Statements (报告概述)”为整个分析报告的摘要。

图6“Dropout-Inflated Sample Size (脱失样本量)”为考虑了脱失率的样本量(N'),也是研究实际开展过程中需要达到的最低样本量,需要914例受试者,其中吸烟暴露组N1'=305例、非暴露组N2'=609例受试者。
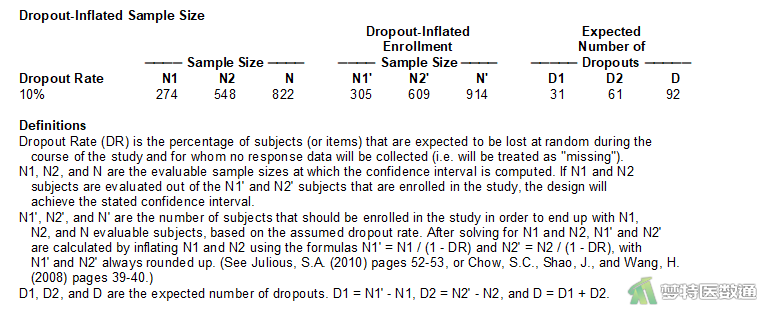
图7为此次样本量估算整个过程的详细参数设置汇总。

五、结论
该案例为两独立样本率比(相对危险度)的置信区间样本量计算,通过以前研究可知暴露组与非暴露组发病率之比为1.23,已知置信度为0.95,置信区间宽度为1.0,则吸烟暴露组和非暴露组分别需要274例、548例受试者。若考虑10%的脱失率,则吸烟暴露组和非暴露组分别需要305例、609例受试者。