关键词:Python软件; Python软件数据导入; Python软件数据读取; Python软件文件格式; Python软件结果保存
一、数据读取
(一)读取带分隔符的文本文件数据
1. 使用open()函数读取数据
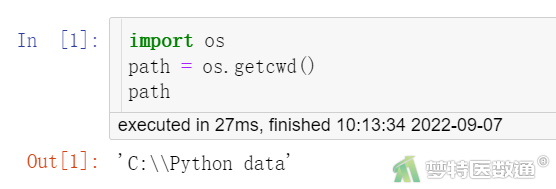
在读取之前,可以先使用下列代码获取当前路径,见图1。
import os path = os.getcwd() path
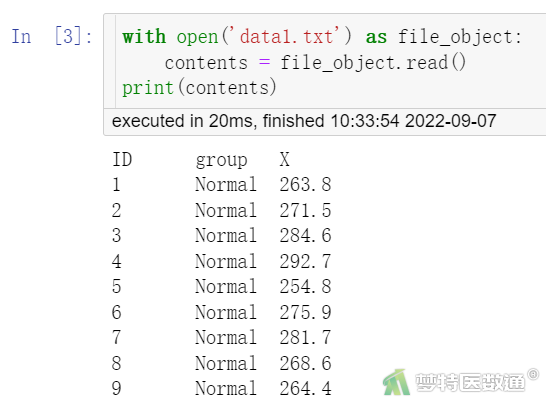
使用open ()函数读取带分隔符的文本文件,其语法示例如下:
with open('data1.txt') as file_object:
contents = file_object.read()
print(contents)
函数open()接受一个参数:要打开的文件的名称。
若文件存在于当前工作路径,则无需输入完整文件路径,否则需要输入完整的文件路径,见图2。
当要打开不在程序文件所属目录中的文件,需要提供文件路径,让Python到系统的特定位置去查找。文件路径可以使用相对文件路径与绝对文件路径两种。
- 相对文件路径让Python到指定的位置去查找,而该位置是相对于当前运行的程序所在的目录的。例:open('work document\\ data1.txt')
- 当相对文件路径行不通时,可使用绝对文件路径。即将文件在计算机中的准确位置告诉Python。例:open('D:\\Jupyter Notebook\\work document\\ data1.txt')
open('data1.txt')返回一个表示文件data1.txt的对象,Python将该对象赋给file_object供以后使用。
有了表示data1.txt的文件对象后,使用方法read()读取这个文件的全部内容,并将其作为一个长长的字符串赋给变量contents。这样,通过打印contents的值,就可将这个文本文件的全部内容显示出来。
无论是哪一种方法,读取出来的数据均如图3所示。格式为“.txt”的数据方法也是如此。

2. 使用Pandas库读取数据
Pandas读取数据的方法有很多,这里列举两个常用的方法read_csv和read_table。read_csv用来读取csv格式的数据文件,read_table用来读取带分隔符的通用文件。
