聚类分析(Cluster analysis)能够对样品或变量按照其各自的特性和属性进行合理的分类,进而深入认识和研究各类别特征。但聚类过程中存在一个明显的缺点,即“无论数据中是否真正存在不同的类别,利用聚类分析总能得到将其拆分为若干类的结果”。因此,在聚类分析之后需要对结果的有效性加以验证。
关键词:SPSS; 聚类分析; 结果验证; 自动优化
一、聚类结果的验证方法
聚类结果的有效性验证是聚类分析的关键环节。一般而言,可以考虑用下列方式进行验证。
方法1:关键变量的分类别描述。聚类结果中,如果在专业上比较重要的一些变量在各类别间的分布无明显差异,则有理由怀疑聚类结果的有效性。
方法2:各变量的类间比较。在理想的情况下,用于聚类分析的所有变量在各类间均有差异。此方式可以在保存了聚类结果变量之后使用独立样本t检验或者单因素方差分析来考察,也可以在聚类时直接使用“选项”子对话框中的“ANOVA”复选框来得到相应的比较结果。
方法3:回代验证。将聚类结果作为因变量建立判别方程,如果对各类别进行判别的回代正确率都非常高,那么就有较大的把握认为这些类别是客观存在且存在明显差异的。
方法4:异常值查验。一般总是希望聚类结果在各个类别中包含的案例数量不要差异悬殊,如果某一聚类结果案例过于集中在某一类,则有理由怀疑其结果的“有用性”。例如,在聚类分析中绝大多数的样本被聚为一类,其余多个类别则只包含较低比低的样本,一般是不合格的聚类结果。
方法5:不同方法比较验证。可以对同一数据集使用不同的方法(如同时使用快速聚类法和两步聚类法)进行聚类,然后对两个结果进行比较。如果两个结果在类别中的分布及特征方面存在很大差异,则有理由怀疑聚类结果的“稳定性”。该方法是目前较好的一种聚类结果验证方法。
