临床研究中,随机化包括随机化抽样、随机化分组和随机化顺序。交叉设计(Crossover Design)是常用的控制实验顺序影响的实验研究方法,是研究主效应的实验设计类型之一。本文将实例演示在SPSS软件中通过一般线性模型模块实现二阶段交叉设计资料的方差分析的操作步骤。
关键词:SPSS; 交叉设计; 一般线性模型; 方差分析
一、案例介绍
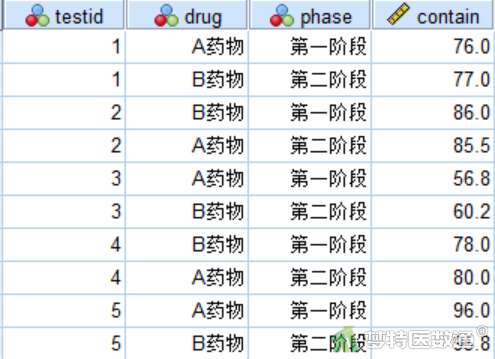
假设有一项两阶段交叉试验,分别使用A、B两种药物治疗同一批共10例患者,检测其某指标的血浆浓度(mmol/L)。对10例患者随机编号,第一阶段样本编号(testid)为奇数的5例患者用A药物治疗,样本编号(testid)为偶数的5例患者用B药物治疗;第二阶段对调治疗药物,即样本编号(testid)为奇数的患者用B药物,样本编号(testid)为偶数的药物用A药物。试对该两阶段交叉实验结果进行方差分析,评估药物效果。部分数据见图1。本案例数据可从“附件下载”处下载。
二、问题分析
在两阶段交叉数据分析,可以按照三因素方差分析思路进行数据处理。但需要满足6个条件:
条件1:观察变量唯一,且为连续变量。本研究中观察变量只有某指标的血浆浓度,且为连续变量,该条件满足。
