关键词:Python; Python个案合并; Python变量合并; Python数据筛选
数据管理多包括数据合并和数据筛选。数据的合并包括个案的合并(向数据框中添加行)和变量的合并(向数据框中添加列),下面将演示数据合并和数据筛选的操作步骤过程。
一、个案合并
假设“data1.csv”数据集中记录了ID为1~15的15名研究对象的age (年龄)、gender (性别)、grade (年级)、hight (身高)和weight (体重)5个变量数据,“data2.csv”数据集中记录了ID为16~30的15名研究对象的以上5个变量数据,现需要将两个数据集的样本数据进行合并。本案例数据均可从“附件下载”处下载。
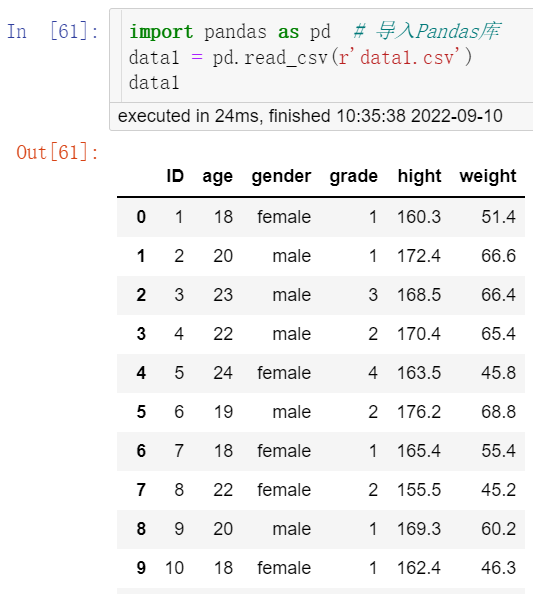
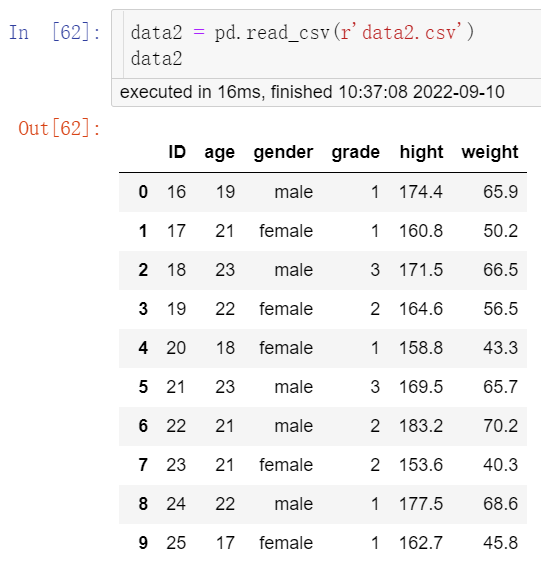
①首先按照以下语句将“data1.csv”“data2.csv”文本文件分别读入,结果见图1、图2。
import pandas as pd # 导入Pandas库 data1 = pd.read_csv(r'data1.csv') data1
data2 = pd.read_csv(r'data2.csv') data2
②要纵向合并两个数据集(数据框),可以使用pd.concat ()函数,语句如下:
total = pd.concat([data1,data2],axis = 0,ignore_index = True) total
其中axis = 0表示将数据集2纵向拼接到数据集1中;axis = 1表示将数据集2横向拼接到数据集1中。ignore_index = True表示忽略之间的索引,重新编排索引;ignore_index = False表示继续使用之前的索引。