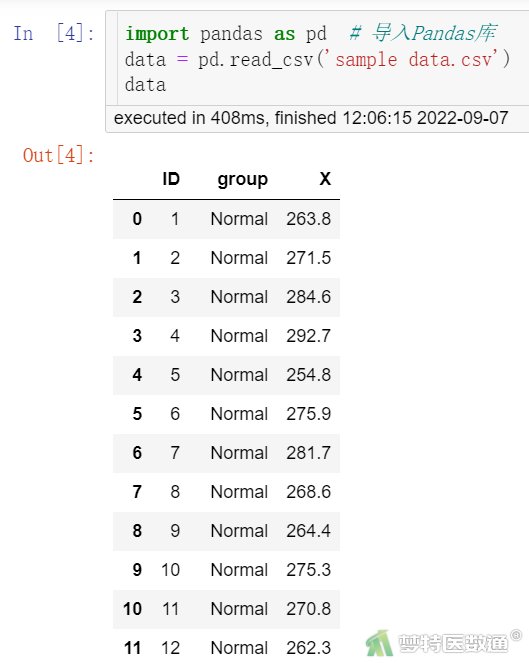
具体操作代码如下,输出结果见图4。需要注意的是在读取数据的代码中也是要插入文件路径的,如果要读取的文件保存在Python工作目录中就可以不用加路径,用‘文件名.格式’就可以了。
import pandas as pd # 导入Pandas库
data = pd.read_csv('sample data.csv')
data
import pandas as pd # 导入Pandas库
data = pd.read_table('sample data.csv')
data
结果与图2相同。
3. 使用Numpy库读取数据
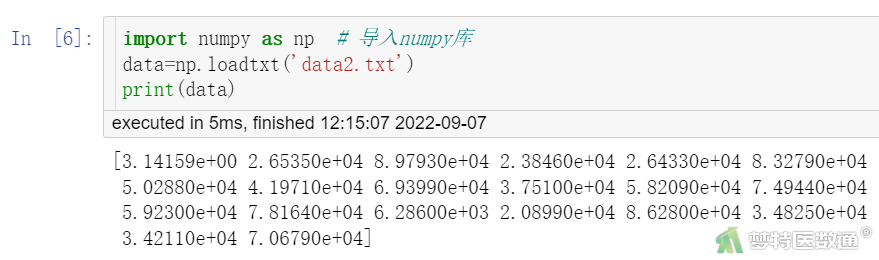
用Numpy读取带分隔符的文本文件数据的方法常用loadtxt。操作代码见下,结果见图5。
import numpy as np # 导入numpy库
data=np.loadtxt('data2.txt')
print(data)
格式为“.csv”的数据方法也是如此。
(二)读取Excel数据
Pandas中也带有可以读取Excel文件的模块read_excel,使用方法与用Pandas库读取带分隔符的文本文件数据的方法相同。
(三)读取其他格式数据
Pandas不仅可以读取csv、excel等文件,还可以读取很多数据分析中常用的数据格式文件,部分常用读取函数及对应文件格式见表1。
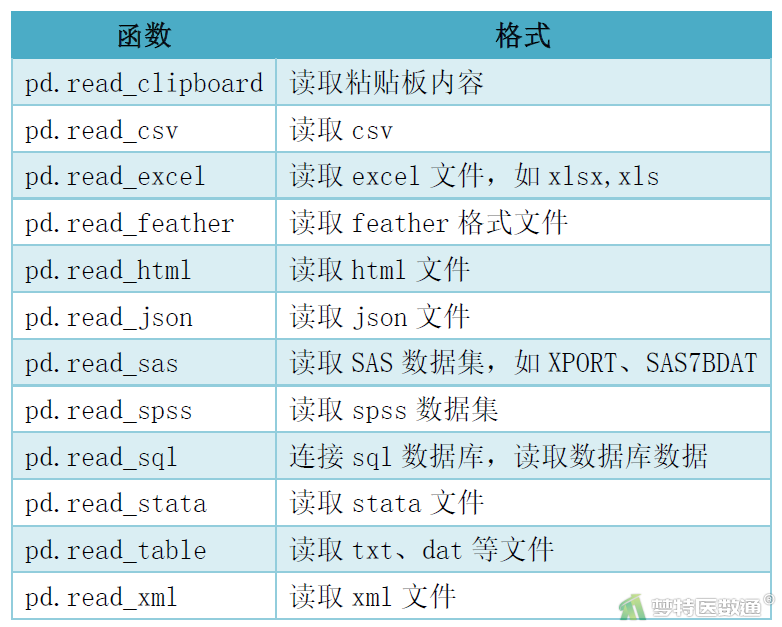
二、结果保存
(一) 保存整理好的数据
以示例数据中sample data.csv为例进行下列结果保存的演示。
1. 保存为csv文本文件
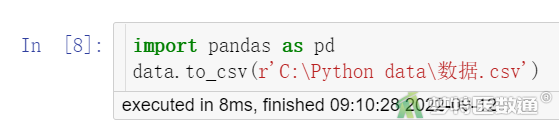
保存为csv文本文件,可以使用Pandas包中的to_csv()保存已经整理好的数据框,代码如下。
import pandas as pd data.to_csv(r'C:\Python data\数据.csv')
其中data为要保存的文件名(注意:在打开文件的时候已经将sample data.csv指定为data,所以此处的文件名是data),“数据”为保存为csv文件的重命名,见图7。
上述操作后,可以发现在C:\Python data文件夹中新生成了一个csv格式的名为“数据”的文件。