条件2:有3个因素,且都为分类变量。本研究中有处理效应(A、B两种药物)、阶段效应及受试者间的个体差异,都为分类变量,该条件满足。
条件3:观测值相互独立。本研究中各研究对象的观测值都是独立的,不存在互相干扰的情况,该条件满足。
条件4:观察变量不存在显著的异常值,该条件需要通过软件分析后判断。
条件5:相互比较的各处理水平(组别)的总体方差相等,即方差齐同,可采用方差齐性检验。该条件需要通过软件分析后判断。
条件6:各组、各水平观测值为正态(或近似正态)分布或因变量残差整体服从正态分布,该条件需要通过软件分析后判断。
三、软件操作及结果解读
(一) 适用条件判断
异常值检测及正态性检验、方差齐性检验,在一般线性模型或线性回归中可以通过残差进行判断,详见“两因素方差分析(Two-way ANOVA)一——无交互作用——SPSS软件实现”,异常值还可以通过库克距离进行判断。一般线性模型分析操作过程详见后文。
1. 条件4判断(异常值检测)
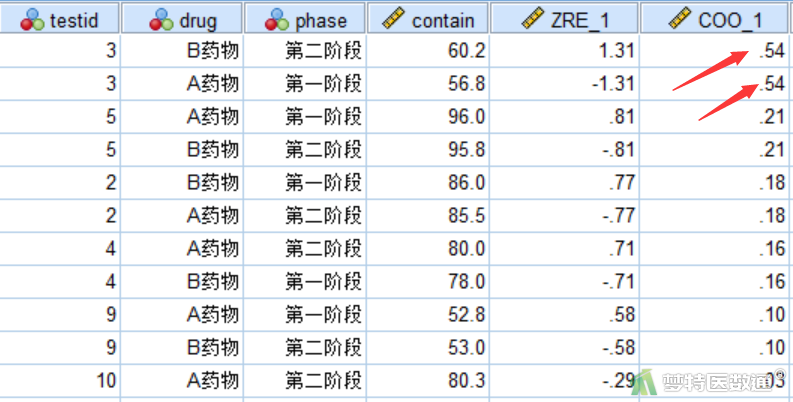
一般认为当库克距离(Cook′s distance)≤0.5时不是异常值点,当>0.5时是异常值点。Coo_1是通过一般线性模型生成的库克距离(图2);可知,有两个数据的库克距离为0.54>0.5,但异常值的判断最终还需要专业知识的支持,此处根据专业并不认为这两个数据为异常值。
