在前面文章中介绍了单样本Wilcoxon符号秩检验(One Sample Wilcoxon Signed Rank Test)的假设检验理论 ,本篇文章将实例演示在SAS软件中实现单样本Wilcoxon符号秩检验的操作步骤。
关键词:SAS; 非参数检验; 秩和检验; 单样本Wilcoxon符号秩检验; 单样本秩和检验
一、案例介绍
某地正常人尿氟含量的中位数为45.20μmol/L。今在该地某厂随机抽取12名工人,测得尿氟含量。问该厂工人的尿氟含量是否与当地正常人的尿氟含量有差异?部分数据见图1。本文案例可从“附件下载”处下载。
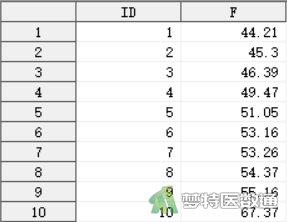
二、问题分析
本案例的分析目的是比较研究样本的水平是否与已知的总体中位数有差异,属于单样本设计的假设检验范畴。计量资料的单样本设计假设检验,主要有单样本t检验和单样本Wilcoxon符号秩检验。对于计量资料,若不满足正态性或数据分布情况未知以及一端或两端是不确定数值时,应选用秩转换的非参数检验更为恰当。对于等级资料,常用非参数检验。
对于本研究案例,首先进行正态性检验,若发现不服从正态分布,则应选用单样本Wilcoxon符号秩检验。
三、软件操作及结果解读
(一)导入数据
①利用LIBNAME语句建立SAS逻辑库关联,注意逻辑库名称要求,即最大长度8字符,必须以字母或下划线“_”开始,可以是字母、数字和下划线的任意组合。具体代码如下:
libname mydata 'D:\mydata';
通过这一步骤,SAS能够识别引号中的物理位置,将逻辑库建立在该目录下,同时在以下过程中新建的SAS表格便可以永久储存在该位置,便于反复读取和使用。先运行该代码使其生效。
②利用PROC IMPORT语句导入文件,代码如下:
proc import out= mydata.example datafile=" D:\mydata\单样本Wilcoxon符号秩检验.csv" dbms=csv replace; getnames=yes; run;
该过程在mydata逻辑库中生成example数据集,数据文件由DATAFILE=选项指定,DBMS=选项指定其数据库类型。该案例中初始数据集为csv文件,故而使用“dbms=csv”指定。如果已经存在相同名称的SAS数据集,即可使用REPLACE选项进行覆盖。GERNAMES=YES选项指定从第2行开始读取数据,将数据集的首行变量名作为SAS数据集的变量名。
(二) 适用条件判断(正态性检验)
1. 软件操作
运用UNIVARIATE 过程进行正态性检验,示例代码如下:
proc univariate data= mydata.example plot normal; var F; Histogram /normal kernel; run;
其中“mydata.example”为上一步中导入的数据集名称,“F”为分析变量名,即该厂工人的尿氟含量。选项PLOT产生了平行条状图,箱线图和正态概率图,如图2所示。

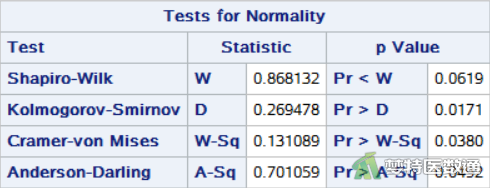
选项NORMAL进行正态性检验,得到“Normality Test (Shapiro-Wilk) (夏皮罗-威尔克正态性)”检验结果,如图3所示。
HISTOGRAM语句可以可以针对指定变量“F”绘制直方图,该语句中NORMAL选项可作正态分布的密度曲线,而KERNERL选项可作基于数据的核分布密度曲线,可直观展示变量的分布情况,如图4所示。

