关键词:Python数据转换; Python数据拆分; Python数据合并; Python变量赋值
以“data.csv”演示增加/删除变量的操作过程。
一、数据读取及变量索引
(一) 读取数据
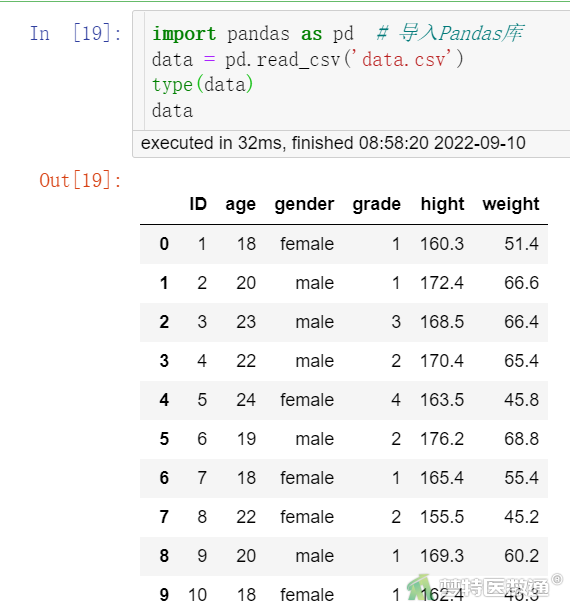
使用pandas库读取“data.csv”(可在“附件下载”处下载),读取数据结果见图1。
# 读取数据
import pandas as pd # 导入Pandas库 data = pd.read_csv(’data.csv’) type(data) data
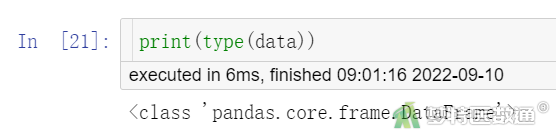
# 查看格式
print(type(data))
为DataFrame格式文件,见图2。
(二) 变量索引
在python中采用loc函数进行变量索引,索引格式为:data.loc[行索引,列索引]
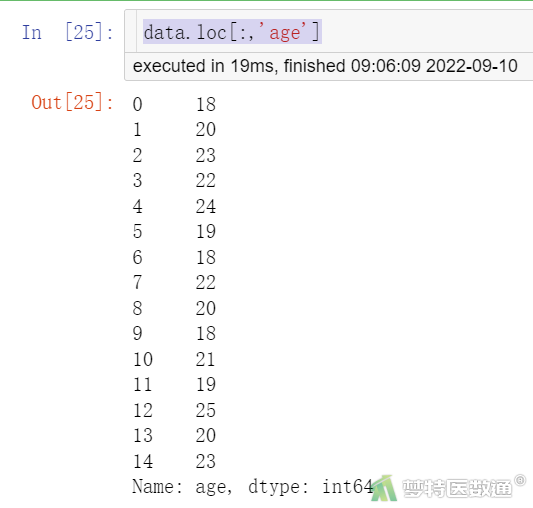
# 提取age列(图3)
data.loc[:,’age’] # 行索引为“:”表示所有行
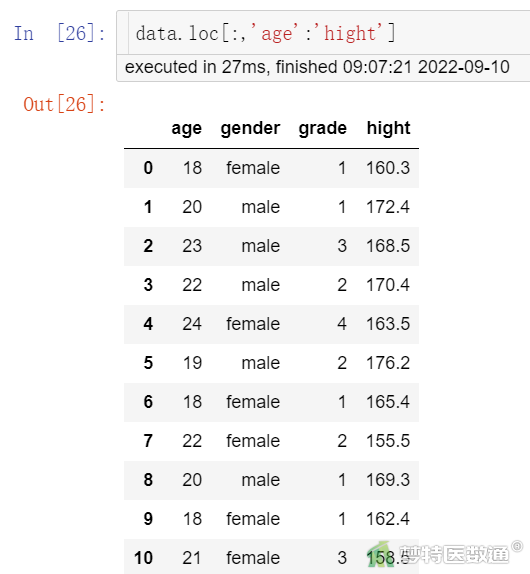
# 索引age到hight列(图4)
data.loc[:,’age’:’hight’]