2.条件5判断(正态性检测)
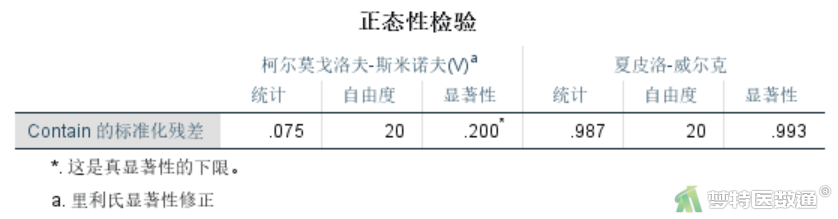
通过对一般线性模型生成的残差进行整体(不分组)正态性检验(图3),可知柯尔莫戈洛夫-斯米诺夫(K-S检验)和夏皮洛-威尔克正态性(S-W检验)两种正态性检验的结果,均提示数据服从正态分布(P>0.05)。
3. 条件6判断(方差齐性检验)
在一般线性模型的一元方差分析中,如果有2个及以上的因素且无重复例数的时候,模型不会给出方差齐性检验的结果。此时可以通过对一般线性模型分析生成的残差进行统计学检验。操作如下:
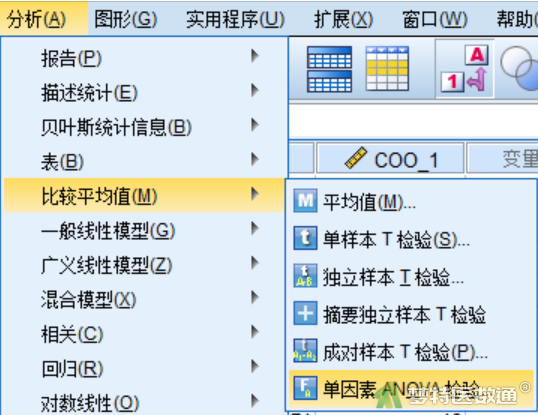
选择“分析”—“比较平均值”—“单因素ANOVA检验”(图4)。
打开“单因素ANOVA检验”对话框(图5),将“Contain的标准化残差”选入右侧“因变量列表”,将“药物”选入“因子”,点击“确定”。
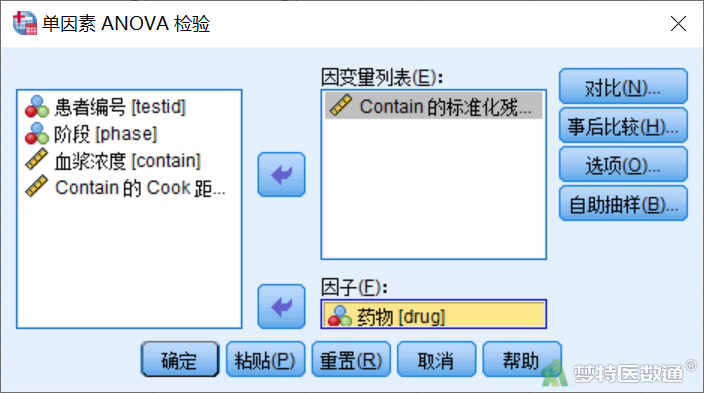
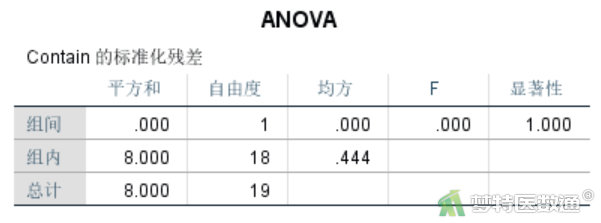