方法6:同一方法相互验证。如果数据量较大,可以把一个数据集按照一定比例(如1:1或3:2)随机拆分成两个数据集,然后用同一种方法分别对两个数据集进行聚类。如果两个结果在类别数量、类别特征等方面有很大差异,则有理由怀疑聚类结果的“可靠性”。
二、案例介绍
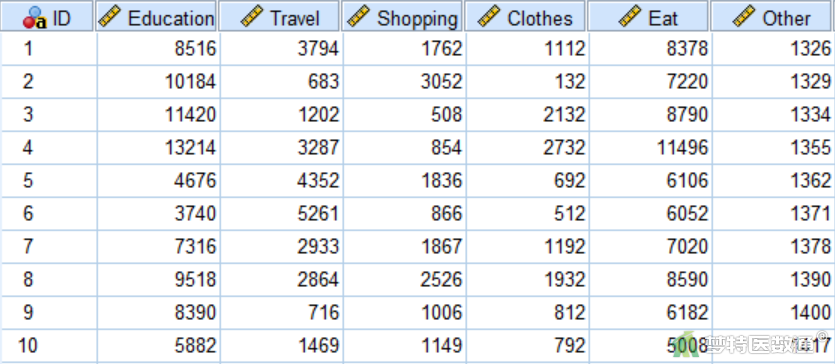
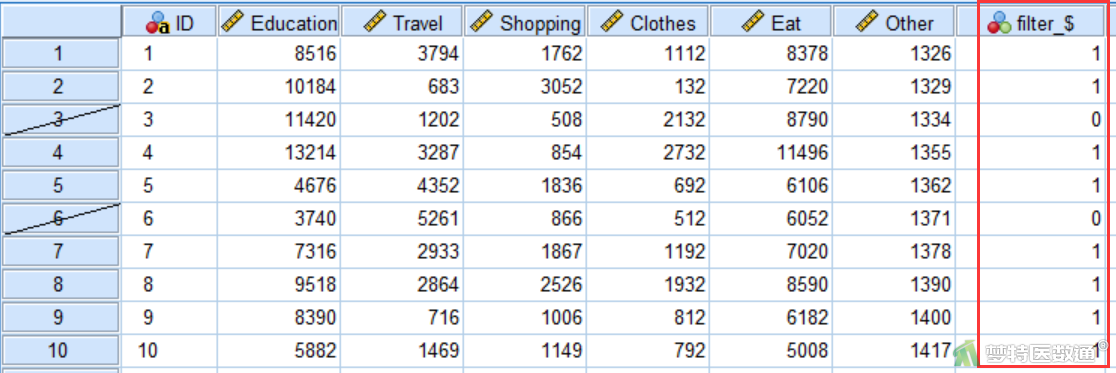
使用快速聚类(Quick Clustering)——SPSS软件实现一文案例,某研究调查了2890名居民的家庭月开支情况,包括教育(Education)、旅游(Travel)、购物(Shopping)、购衣(Clothes)、饮食(Eat)和其他(Other)。