在前面文章中介绍了Kaplan-Meier生存分析(Kaplan-Meier Survival Analysis)的假设检验理论,本篇文章将实例演示在R软件中实现Kaplan-Meier生存分析的操作步骤。
关键词:R语言; R软件; Kaplan-Meier生存分析; 生存分析; KM生存分析; Log-rank检验; 生存曲线
一、案例介绍
某肿瘤研究中心收集了2010年至2015年确诊为宫颈癌的患者生存数据,包括结局(Status:0=删失,1=死亡)、随访时间(Time,月)和组织学分级(Hist_stage:1=原位癌,2=早期浸润癌,3=浸润癌),部分数据见图1,欲探究不同组织学分级的宫颈癌患者的生存结局有无差异。部分数据见图1。本文案例可从“附件下载”处下载。
二、问题分析
本案例的分析目的是比较三种组织学等级的宫颈癌患者的生存结局有无差异,可以采用Kaplan-Meier生存分析。但需要满足4个条件:
条件1:结局为互斥的二分类变量,即删失和死亡,本案例数据满足该条件。
条件2:随访时间或生存时间定义明确,并为量化数据,即以天、周、月、年等为单位的具体数值。本案例数据的生存时间为准确可测量的月数,满足该条件。
条件3:不宜有长期变异存在。对于动态队列,研究对象不是同时进入队列的,那么如果后期进入队列的研究对象使用了新的治疗方案和药物,生存率提高,那么整个队列的生存结果就会发生偏倚。该条件需要根据实际情况来判断,这里默认无长期变异。
条件4:删失事件在各组的分布相似。该条件需要通过软件分析后判断。
三、软件操作及结果解读
(一) 导入数据
mydata <- read.csv("KM生存分析.csv") #导入CSV数据
View(mydata) #查看数据
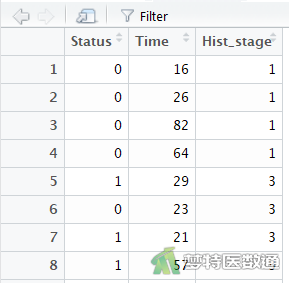