通过残差的单因素方差分析结果(图6)可知,基于平均值的F<0.001,P=1.000>0.05,提示按药物分组时,数据方差齐。
(二) 一般线性模型分析过程
选择“分析”—“一般线性模型”—“单变量”(图7)。
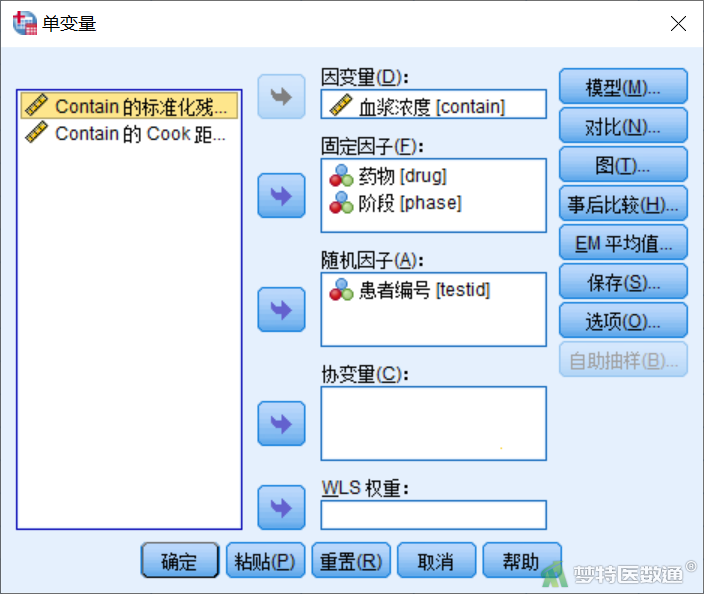
打开“单变量”对话框(图8),将“血浆浓度”选入右侧“因变量”框,将“药物”“阶段”选入右侧“固定因子”框,将“患者编号”选入“随机因子”框。“患者编号”之所以被选入“随机因子”框,是因为受试对象应当被看作是从一个总体中随机抽样所得(实际上,由于本例中的受试对象为自身配对,单元格中没有重复数据,因此也可以使用固定因子来分析,结果完全一致)。
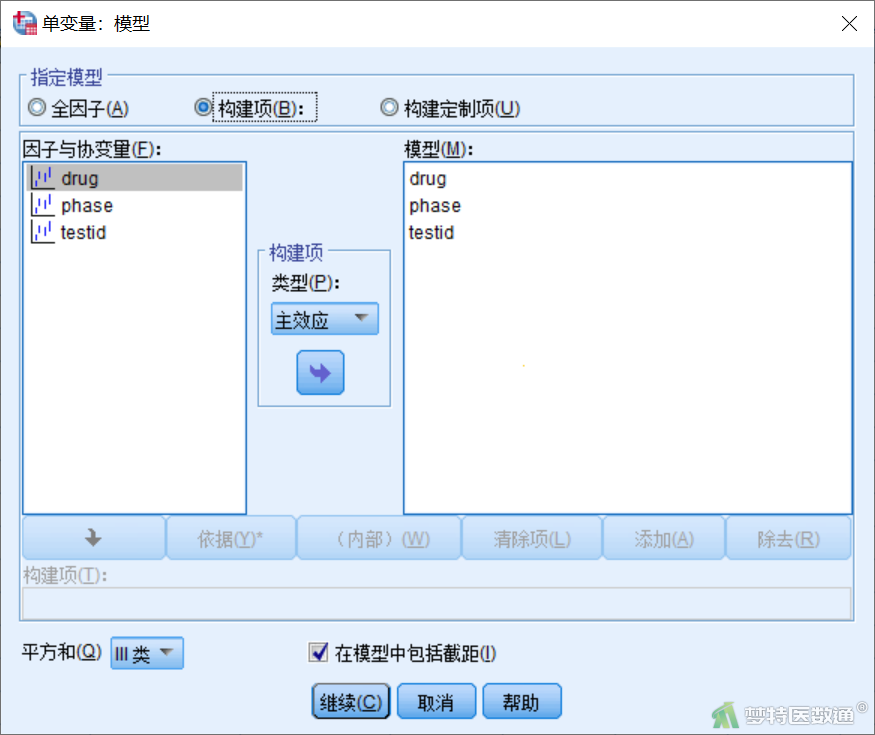
点击“单变量”对话框(图8)右侧“模型”,打开“单变量:模型”子对话框(图9),点击“构建项”,将drug、phase、testid的“主效应”选入右侧“模型”框中。注意,此处不能引入交互作用。
点击“单变量”对话框(图8)右侧“图”,打开“单变量:轮廓图”子对话框(图10),将“phase”选入右侧“水平轴”中,将drug选入右侧“单独的线条”中,点击“添加”;在“图表类型”中选 “折线图”,在“误差条形图”中勾选“包括误差条形图”及“置信区间(95.0%)”,点击“继续”。