根据上述6个方面的开支情况将研究对象分为“低水平消费群体”,“中等水平消费群体”,“中上等消费群体”和“高水平消费群体”共4个群体。部分数据见图1,试对聚类结果进行验证。本案例数据可从“附件下载”处下载。
本文主要演示“各变量的类间比较”和“同一方法相互验证”两种验证方法。
三、各变量的类间比较验证
(一) 软件操作
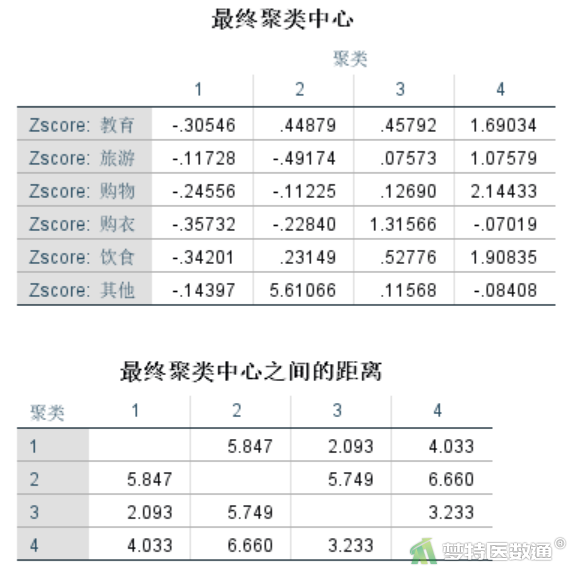
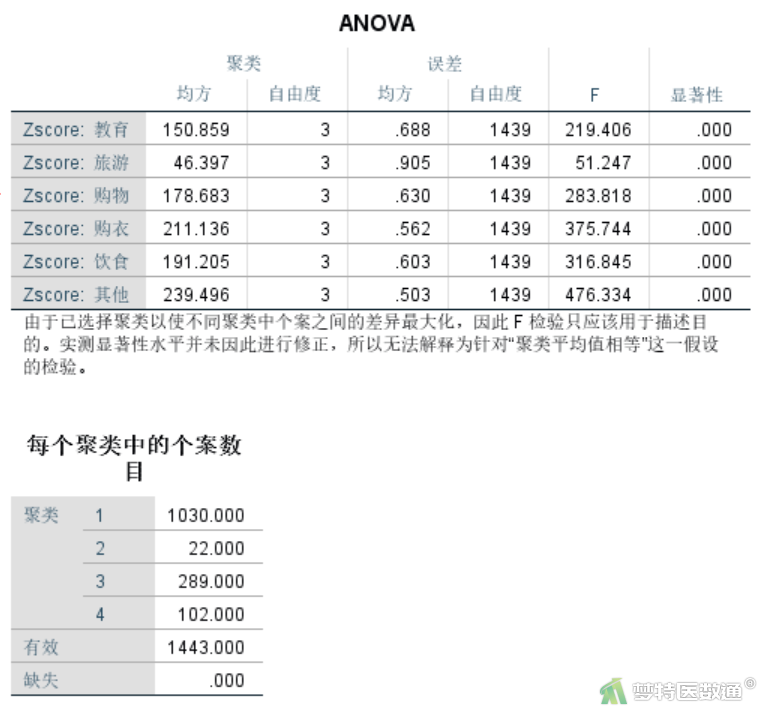
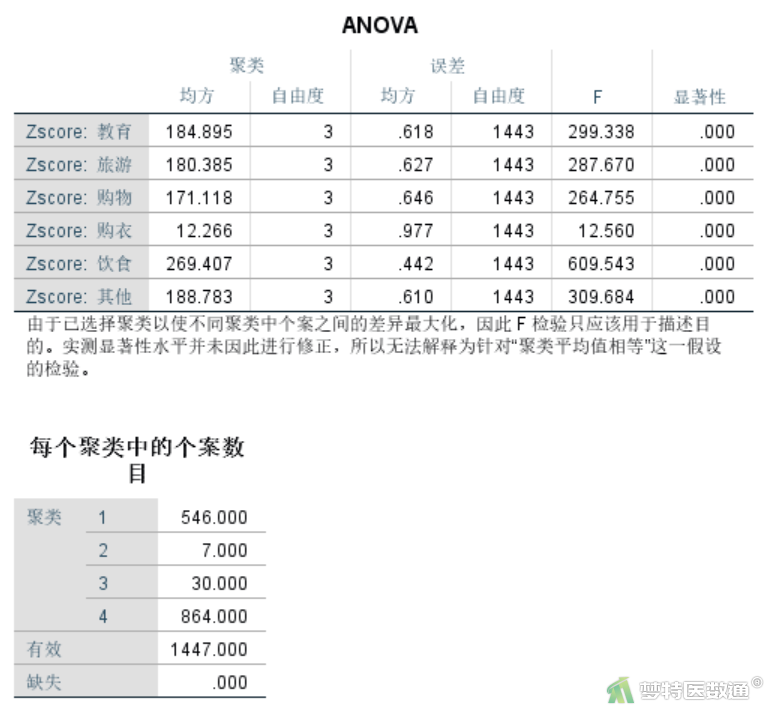
此处可采用K-均值(K-means)聚类方法进行快速聚类,在聚类时直接使用“选项”子对话框中的“ANOVA”复选框来得到相应的比较结果。