可生成一个名为“total”的合并数据集,结果见图3。若表格太长不想呈现出所有行数可使用pd.set_option()函数,pd.set_option('display.max_rows', 10)表示最多显示10行,若将“rows”改为“columns”意为最多显示10列,若将“10”改为“None”则表示显示所有行。
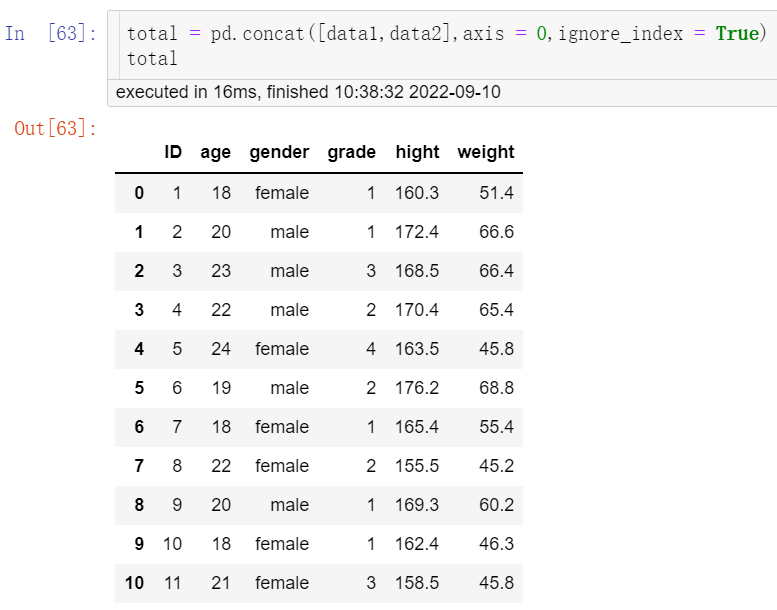
需要注意的是,两个数据框必须拥有相同的变量,对数据的变量顺序没有特殊要求。
二、变量合并
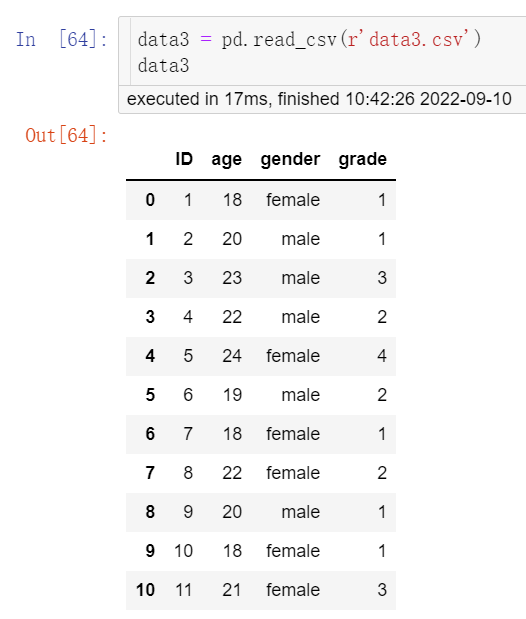
假设“data3.csv”数据集中记录了ID为1~15的15名研究对象的age、gender和grade3个变量数据,“data4.csv”数据集中记录了ID为1~15的15名研究对象的hight和weight2个变量数据,现需要将两个数据集的变量数据进行合并。
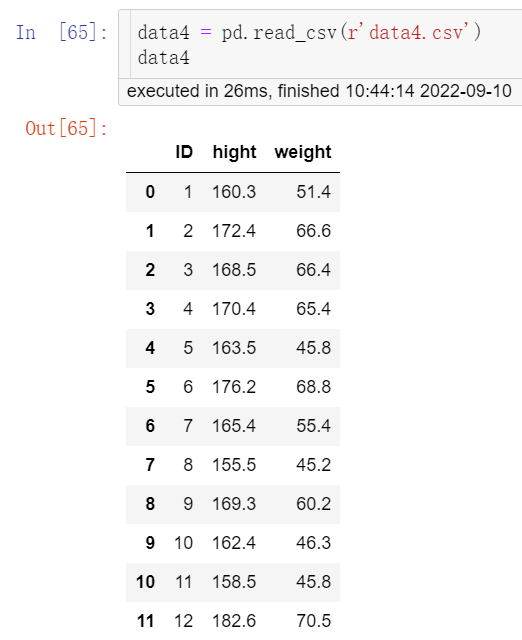
①按照上述数据读取方法同时打开“data3.csv”和“data4.csv”,并命名为data3和data4,结果见图4、图5。
#读取两组数据
data3 = pd.read_csv(r'data3.csv') data3
data4 = pd.read_csv(r'data4.csv') data4
②通过merge()函数对两个数据集进行横向的合并,通常使用一个或多个共有变量进行联结,结果见图6。
data5 = pd.merge(data3,data4,on='ID',how="outer") data5