由于本案例只有2组和2个阶段,因此不需要进行事后比较,若需进行事后比较,可在“单变量:实测平均值的事后多重比较”子对话框(图11)中进行操作。

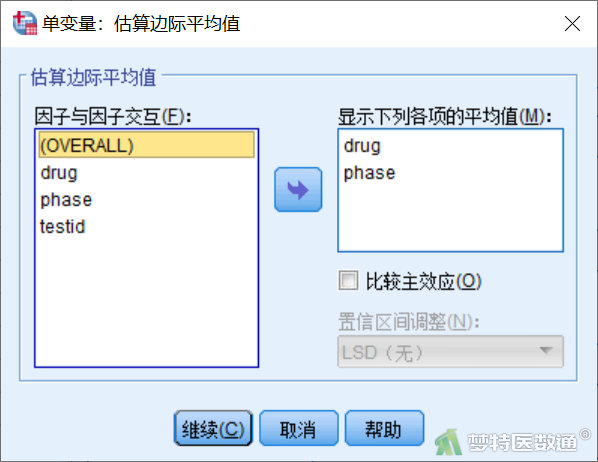
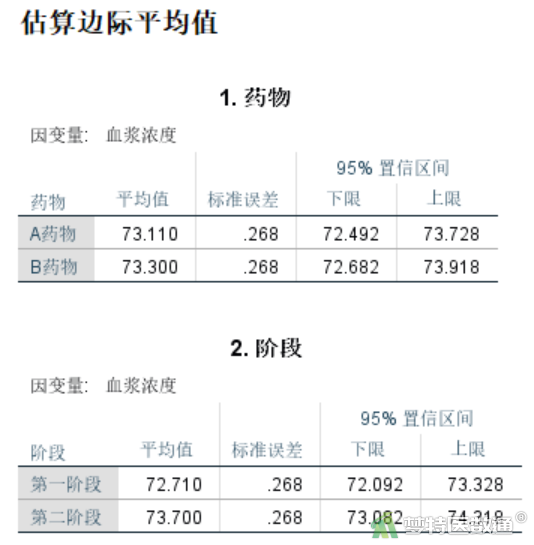
点击“单变量”对话框(图8)右侧“EM平均值”,打开“单变量:估算边际均值”子对话框(图12),将drug、phase选入右侧“显示下列各项的均值”框中,点击“继续”。
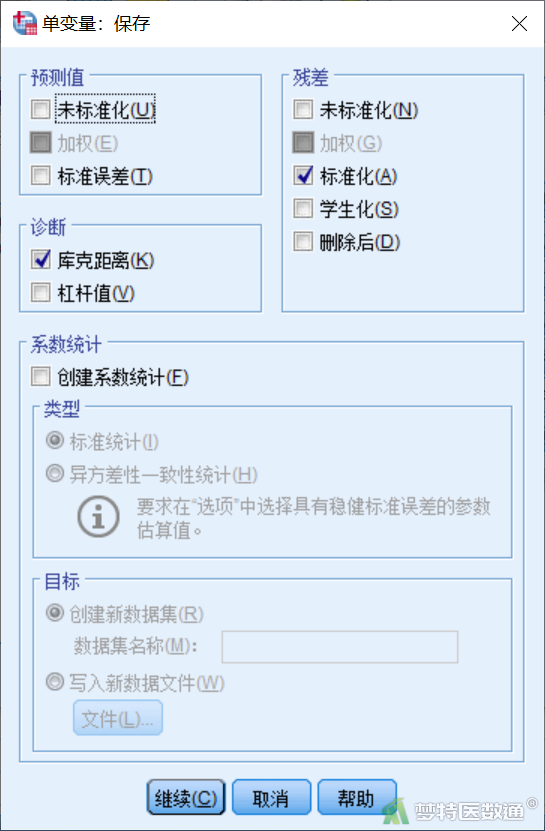
点击“单变量”对话框(图8)右侧“保存”,打开“单变量:保存”子对话框(图13),“残差”项中勾选“标准化”,“诊断”项中勾选“库克距离”,点击“继续”。
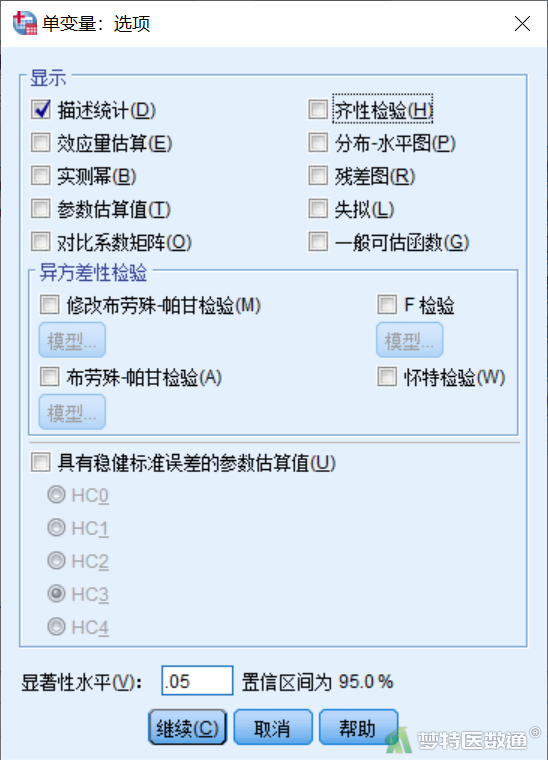
点击“单变量”对话框(图8)右侧“选项”,打开“单变量:选项”子对话框(图14),“显示”项中勾选“描述统计”,点击“继续”。回到图8后,点击“确定”即可。
(三) 结果解读
1. 统计描述