详细操作详见快速聚类(Quick Clustering)——SPSS软件实现一文。对聚类的4个类别进行单因素方差分析结果如图2所示。
(二) 结果解读
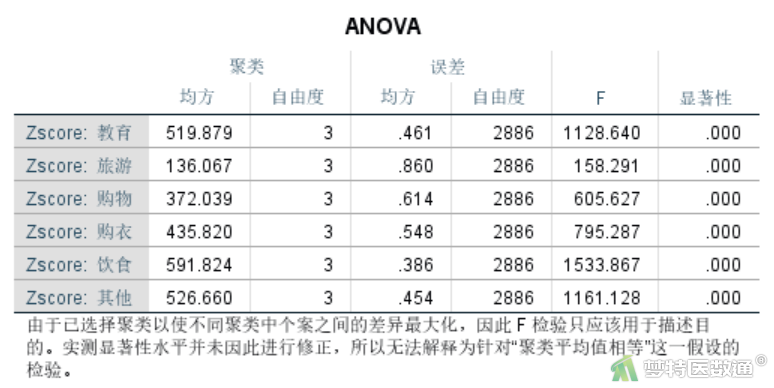
ANOVA结果(图2)显示6种家庭月开支情况在4个类别间的方差分析情况,6个检验的P值均< 0.05,说明6方面的家庭月开支在4个聚类间的差异均有统计学意义,说明这6方面的开支对聚类结果均发挥作用。提示所得到的聚类结果具有一定可信度。
四、同一方法相互验证
(一) 软件操作
将数据集随机拆分为2个子集,比较其聚类结果。
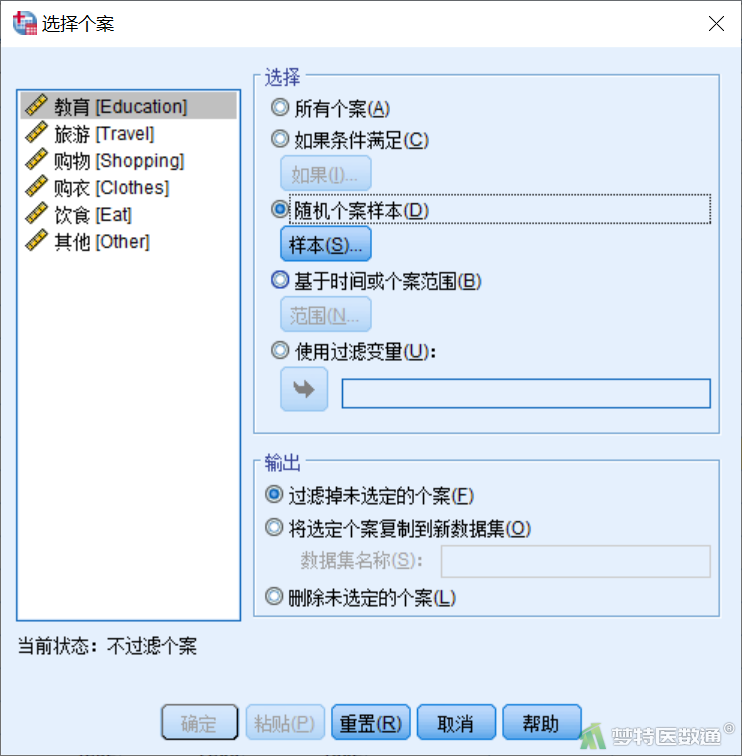
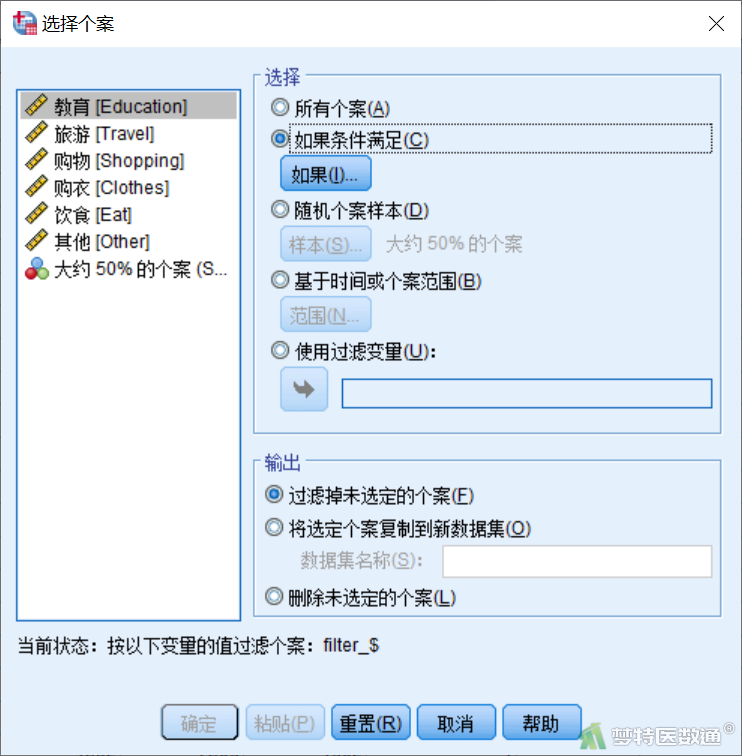