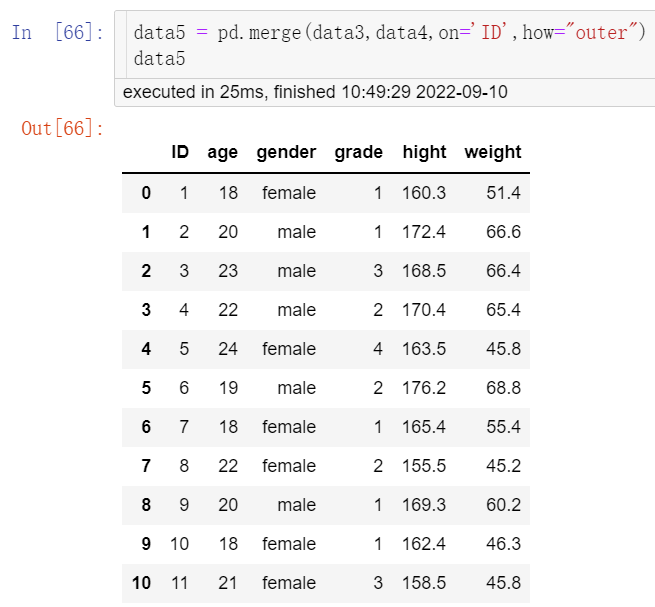
其中,参数on确定哪个字段作为主键。由于pd.merge()默认的是内连接,当指定主键为ID,所以只要ID对的上,信息就会被保留。参数how控制拼接方式,默认内连接(inner),内连接是只将两个表主键一致的信息拼接到一起。外连接(out)是保留两个表的所有信息,拼接的时候遇到标签不能对齐的部分,用NAN进行填充。
三、数据筛选
在数据分析过程中,有时需要选择一部分数据进行分析,即选择满足一定条件的样本。比如,选择血红蛋白浓度大于160 g/L的样本人群,选择年龄大于60岁的样本人群。可以利用条件抽取、挑选出或删除符合/不符合一定条件的样本,如删除有缺失值的样本。
①使用较为简单的语句对数据进行筛选
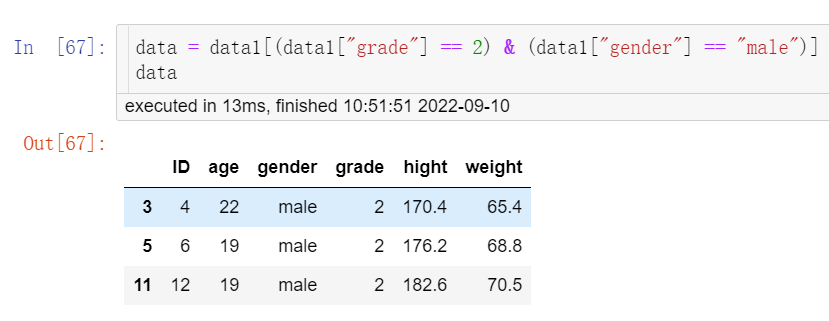
以“data1”演示筛选出“gender”中为“male”以及“grade”中为“2”的样本,结果见图7。
data = data1[(data1["grade"] == 2) & (data1["gender"] == "male")] data
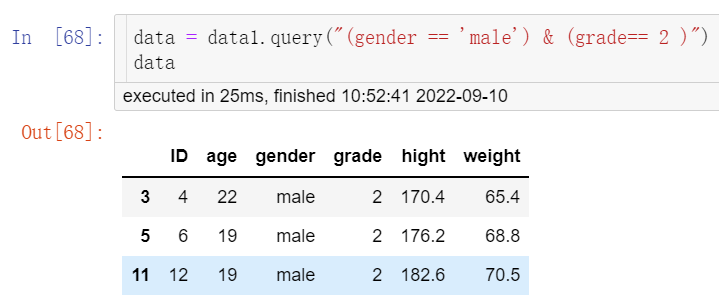
②使用query()函数对数据进行筛选
data = data1.query("(gender == 'male') & (grade== 2 )")
data
结果见图8。
③使用loc()函数对数据进行筛选
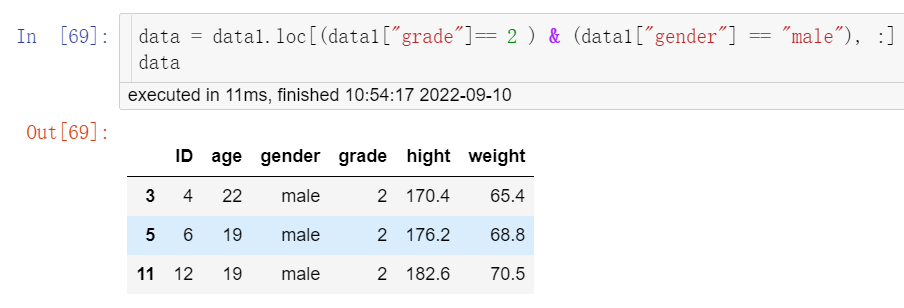
data = data1.loc[(data1["grade"]== 2 ) & (data1["gender"] == "male"), :] data
结果见图9。