关键词:R语言; R软件; R软件数据导入; R软件数据读取; R软件文件格式; R软件结果保存
一、数据的读取
R提供了适用范围广泛的数据导入工具。向R中导入数据的权威指南参见R Data Import/Export手册。在这里,仅介绍几种最常见的数据读取方式。
(一)导入带分隔符的文本文件数据
可以使用read.table()函数读取带分隔符的文本文件。其语法示例如下:
mydataframe <- read.table(file, options)
其中,file是一个带分隔符的ASCII文本文件(如.txt、.csv文件等),options是控制如何处理数据的选项。图1列出了常见的选项。查看help(read.table)可获得更多细节。
考虑一个示例数据文件,名为data1.txt的文本文件,存放于工作目录下。该文件的第一行为变量名,用空格分开(如图2所示)。
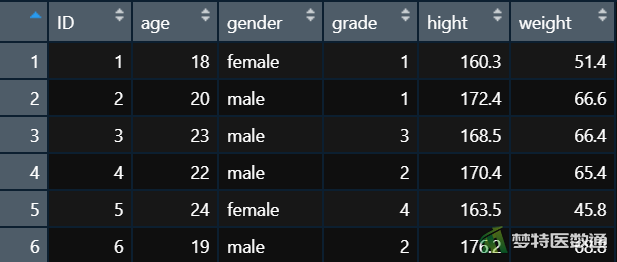
该文本文件可用以下语句来读入成一个数据框:
mydataframe1<- read.table("data1.txt", header = TRUE)
读取后的数据在R中如图3所示。
(二)导入Excel数据
读取一个Excel文件,可以在Excel中将其另存为一个逗号分隔文件(.csv),并使用read.table()函数或者read.csv()函数读取文件。
考虑一个示例数据文件,名为data1.csv的文本文件,存放于工作目录下。该文件的第一行为变量名,用逗号分开(如图4所示)。
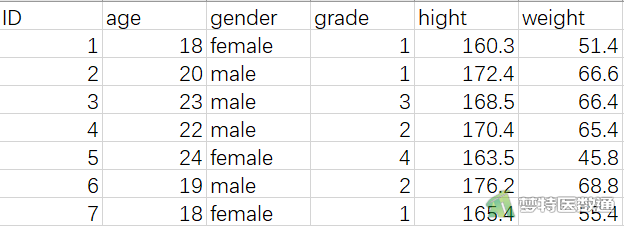
该文件可用以下语句中的任意一个来读入成一个数据框:
mydataframe2 <- read.table("data1.csv", header = TRUE, sep = ",")
mydataframe2 <- read.csv("data1.csv", sep = ",")
读取后的数据在R中如图5所示。
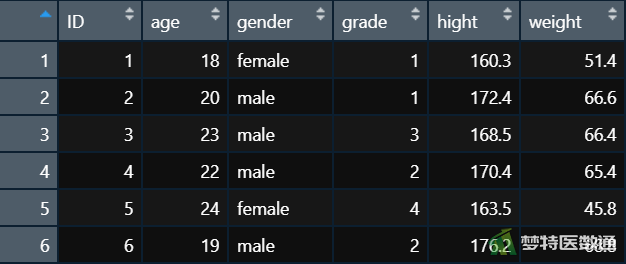
(三)导入SPSS数据
IBM SPSS数据集可以通过foreign包中的read.spss()函数导入到R中,也可以使用Hmisc包中的spss.get()函数。spss.get()函数是对read.spss()函数的一个封装,它自动设置了许多参数,让整个转换过程更加简单一致。
首先,下载并安装Hmisc包(foreign包作为支持包会被默认安装):
install.packages("Hmisc") #安装"Hmisc"包
然后使用以下代码导入数据:
library(Hmisc) #启用"Hmisc"包
mydataframe3 <- spss.get("data1.sav", use.value.labels = TRUE)
这段代码中,data1.sav是要导入的SPSS数据文件,use.value.labels = TRUE表示将带有值标签的变量导入为R中相对应的因子。
(四)导入SAS数据
SAS数据集可以通过foreign包中的read.ssd()函数导入到R中,也可以使用Hmisc包中的sas.get()函数。使用以下代码导入数据:
mydataframe4 <- sas.get(libraryName = "datadir", member = "data1", sasprog = "sasexe")
这段代码中,libraryName是数据集的路径名,member是数据集名,sasprog是SAS可运行程序的完整路径。查看help(sas.get)获得更多细节。示例:
library(Hmisc) #启用"Hmisc"包
mydataframe4 <-sas.get(libraryName = "./",
member = "data1",
sasprog = "D:/SAS92/SASFoundation/9.2/sas.exe")
也可以在SAS中使用PROC EXPORT将SAS数据集保存为一个逗号分隔的csv文本文件,并使用(二)中的方法读取到R中。
(五)导入Stata数据
Stata数据集可以通过foreign包中的read.dta()函数导入到R中。使用以下代码导入数据:
library(foreign) #启用"foreign"包
mydataframe5 <- read.dta("data1.dta")
二、结果的保存
在R中,数据分析结果保存的方法是多样的,可以手动摘录,也可以通过代码进行保存,这里简单列举3种情况和对应的程序包及函数。
(一)保存整理好的数据
可以使用save()函数将R中的数据保存为.RData格式文件,可以是待分析的数据,也可以是经过提取、组合成的回归分析结果等,如:
save(mydataframe1, file = "./mydata1.RData")
若想将数据保存为.csv文本文件,可以使用基础函数write.csv()保存已经整理好的数据框。使用以下代码将数据保存在当前工作目录下:
write.csv(mydataframe1, file= "./mydataframe.csv", row.names = F)
其中,row.names = F表示不保存R数据中的行变量名。
(二)保存描述性分析的结果
对于研究对象特征的描述或组间比较,可以使用CompareGroups包中的createTable()和compareGroups();对于描述的结果,可以使用export2word()等函数进行保存,可以保存为word文档、pdf文件或者excel文件等。例如:
install.packages("compareGroups") #安装"compareGroups"包
library(compareGroups) #启用"compareGroups"包
##把分类变量转换成因子##
mydataframe1$gender <- factor(mydataframe1$gender) mydataframe1$grade <- factor(mydataframe1$grade)
##按性别分组进行统计描述与比较,并将结果导出为word文档##
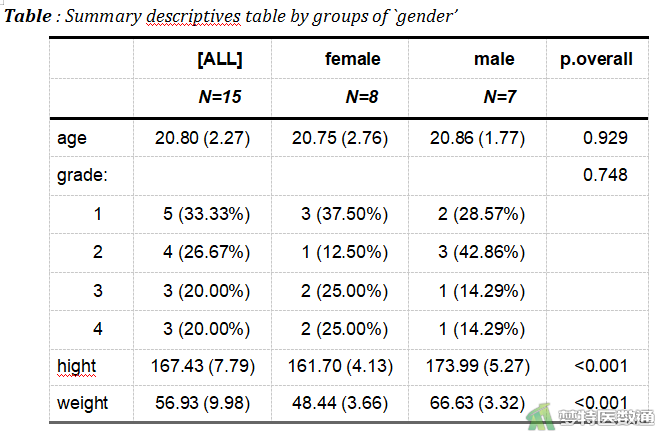
Table1 <- createTable (compareGroups(gender~age + grade + hight + weight, data = mydataframe1), show.all = T, digits = 2) export2word(Table1, "Table1.docx")
show.all = T表示展示全部样本信息;digits = 2表示保留两位小数。结果如图6所示。
(三)保存图片
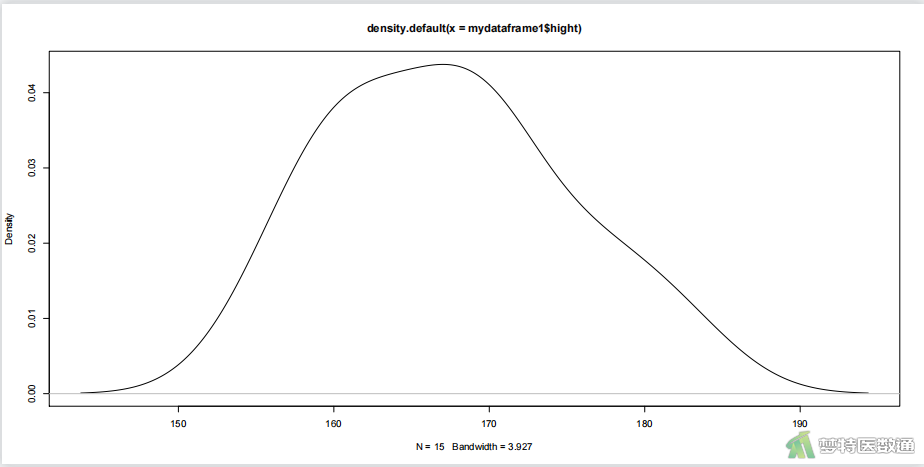
当完成绘图后,可以使用基础函数pdf()、png()、tiff()或者ggplot2中的ggsave()对图片进行保存,例如,绘制身高分布图并保存为PDF格式:
pdf("height.pdf", width = 16, height = 8)
plot(density(mydataframe1$hight)) #绘制身高分布图
dev.off() #关闭图形设备
结果如图7所示。