关键词:R语言; R软件; R软件个案合并; R软件变量合并; R软件数据筛选
数据集的合并包括样本的合并(向数据框中添加行)和变量的合并(向数据框中添加列),下面将演示样本合并和变量合并的操作步骤过程:
一、样本合并
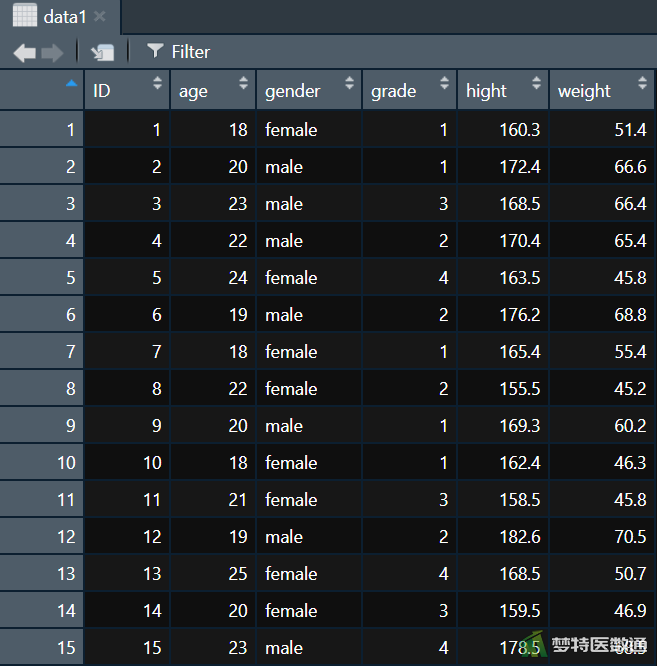
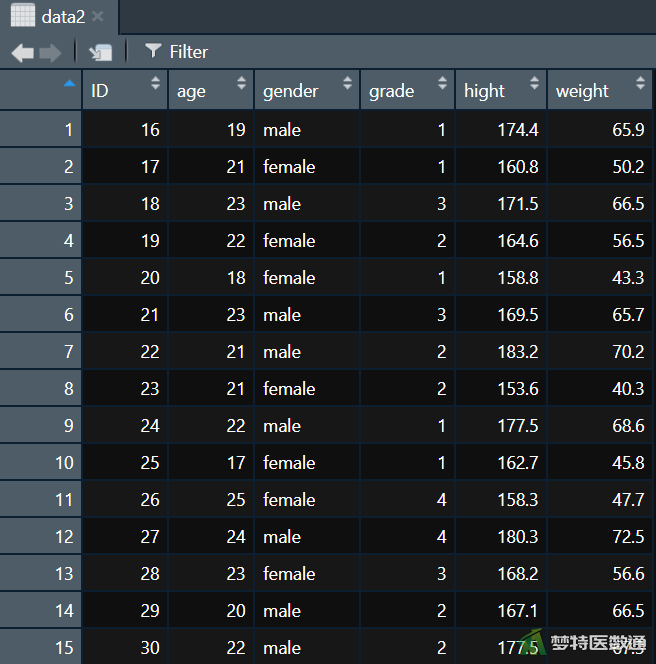
假设“data1.csv”数据集中记录了ID为1~15的15名研究对象的“age (年龄)”、“gender (性别)”、“grade (年级)”、“hight (身高)”和“weight (体重)”5个变量数据,“示例数据2.csv”数据集中记录了ID为16~30的15名研究对象的“age”、“gender”、“grade”、“hight”和“weight”5个变量数据,现需要将两个数据集的样本数据进行合并。
①首先按照以下语句将“data1.csv”、“data2.csv”文本文件分别读入成数据框:
data1 = read.table("data1.csv", header = TRUE, sep = ",")
data2 = read.table("data2.csv", header = TRUE, sep = ",")
如图1、2所示:
②要纵向合并两个数据集(数据框),可以使用rbind()函数:
total = rbind(data1, data2) head(total[13:18, ])
可生成一个名为“total”的合并数据集,结果如图3所示:

需要注意的是,两个数据框必须拥有相同的变量,对数据的变量顺序没有特殊要求。
二、变量合并
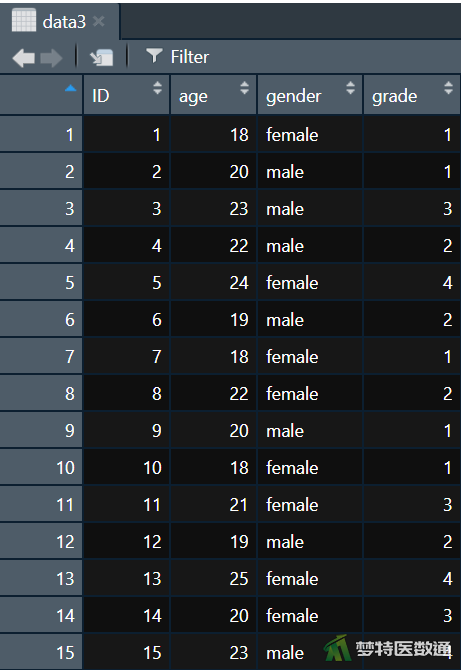
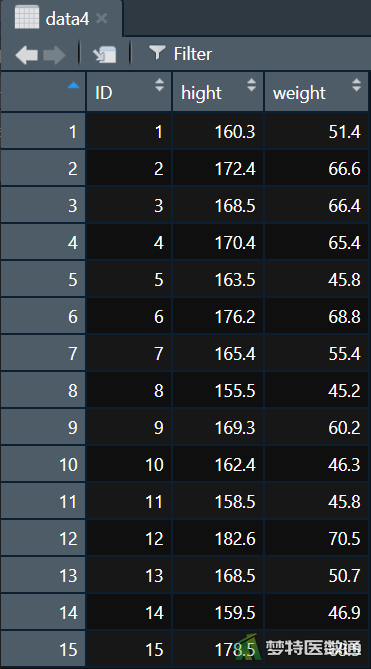
假设“data3.csv”数据集中记录了ID为1~15的15名研究对象的“age”、“gender”和“grade”3个变量数据,“data4.csv”数据集中记录了ID为1~15的15名研究对象的“hight”和“weight”2个变量数据,现需要将两个数据集的变量数据进行合并。