在数据栏目中可以查看全部数据情况,数据集中共有3个变量和3427条观察数据,3个变量分别为结局(Status:删失和死亡)、随访时间(Time)和组织学分级(Hist_stage:1、2、3)。
如果数据集较大也可使用如下命令查看数据框结构:
str(mydata) #查看数据框结构

(二) 条件4判断(删失事件的占比与分布)
1. 软件操作
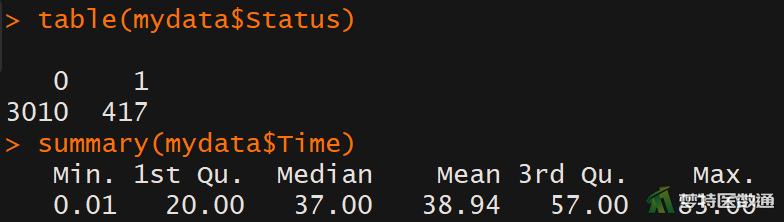
##生存数据统计## table(mydata$Status) summary(mydata$Time)
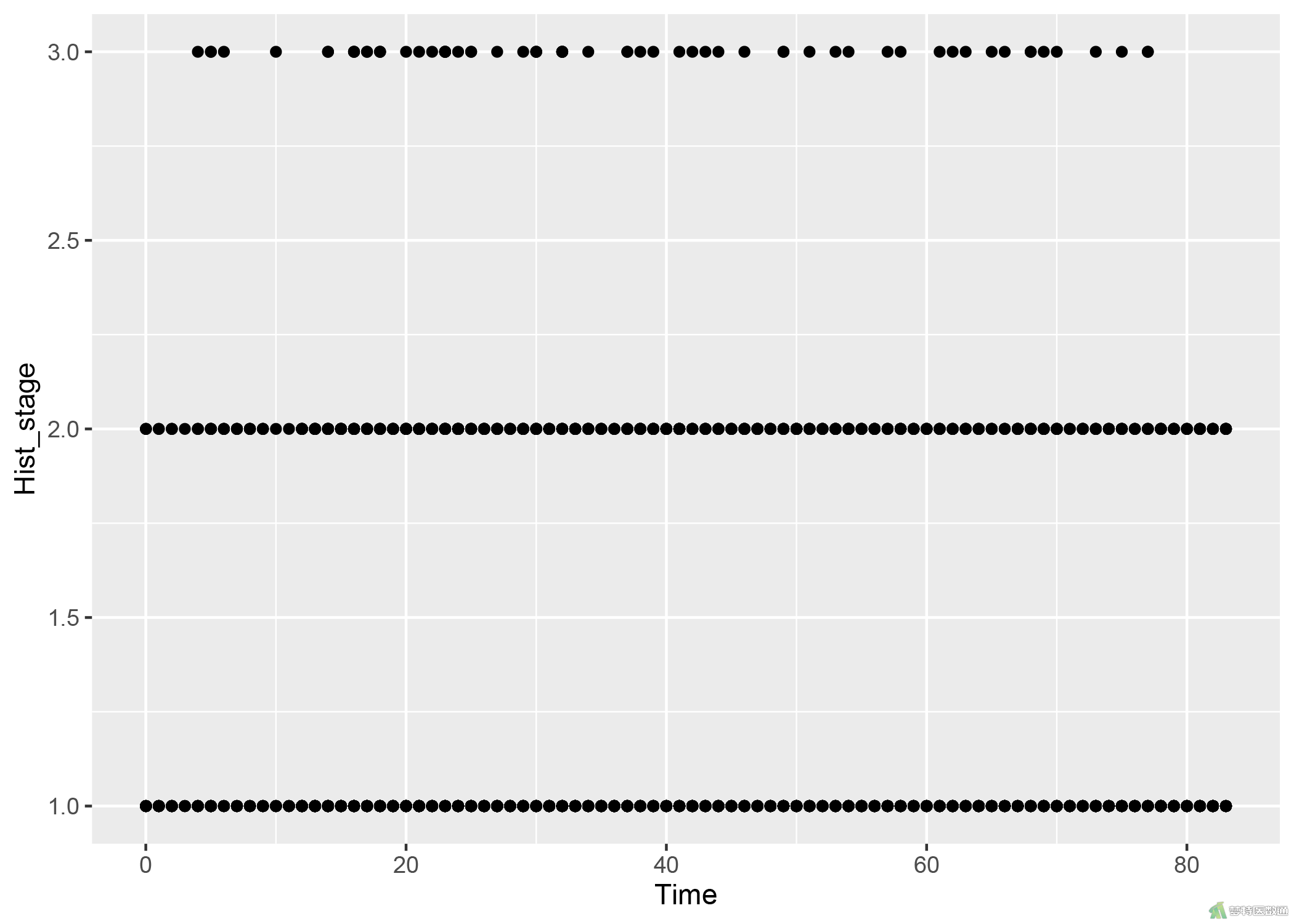
##筛选结局为删失的患者## mydata_censor<-subset(mydata,mydata$Status==0) ##删失数据在不同级别组织中的分布图## library(ggplot2) ggplot(data=mydata_censor,aes(x=Time,y=Hist_stage))+geom_point()
2. 结果解读
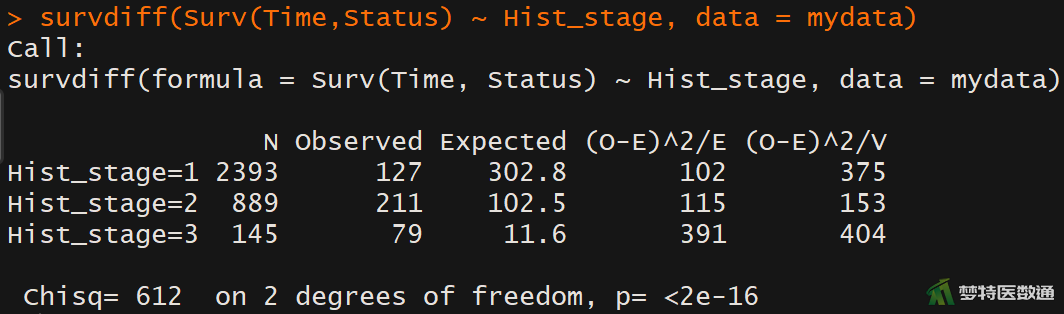
图3中显示,有417个对象发生终点事件,随访时间最长的对象是t=83,图4显示了整个随访期间内不同组织学分级组内删失的分布情况,删失在各组的分布相似,即满足条件4。
(三) 统计学描述及推断
log-rank检验是比较不同组患者生存曲线的非参数检验,属于单因素分析。若想校正其他因素则需要采用Cox比例风险模型进行分析。
1. 软件操作
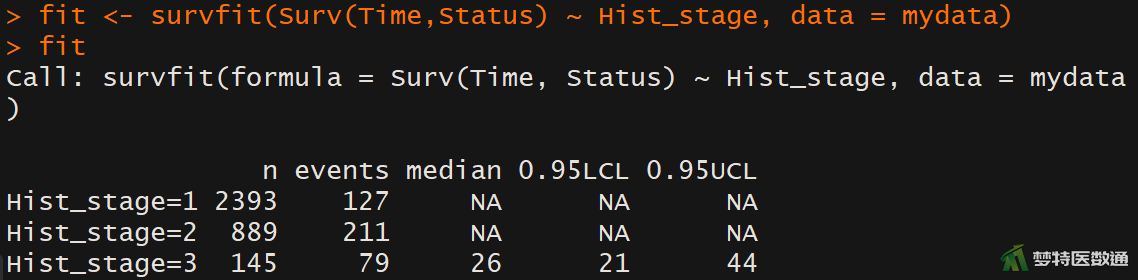
## log-rank检验## library(survminer) #调用包“survminer” library(survival) #调用包“survival” fit <- survfit(Surv(Time,Status) ~ Hist_stage, data = mydata) #模型拟合 fit #查看拟合结果
summary(fit) #详细信息