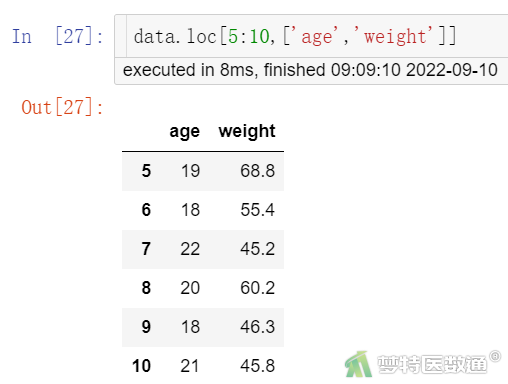
# 索引age和weight两列数据第5-10行数据(图5)
data.loc[5:10,['age','weight']]
二、增加/删除变量
(一) 表格末尾添加变量
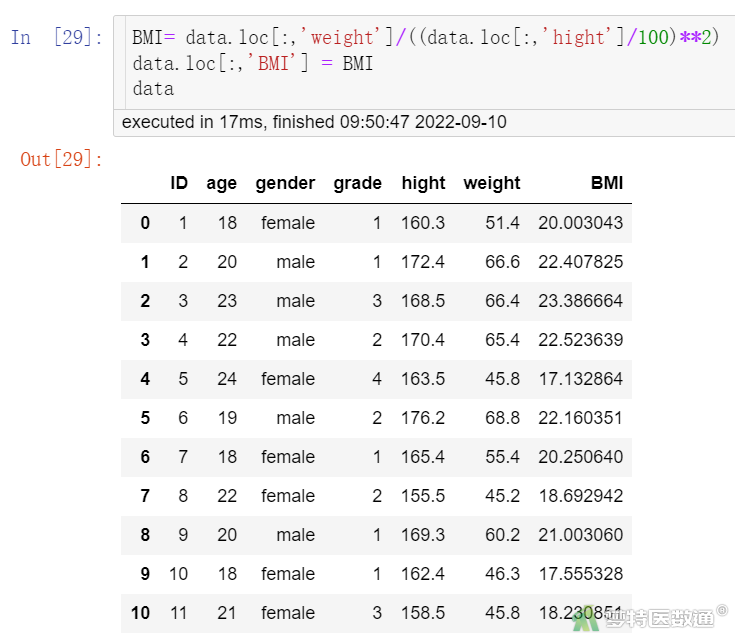
# 使用loc函数创建新变量。
BMI= data.loc[:,'weight']/((data.loc[:,'hight']/100)**2) data.loc[:,'BMI'] = BMI data
可见在数据集data中生成了一个新变量BMI(图6)。
(二) 指定位置插入
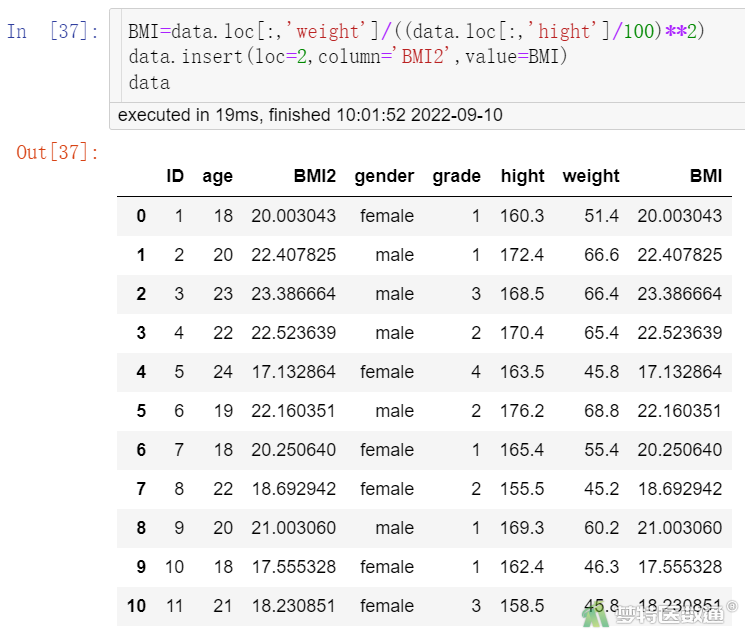
使用insert()可以创建新的变量,如在第2列插入一个名为“BMI2”的新变量,见图7。
BMI=data.loc[:,'weight']/((data.loc[:,'hight']/100)**2) data.insert(loc=2,column='BMI2',value=BMI) #在第2列位置上,插入列名为BMI2,值为BMI计算结果数值(注:列数从0而不是1开始) data
(三)删除操作