①按照上述数据读取方法同时打开“data3.csv”和“data4.csv”,并命名为data3和data4。
data3 = read.table("data3.csv", header = TRUE, sep = ",")
data4 = read.table("data4.csv", header = TRUE, sep = ",")
如图4、5所示:
②通过merge()函数对两个数据集进行横向的合并,通常使用一个或多个共有变量进行联结:
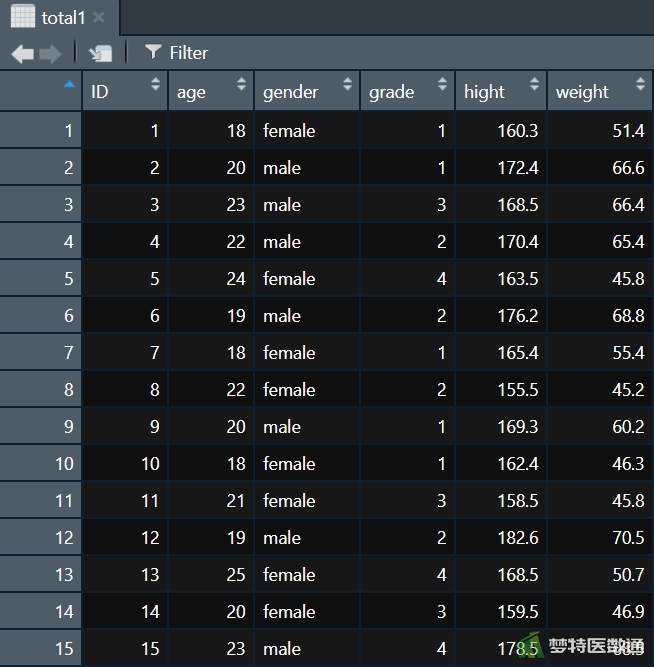
total1 = merge(data3, data4, by = "ID") head(total1[1:3,])
结果如图6所示:
若要直接横向合并两个数据框而不指定一个公共索引,可以使用cbind()函数。如:
total2 = cbind(data3, data4)
使用此方法需要特别注意的是,合并之前必须确保两个数据集中样本例数的ID有相同顺序的排序,且必须拥有相同的行数。
三、数据筛选
在数据分析过程中,有时需要选择一部分数据进行分析,即选择满足一定条件的样本,比如,选择血红蛋白浓度大于160 g/L的样本人群,选择年龄大于60岁的样本人群。可以利用条件抽取、挑选出或删除符合/不符合一定条件的样本,如删除有缺失值的样本。
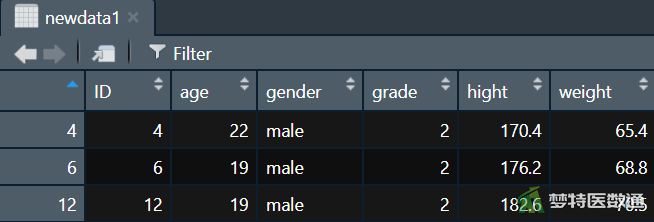
①可以使用条件语句对数据进行筛选。以“data1”演示筛选出“gender”中为“male”以及“grade”中为“2”的样本:
attach(data1) newdata1 = data1[gender == "male" & grade == "2",] detach(data1)
结果如图7所示:
②使用subset()函数:
newdata2 = subset(data1, gender == "male" & grade == "2")