survdiff(Surv(Time,Status) ~ Hist_stage, data = mydata) #采用log-rank 检验分析生存率差异
##两两比较##
采用pairwise_survdiff()函数进行两两比较
pairwise_survdiff(Surv(Time,Status) ~ Hist_stage, data = mydata, p.adjust.method = 'BH') #采用log-rank 检验分析生存率差异

##绘制生存曲线##
ggsurvplot(fit, data = mydata, conf.int = TRUE, # 增加置信区间
risk.table = TRUE, pval=T) #不同时间点风险人数表,增加P值
2. 结果解读
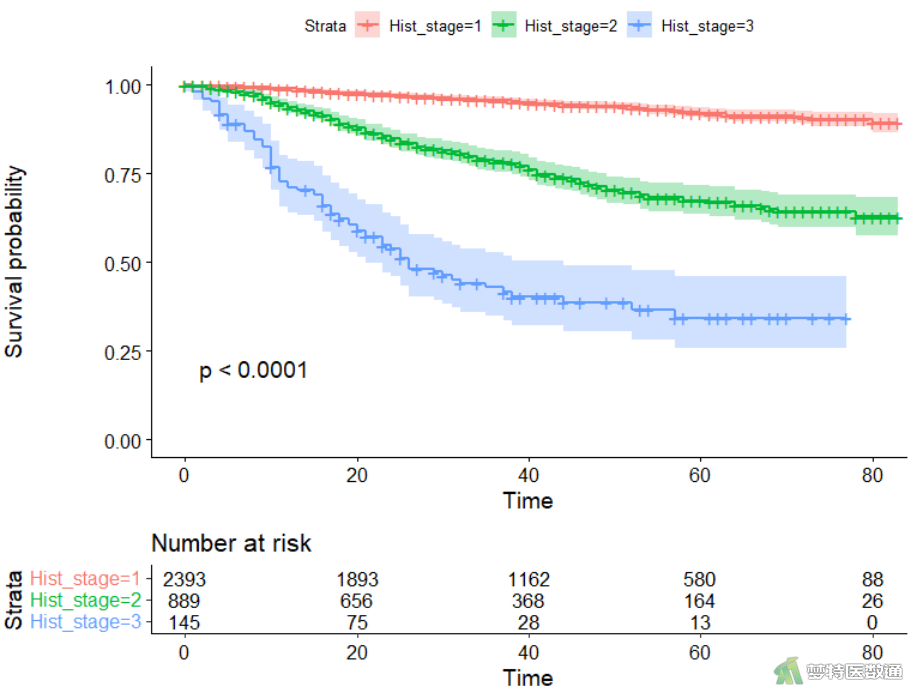
图5为统计学描述的结果,原位癌(Hist_stage=1)患者和早期浸润癌(Hist_stage=2)患者的中位生存时间没有数值,表示这两组患者的死亡人数尚未达到50%;浸润癌(Hist_stage=3)患者的中位生存时间为26 (95%CI:21~44)月。图7为log-rank检验的结果,由结果可知,不同组织学分级的癌症患者的生存分布差异有统计学意义(log rank检验:χ2=612,P<0.001)。图9为Kaplan-Meier生存曲线图。Kaplan-Meier生存曲线也表明,三组患者的生存分布有差异,需进行两两比较。两两比较的结果如图8所示,三组患者两两之间的生存分布差异均有统计学意义(log rank检验:P<0.001)。即,组织学分级为3的患者的生存概率要低于同一时间段内的分级为2的患者,而分级为2的患者低于分级为1的患者。