由图15-1~15-3可知,第一阶段A、B药物组的血浆浓度分别为69.02±17.46、76.40±19.15 mmol/L,第二阶段A、B药物组的血浆浓度分别为77.20±19.02、70.20±16.77 mmol/L,A、B药物组总体的血浆浓度分别为73.11±17.75、73.30±17.28 mmol/L,第一阶段、第二阶段总体的血浆浓度分别为72.71±17.71、73.70±17.30 mmol/L。
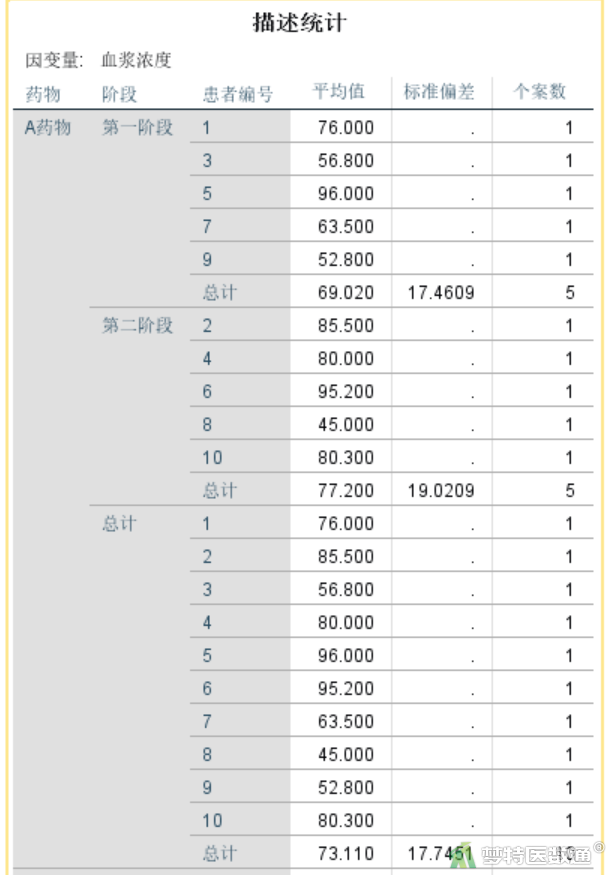
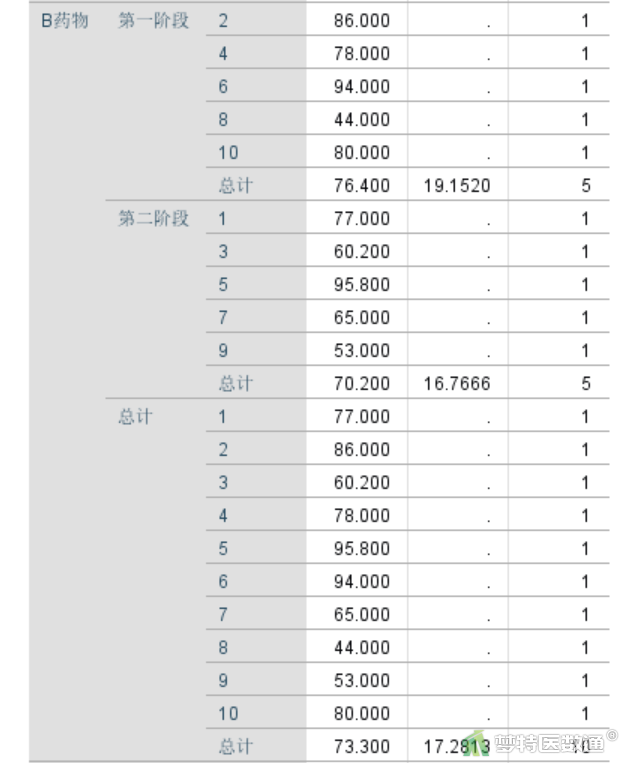
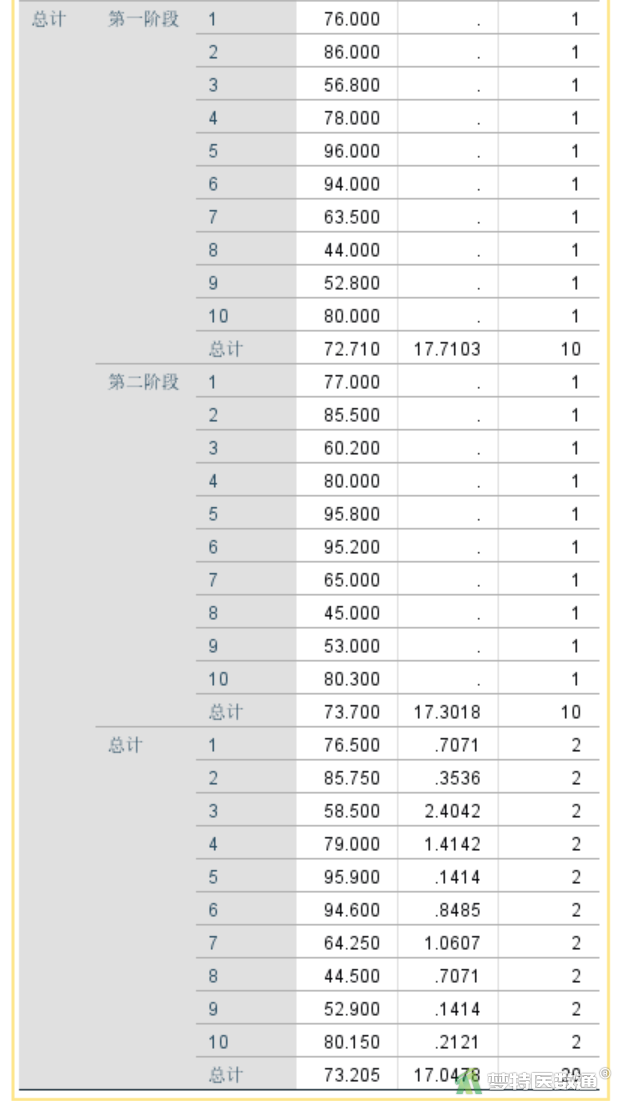
“血浆浓度的估算边际平均值”图(图16)绘制了各组药物血浆浓度在不同阶段的情况。
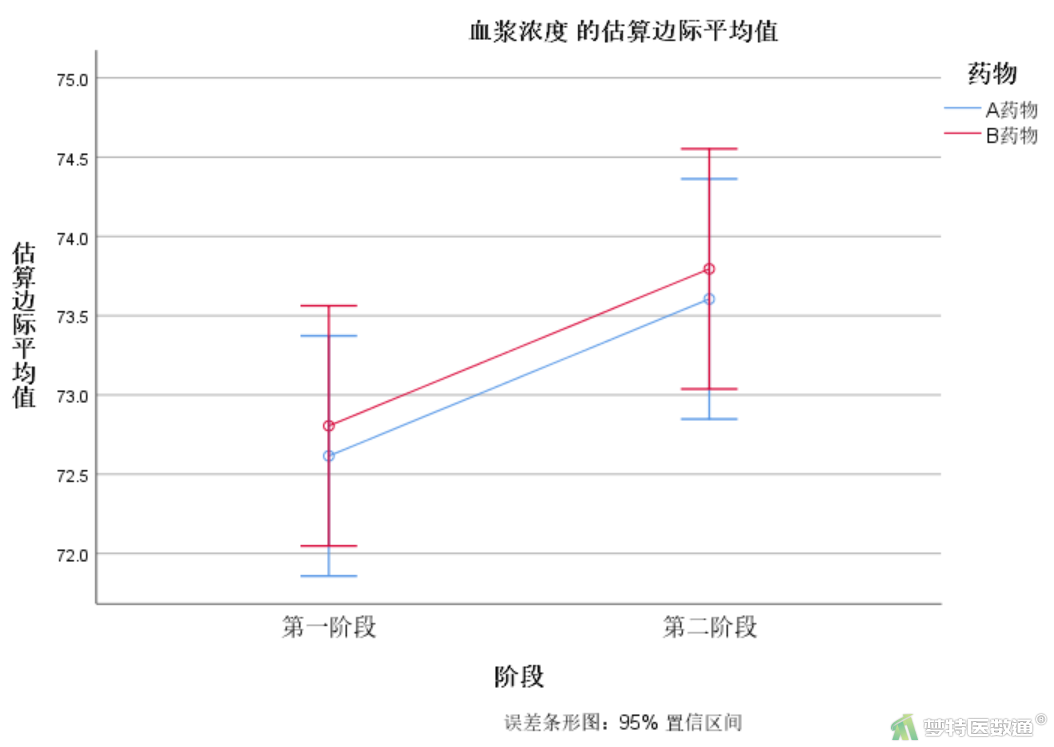
2. 估算边际平均值
当不存在协变量时,“估算边际平均值”(图17)和“统计描述”(图15-1~图15-3)的均值一样。“估算边际平均值”同时给出了95%置信区间。
3. 方差分析
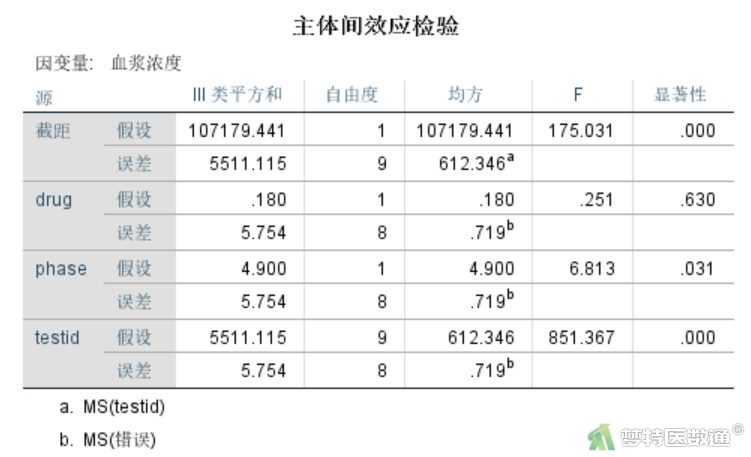