①选择“数据”—“选择个案”,弹出“选择个案”对话框,选择“随机个案样本”(图3)。
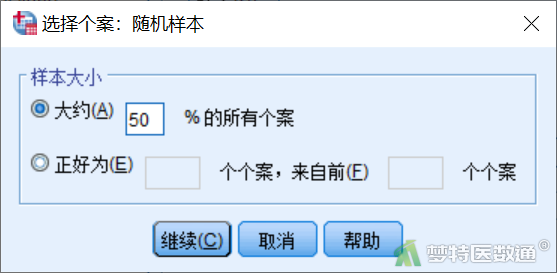
② 选择“样本”,在“选择个案:随机样本”对话框中的样本尺寸中,有2种方法随机选择样本,“大约”表示样本将粗略地按照设定的比例拆分成2部分;“精确”表示样本将精确地按照设定的参数拆分成2部分。本例选择“大约”,并填写“50”,表示2个数据集的样本分别占总样本的50%左右(图4)。
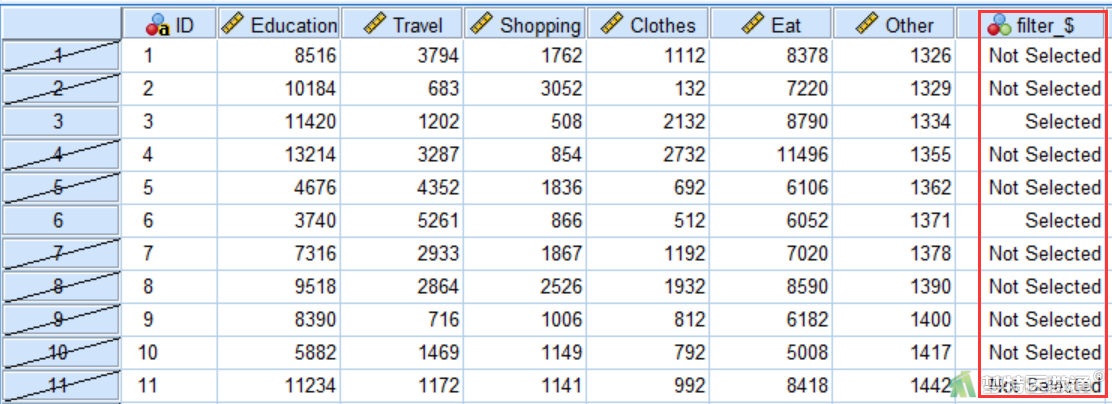
数据视图(图5)页面生成了一列新的变量“filter_$”,其中1表示选中的案例,0表示未选中的案例,由此可表示数据已经分为2个子集。
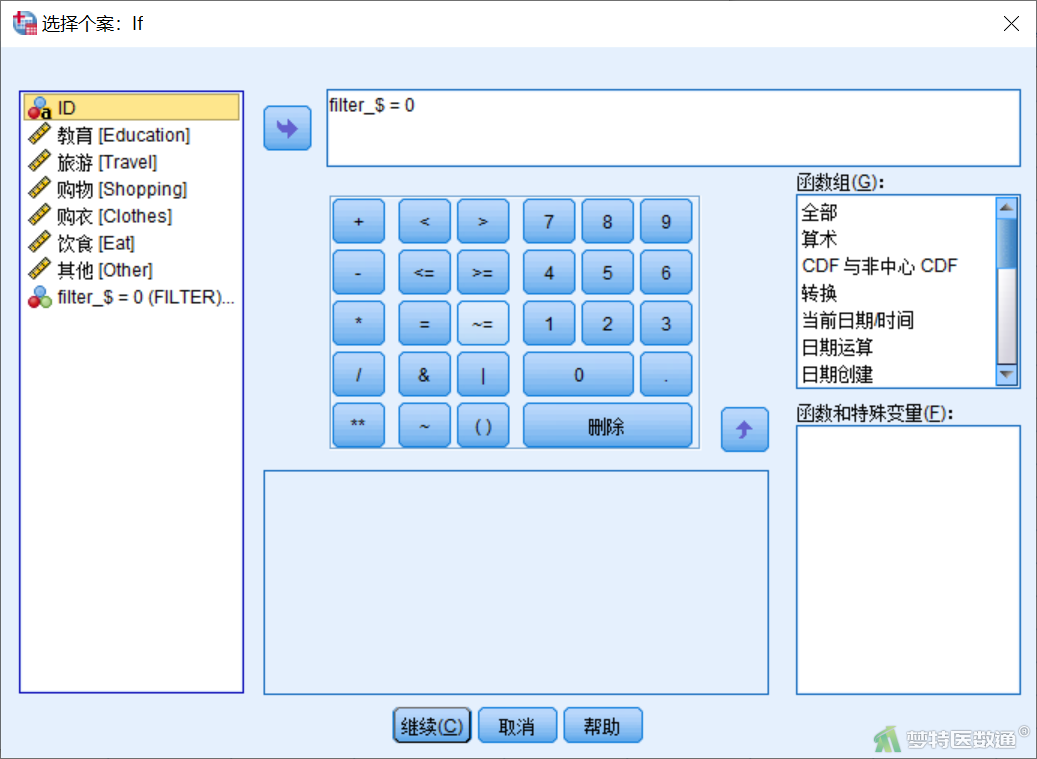
