在实际聚类分析过程中往往很难通过一次分析就得到满意的聚类结果,因此,需要对分析进行调整和优化,本文主要介绍SPSS提供的聚类轮廓插件,可对聚类结果进行优化。
关键词:SPSS; 聚类分析; 结果验证; 自动优化
聚类轮廓分析可以为每个案例计算出一个轮廓值,如果该值在-1~1之间,大于0表明该案例的分类效果较好,数值越接近1,分类效果越好,而数值越接近-1,则说明分类效果越差,错误分类的概率越高。同时,也会判断如果更换案例所属类别是否会提高轮廓值,并据此给出新的聚类结果,从而达到优化的目的。
一、案例介绍
使用快速聚类(Quick Clustering)——SPSS软件实现一文案例,某研究调查了2890名居民的家庭月开支情况,包括教育(Education)、旅游(Travel)、购物(Shopping)、购衣(Clothes)、饮食(Eat)和其他(Other),根据上述6个方面的开支情况,某研究者采用快速聚类方法将2890名居民分为“低水平消费群体”、“中等水平消费群体”、“中上等水平消费群体”和“高水平消费群体”4个群体,试采用SPSS软件对本次聚类结果进行优化计算。
二、软件操作
选择“分析”—“分类”—“聚类轮廓”,弹出聚类分析轮廓对话框(图1)。在“聚类分析轮廓”对话框中按以下参数设置相应选项:
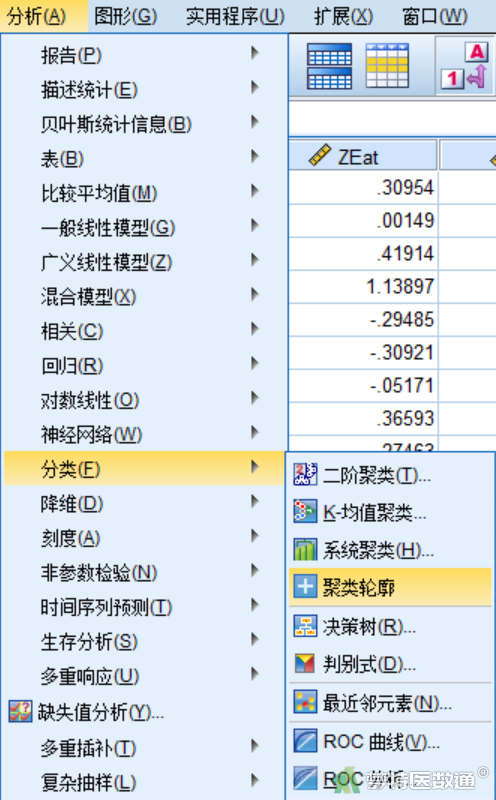
①将ZEducation、ZTravel、ZShopping、ZClothes、ZEat和ZOther等6个标化的变量放入聚类变量框中,已有的聚类结果变量“QCL_1”选入“聚类编号(N)”框中,“下一步最佳聚类”是用来指定优化后新的分类结果变量名称,本例填写“cls_new”;“轮廓值”用于指定存储个案轮廓值的新变量名称,本例填写“val_new”;“非相似性测量”框组用于选择距离测量指标,这些框组的选择原则上与用于计算原始聚类结果的方法一致,本例选择“欧式(E)”(图2)。
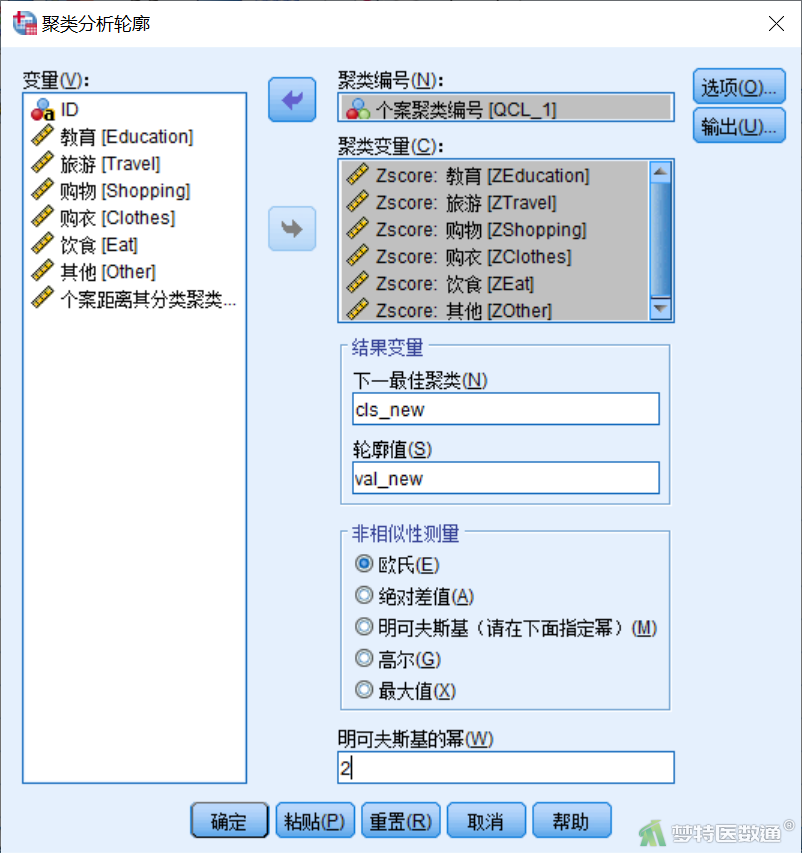