2. 保存为txt文件
保存为txt文本文件,可以使用Numpy包中的savetxt()保存已经整理好的数据框。
import numpy as np
np.savetxt('示例.txt',data,fmt=['%d','%s','%.1f'])
其中“示例.txt”为保存为txt文件的重命名,data为要保存的数组。'%d'、'%s'、'%.1f'作用为指定3列的数据格式分别为整数、字符串、保留一位小数的浮点数,见图8。

上述操作后,可以发现在C:\Python data文件夹中新生成了一个txt格式的名为“示例”的文件。
3. 保存为xlsx文件
代码如下,结果见图9。
import pandas as pd resultPath = '示例数据.xlsx' #定义导出的路径,并定义好文件名 data1.to_excel(resultPath,sheet_name = "数据",index = False) #导出文件
其中sheet_name = 表格名,index = False 为导出的数据有索引值。除此之外还可以添加na_rep = 0 或(和)inf_rep = 0分别代表意思为将空值填充为0或(和)将不符合数学规律和定律的填充为0。

上述操作后,可以发现在C:\Python data文件夹中新生成了一个xlsx格式的名为“示例数据”的文件。
(二) 保存图片
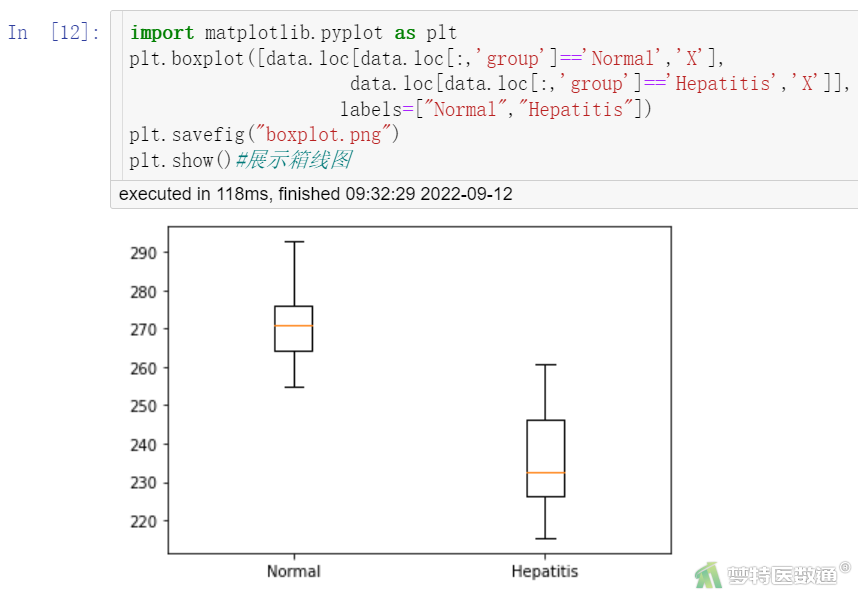
当完成绘图后,可以使用plt.savefig()对图片进行保存。以上述打开的“sample data.csv”文件为例,在此基础上绘制箱线图并保存为png格式,代码如下,结果见图10。
import matplotlib.pyplot as plt
plt.boxplot([data.loc[data.loc[:,'group']=='Normal','X'],
data.loc[data.loc[:,'group']=='Hepatitis','X']],
labels=["Normal","Hepatitis"])
plt.savefig("boxplot.png")
plt.show()#展示箱线图
上述操作后,可以发现在C:\Python data文件夹中新生成了一个png格式的名为“boxplot”的图片。