“主体间效应检验”结果(图18)提示,Fdrug=0.251,P=0.630,表示尚不能认为两种药物的血浆浓度有差别;Fphase=6.813,P=0.031,表示两阶段血浆浓度差异有统计学意义;Ftestid=851.367,P<0.001,表示个体间血浆浓度差异有统计学意义。
四、结论
本研究采用交叉设计分析A、B两种药物对某指标的血浆浓度的影响。通过库克距离判断,两组数据不存在需要特殊处理的异常值;通过对残差进行正态性检验,提示数据服从正态分布;通过对残差进行统计学检验,提示两组药物组数据间方差齐。
分析结果显示,A、B药物组总体的血浆浓度分别为73.11±17.75、73.30±17.28 mmol/L,第一阶段、第二阶段总体的血浆浓度分别为72.71±17.71、73.70±17.30 mmol/L。两种药物的血浆浓度差异无统计学意义(F=0.251,P=0.630);两阶段血浆浓度差异有统计学意义(F=6.813,P=0.031)。
五、分析小技巧
在交叉设计实验研究中,无论“阶段”有无统计学意义,均不能被剔除模型重新分析。因为交叉设计常用于新药临床试验,此时并非探索性分析,而是证实性分析。证实性分析在设计时就充分考虑了所有因素,从而决定了所用的统计学方法,绝不能根据统计学结果更改方法。