②选项:“对有序变量进行重新编号”用于将有序变量重新编码为正整数,本例中不涉及有序变量,因此无需进行设定;“权重变量(W)”可为每个变量提供权重,本例中未明确指出各个变量重要性,因此无需进行设定;“缺失值”提供了对数据中缺失值的处理方法,包括“按比例重新标度测量(S)”、“使用测量而不重新标度(G)”和“缺失任何变量时排除个案(X)”,本例选择默认选项“按比例重新标度测量(S)”(图3)。
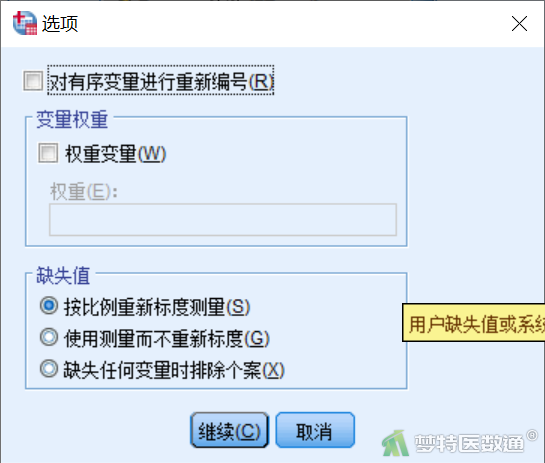
③输出:用于设置输出结果的格式,勾选“按聚类排列的直方图”,选择“直方图方向”选择“水平”,勾选“轮廓的三维条形图(按分配的聚类和下一最佳聚类排序) (3)” (图4)。
三、结果解读
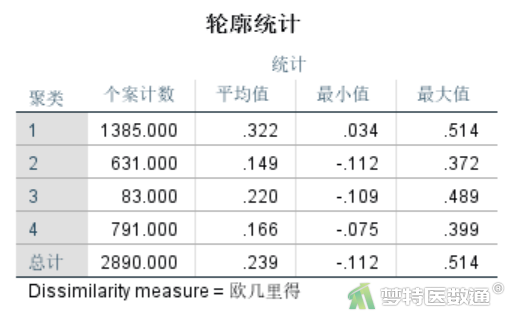
轮廓统计结果 (图5)别给出个案数、轮廓的平均值、最小值和最大值。可见本例各类别的轮廓平均值都大于0,但数值比较低,最小值中也存在小于0的类别,提示聚类效果一般。
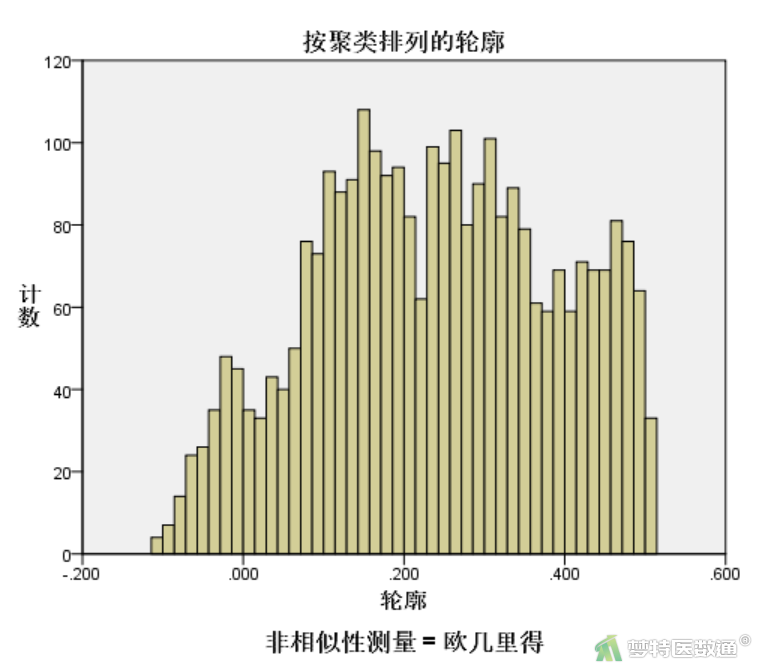