2. 结果解读
正态性检验结果如图3所示,“Normality Test (Shapiro-Wilk) (夏皮罗-威尔克正态性)”结果为P=0.0619<0.1,提示数据不服从正态分布;图2 Q-Q图上散点与对角线的分布重合度较低,且图4 中数据的核分布密度曲线与正态分布密度曲线重合度较低,也可以认为数据不服从正态分布。所以本案例宜选用单样本Wilcoxon符号秩检验。
(三)统计描述及推断
1. 统计描述
(1) 软件操作
上一步骤中的UNIVARIATE过程即可给出详细的统计学描述信息(图5):
proc univariate data= mydata.example plot normal ; var F; Histogram /normal kernel; run;

(2) 结果解读
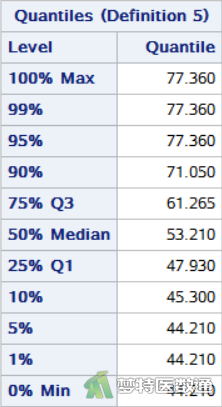
图5为“Basic Statistical Measures (基本统计描述)”结果,包括变量“F”的“N (样本量)”、“Mean (均数)”、“Median(中位数)”、“Std Deviation (标准差)”和“Interquartile Range(四分位间距)”等指标。由正态性检验结果可知,该数据不满足正态分布,所以采用中位数(四分位间距)描述数据,可知该地某厂工人的尿氟含量为53.210 (13.335) μmol/L。
另外,该步骤还给出该组数据的“min(最小值)”、“max(最大值)”、“25% Q1(第1四分位数)”、50% Median(中位数)和“75% Q3(第3四分位数)”等结果(图6),故而该厂工人的尿氟含量也可表示为53.210 (Q1~Q3:47.930~61.265) μmol/L。
2. 统计推断
(1) 软件操作
UNIVARIATE过程也可得到检验结果:
proc univariate data= mydata.example plot normal Mu0=45.20; var F; Histogram /normal kernel; run;
添加选项Mu0=,该选项指定了秩和检验中原假设的总体中位数参数值。由于需要判断本案例中某厂工人尿氟含量“F”的中位数与某地正常人尿氟含量中位数45.20 μmol/L是否一致,故而设定“Mu0=45.20”。
注意:此时Mu后面是数字 “0”,而不是英文字母 “O”。
(2) 结果解读
由统计学描述信息可知,本案例中某厂工人尿氟含量“F”的中位数为53.21 μmol/L,而某地正常人尿氟含量中位数为45.20 μmol/L,可以粗略看出存在差异,但究竟有无统计学意义还要看统计检验结果。
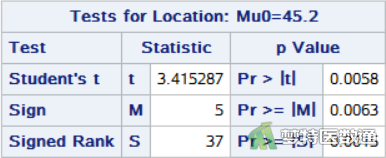
图7给出了“Tests for Location (位置检验)”的三种不同方法和结果。由于该案例数据为非正态分布,参考单样本Wilcoxon符号秩检验,即“Signed Rank (符号秩检验)”结果,检验统计量S = 37, P= 0.0015 < 0.05,差异有统计学意义,故可以认为该厂工人的尿氟含量与当地正常人的尿氟含量水平有差异。
如果本案例采用单样本t检验,则参考图7中“Student’s t (Student t 检验)”结果,为t = 3.415,P= 0.0058<0.05,检验结论与Wilcoxon符号秩检验一致。
注意:SAS中“Signed Rank (符号秩检验)”所使用的公式与SPSS所使用的公式不同,在原本秩次的基础上,需减去n(n+1)/4,这里的n是指不等于Mu0的样本量,即不等于45.20的样本量,所以SAS中需要减去12(12+1)/4=39,即S=76-39=37。
四、结论
本研究欲比较某厂工人的尿氟含量与当地正常人的尿氟含量水平是否存在差异,对该厂工人的尿氟含量进行正态性检验发现不服从正态分布,故选用单样本Wilcoxon符号秩检验。
经分析,该厂工人的尿氟含量为53.210 (Q1~Q3:47.930~61.265) μmol/L。采用单样本Wilcoxon符号秩检验分析显示:检验统计量S = 37, P= 0.0015 < 0.05,差异有统计学意义。本研究结果提示该厂工人的尿氟含量高于当地正常人的尿氟含量水平。