③ 在“选择个案”对话框中选择“如果条件满足” (图6)。点击“如果”,在“选择个案:If”对话框中填写“filter_$ = 0”(图7),此时即选中了代码为0的子集(图8),可进行后续分析。
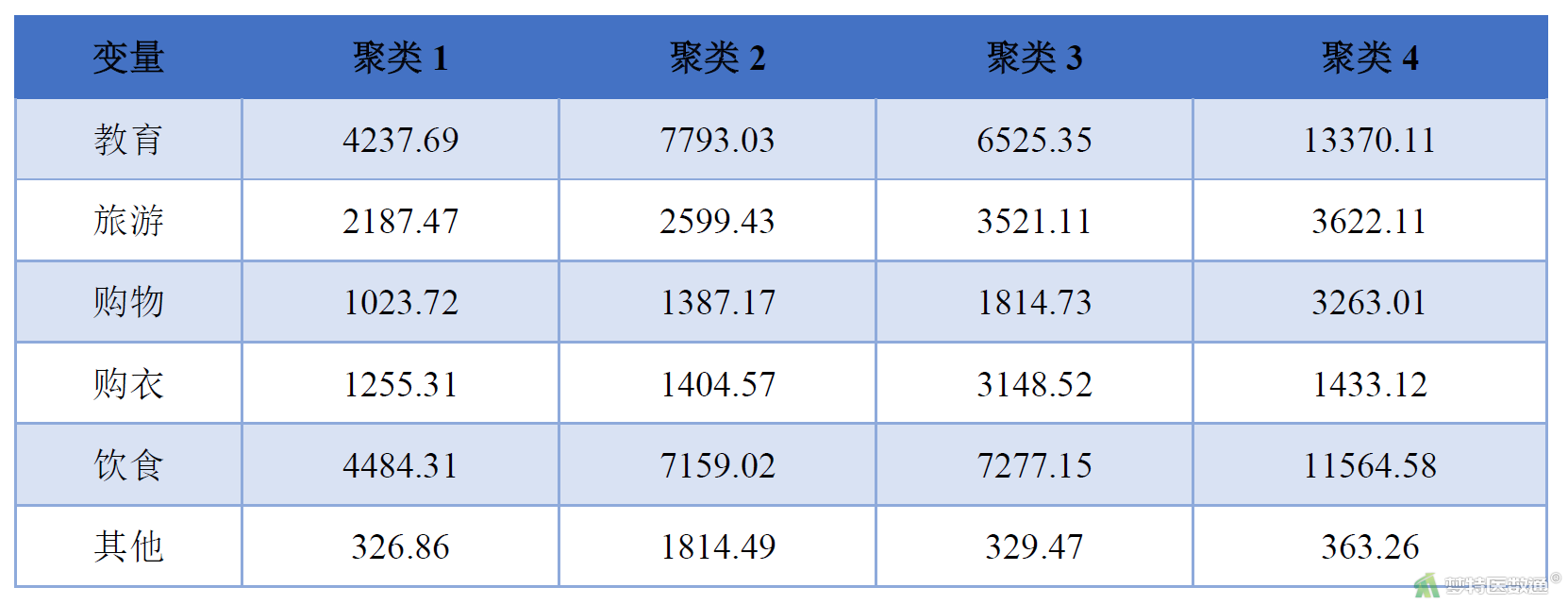
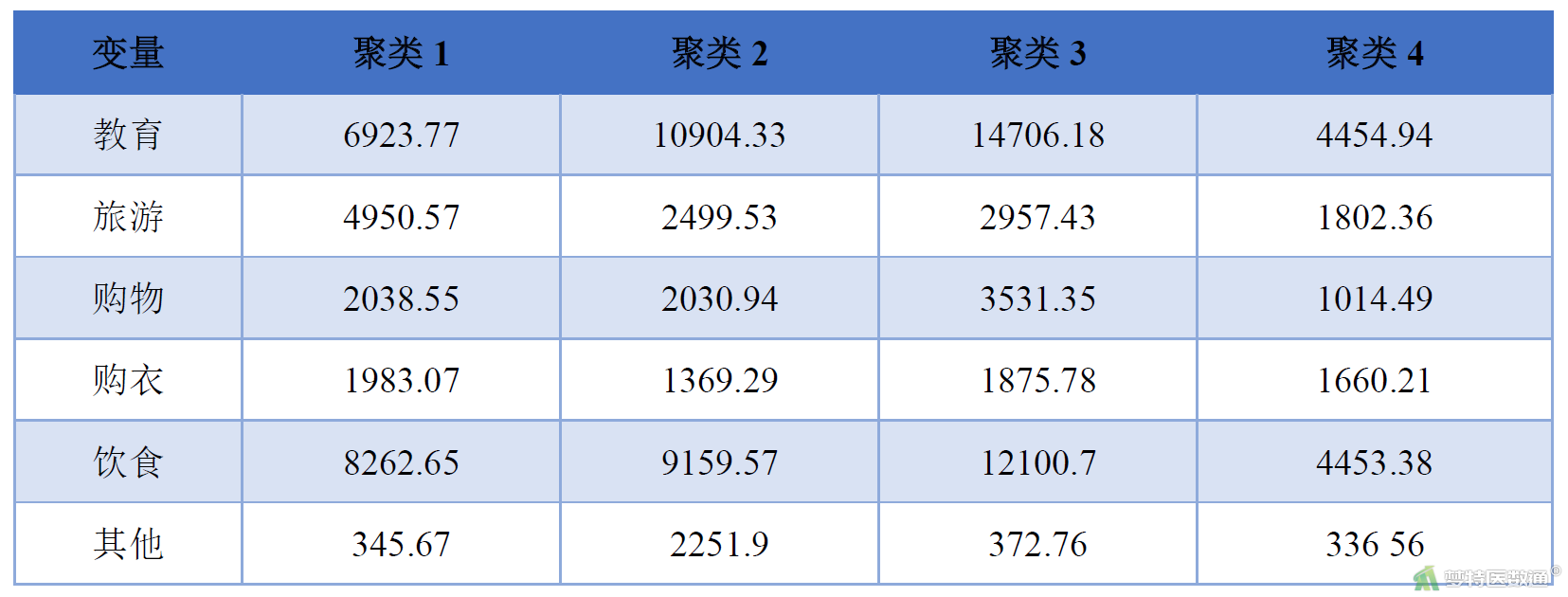
然后对选中的子集进行K均值聚类。同理操作选中另一个子集进行K均值聚类。同时,可使用2数据集中自动生成的变量“QCL-1”和“QCL-3”(即各个案例被归入的类别)对标准化前的原始变量进行统计描述,以更清楚地描述各类别的特征,具体操作见快速聚类(Quick Clustering)——SPSS软件实现。
(二) 结果解读