四、结论
本研究采用Kaplan-Meier曲线和log-rank检验对不同组织学分级的宫颈癌患者的生存结果进行比较。不同组织学分级组内删失值分布情况类似。原位癌(Hist_stage=1)患者和早期浸润癌(Hist_stage=2)患者的中位生存时间没有数值,表示这两组患者的死亡人数尚未达到50%;浸润癌(Hist_stage=3)患者的中位生存时间为26 (95%CI:21~44)月。Log-rank检验结果表明不同组织学分级的癌症患者生存分布的差异有统计学意义(χ2=612,P<0.001)。进一步进行事后两两比较,结果显示三组癌症患者生存分布差异均有统计学意义(P<0.001),原位癌患者生存状况最好,早期浸润癌患者次之,浸润癌患者最差。
五、知识小贴士
(一) 删失数据
在规定的随访期内,未能观察到一些研究对象结局事件的发生,即不能得知结局事件确切的发生时间,称这类研究对象的随访时间/生存时间为删失数据,根据原因可分为三种类型:①研究结束时(已达到规定的最长观察期/随访期),研究对象仍未出现结局事件;②由于研究对象在研究期间不再继续就诊,或拒绝访视,或失去联系等,未能观察到结局事件;③研究对象出现了竞争事件(如其他原因的死亡),观察不到既定的结局事件而终止随访。
(二) 中位生存时间
中位生存时间表示累积生存率为50%所对应的时间,是生存分析中最常用的概括性统计量。生存分析中较少使用平均生存时间。
(三) log-rank检验
Log-rank检验中的“log”并非为“对数”,而是表示“count”、“register”或“record”。在中文描述中可以直接写为“log-rank检验”,或者译为“时序检验”。
Log-rank检验是比较不同组患者生存曲线的非参数检验,属于单因素分析。若想校正其他因素则需要采用Cox比例风险模型进行分析。