在医学研究中,会遇到某些指标,如:抗体滴度,食品、蔬菜、水果中农药的残留量,环境中某些有毒有害物质的含量、某些药物的潜伏期等,常常服从对数正态分布。对于这类指标的检验假设时,使用“比值”比使用“差值”进行检验假设更为方便,可以采用两独立样本平均值比φ的差异性检验 (Tests for the Ratio of Two Means) 的样本量估计功能来估算样本量。本文将用实例演示该方法在两独立样本定量资料样本量估计中的应用、具体计算过程及注意事项。
一、案例数据
某公司研发了两种针对带状疱疹病毒的疫苗,欲检验哪种疫苗效果更佳,以往研究采用平行组设计试验,并用双侧独立样本t检验分析接种者的带状疱疹病毒抗体滴度。根据之前的预试验结果,设定变异系数CV为1.50,φ1为1.50,α=0.05,β=0.10,试估计该研究所需的样本量。
二、案例分析
血清抗体滴度为连续性资料,根据以往经验,血清抗体滴度可认为服从对数正态分布,使用以“比值”表示的假设较为方便,因此采用两独立样本平均值比的差异性检验样本量估计功能估算样本量。需要以下几个参数:
1.真比值φ1,通常为处理组与对照组的总体平均值比,φ1可以为任何正数,一般介于0.5~2.0之间的数值。本例为1.50。
2. 变异系数CV,为标准差与均数的比值,用来描述样本分布的变异程度,本研究中取1.50。
3. 检验水准α (通常取0.01至0.1,本研究取0.05)。
4. 检验功效1-β (通常为0.90或更高,本研究取0.90)。
5. 脱失率DR (通常不宜超过20%,本研究取10%)。
三、软件操作
(一) 方法选择
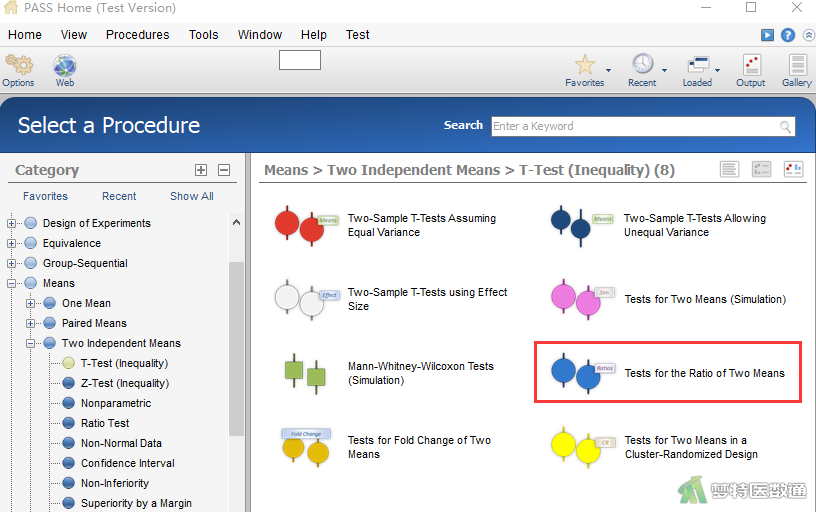
在左侧界面中依次选择“Procedures (程序)”—“Means (均值)”—“Two Independent Mean (两独立样本均值)”—“T-Test (Inequality) (非均衡性检验)”—“Tests for the Ratio of Two Means (两独立样本平均值比的差异性检验)”,见图1。
(二) 参数设置
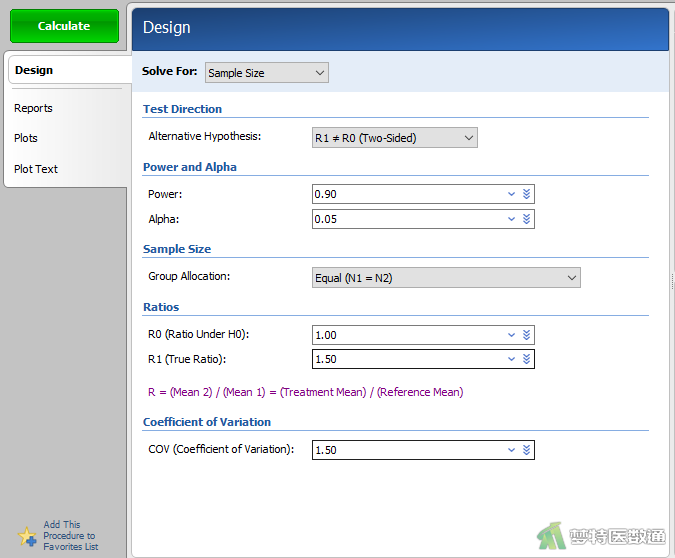
在“Design (设置)”模块中按以下参数设置相应选项(图2):
①Solve For: 选择“Sample Size”,表示分析的目的是用于计算样本量。
②Alternative Hypothesis: 选择“Two-Sided”,用于检验两组平均值是否不同,但预先不指定哪个平均值更大。
③Power and Alpha: Power为把握度,填写“0.90”;Alpha为检验水准,填写“0.05”。
④Sample Size:“Group Allocation”表示研究对象如何分配到不同组别中,根据不同的需求选择,本例中选择“Equal (N1=N2)”处理组和对照组的样本含量相等。
⑤Ratios: R0 (Ratio Under H0): 设定两组平均值比的原假设φ0,通常φ0=1.00,本例为1.00;R1 (True Ration) 真值比,通常表示处理组与对照组的总体平均值比,φ1可以为任何正数。本例为1.50。
⑥Coefficient of variation: COV(Coefficient of variation)为变异系数,本例为1.50。
(三) 脱失率设置
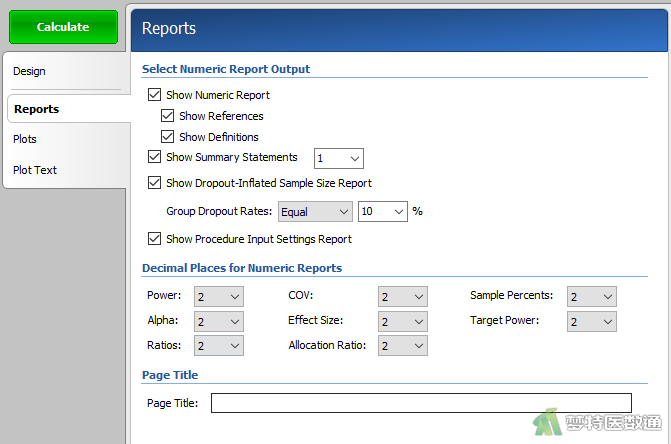
在“Reports (结果报告)”模块中,勾选“Show Dropout-Inflated Sample Size Report (报告脱失样本量)”,在“Dropout Rate”中填写“10%”(图3),表示按照10%的脱失率计算样本量。设置好上述参数后点击“Calculate (计算)”。
四、结果及解释
图4列出了该研究设计的相关参数和样本量计算结果,本研究至少需要304例受试者 (N1=N2=152)。结果如下:

图5“References (参考文献)”列出了该计算过程中参考的相关文献;“Report Definitions (报告定义)”列出了各个参数的具体解释;“Summary Statements (报告概述)”为整个分析报告的摘要。

图6“Dropout-Inflated Sample Size (脱失样本量)”为考虑了脱失率的样本量(N'),也是研究实际开展过程中需要达到的最低样本量,本研究中需要样本含量338 (N1'= N2'=169)例。
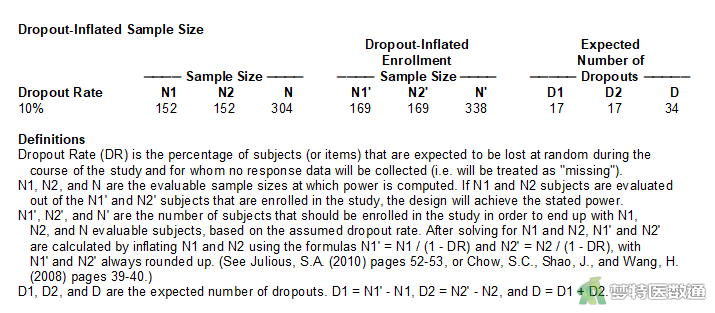
图7为此次样本量估算整个过程的详细参数设置汇总。

五、结论
该案例为两独立样本平均值比的差异性检验样本量计算,CV为1.50,φ1为1.50。若取检验水准0.05、检验功效0.90,要得到两种疫苗产生的抗体滴度不同的结论,则需要304 (N1= N2=153) 例研究对象。若考虑10%的脱失率,则分别至少需要338 (N1'= N2'=169) 例研究对象。