案例轮廓值的直方图(图6)中提供的信息有限。可将数据集按照聚类结果“QCL_1”拆分数据集后对轮廓值“val_new”绘制直方图,以更清楚观察每个聚类的轮廓值,如图7所示。整体而言,第一类的聚类效果较好。
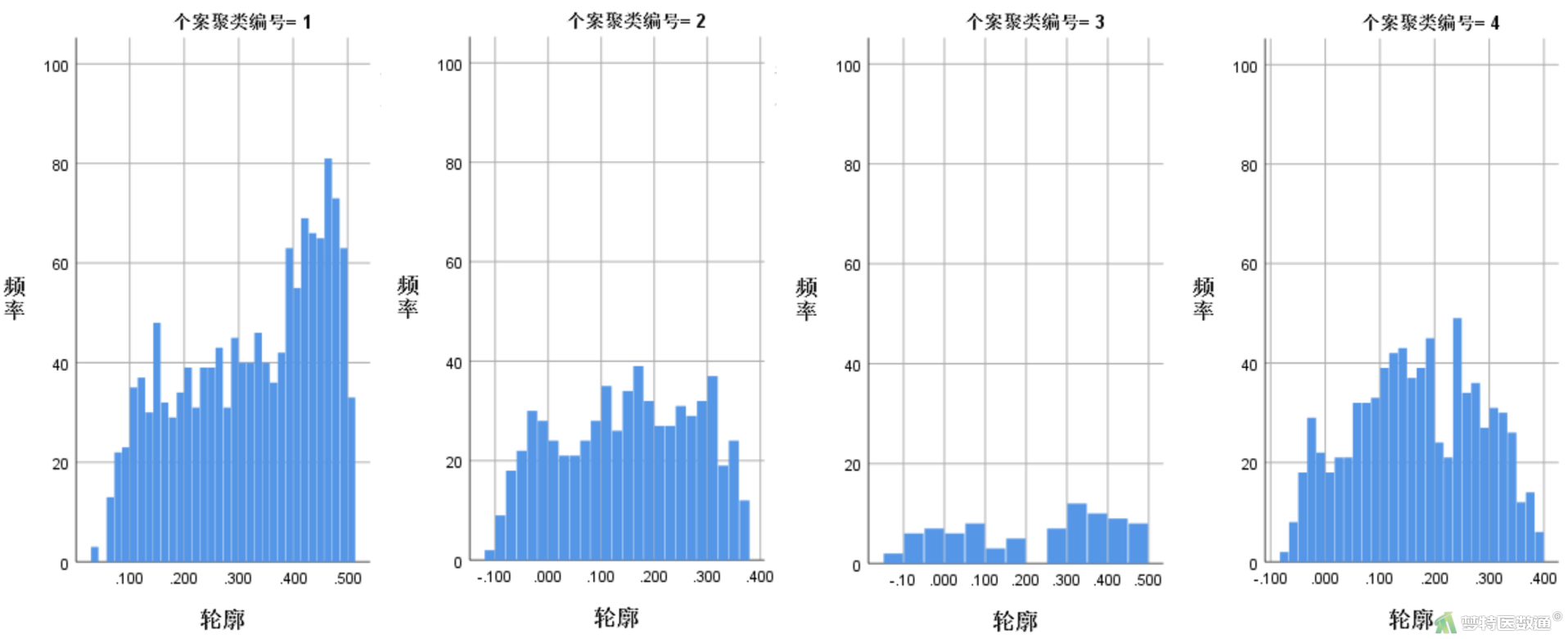
原类别和优化后的新类别交叉排序图(图8)主要用于发现质量较差的交叉单元格,以协助研究者做进一步判断。结果显示,4类均有不小的调整,其中类别号为4,转换为新类别号为1的单位格轮廓平均值较低,值得进一步分析。
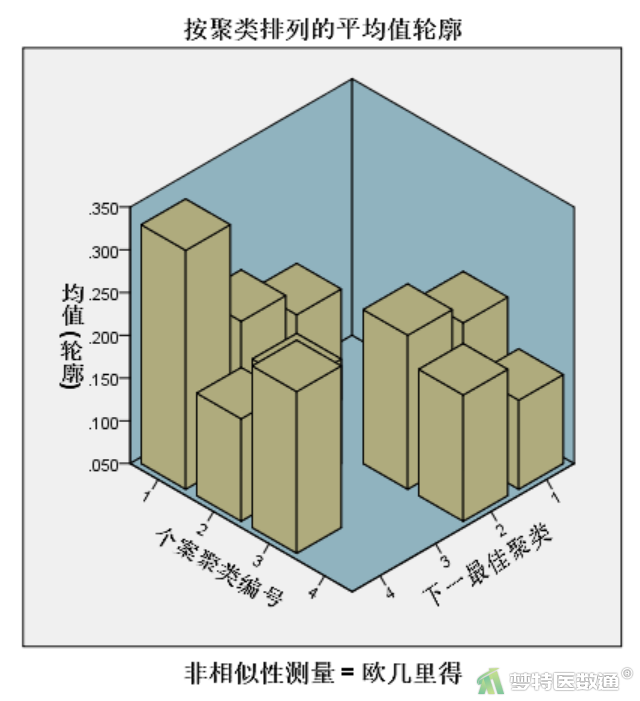
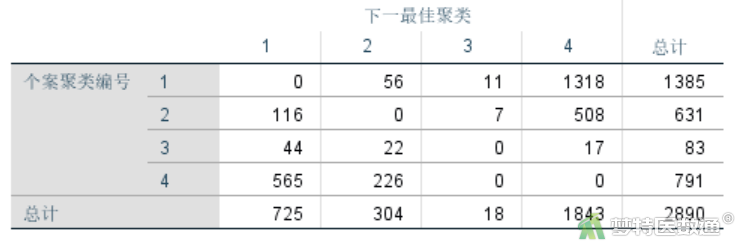
可以使用交叉表展示原聚类结果和新聚类结果(图9)的调整情况。根据优化结果,将数据聚类为3个类别似乎较为合适,可据此线索再次进行聚类分析,不断优化。
四、分析小技巧
对于聚类结果的判断一般不以统计分析为准,而应当考虑结果和专业知识的符合程度以及结果的实用性来判断原来类别保留的意义。