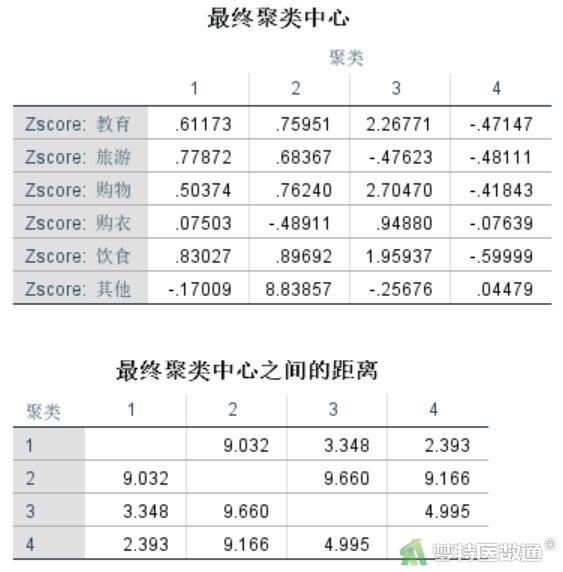
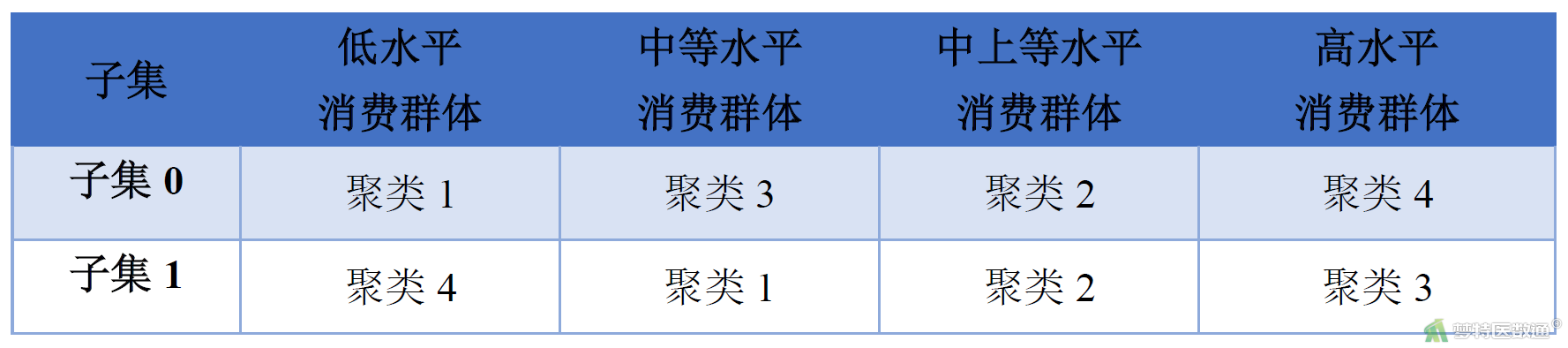
子集0的分析结果见图9-1图9-2和表1,子集1的分析结果见图10-1、图10-2和表2。通过比较2个子集分析结果,可以发现其均可聚类形成“低水平消费群体”、“中等水平消费群体”、“中上等消费群体”和“高水平消费群体”4类(表3),且与原数据集聚类结果一致。
五、分析小技巧
对于聚类结果的判断一般不宜以统计分析为准,而应当考虑结果和专业知识的符合程度以及结果的实用性来判断原来类别保留的意义。
六、知识小贴士
本文在同一方法相互验证过程中数据集随机时未设置随机种子数,故每次随机拆分成的2个子集数据略有不同。如读者应用本文提供的案例数据操作,结果将与本文呈现的结果不完全一致,但不影响最终结论。