使用drop()可以删除已有的行或列数据
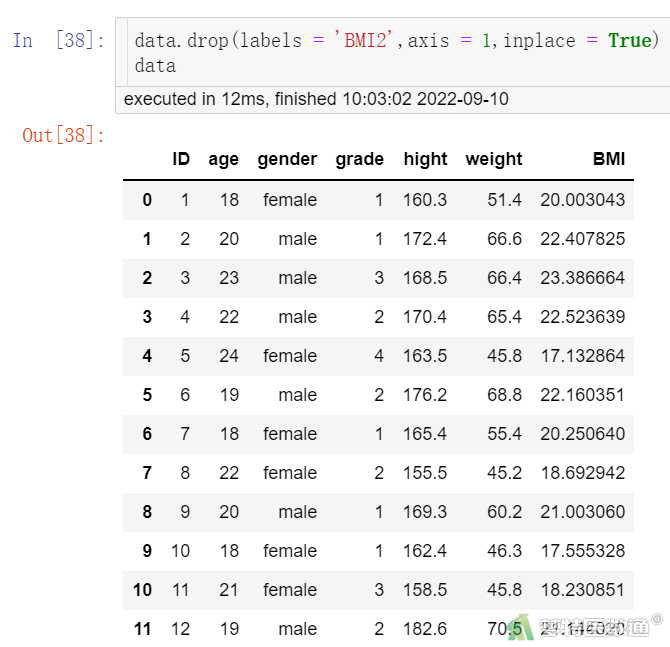
# 删除BMI2列
data.drop(labels = 'BMI2',axis = 1,inplace = True) data
drop()函数参数中,labels为需要删除的索引名称,需要同时删除多列时,传入索引列表即可;axis为控制操作轴,0为行,1为列,即0时删除行,1删除列;inplace为是否对原对象进行修改,inplace为False时,data文件中的BMI2列并不会被真正删除,为True时则删除原文件相应内容。图8可以看出数据集中已删除变量BMI2。
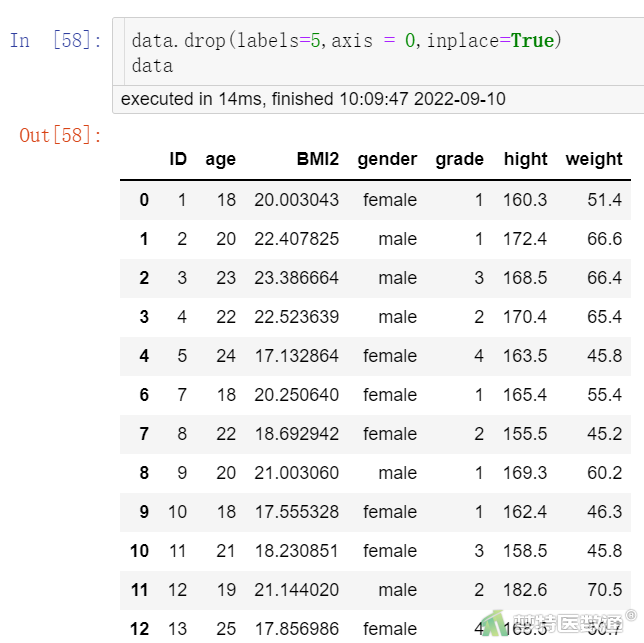
# 删除第5行数据
data.drop(labels=5,axis = 0,inplace=True)
图9可见第5行的数据被删除。,inplace为False时,data文件中的第5行数据并不会被真正删除,为True时则删除原文件相应内容。但当inplace为False时并未真正的删除data中的第5行数据。
三、变量/数据转换
在数据分析过程中,常常需要对变量重新赋值或者计算生成一个新变量,这都涉及到变量和数据的转换,下面以“data.csv”演示变量/数据转换的操作步骤。
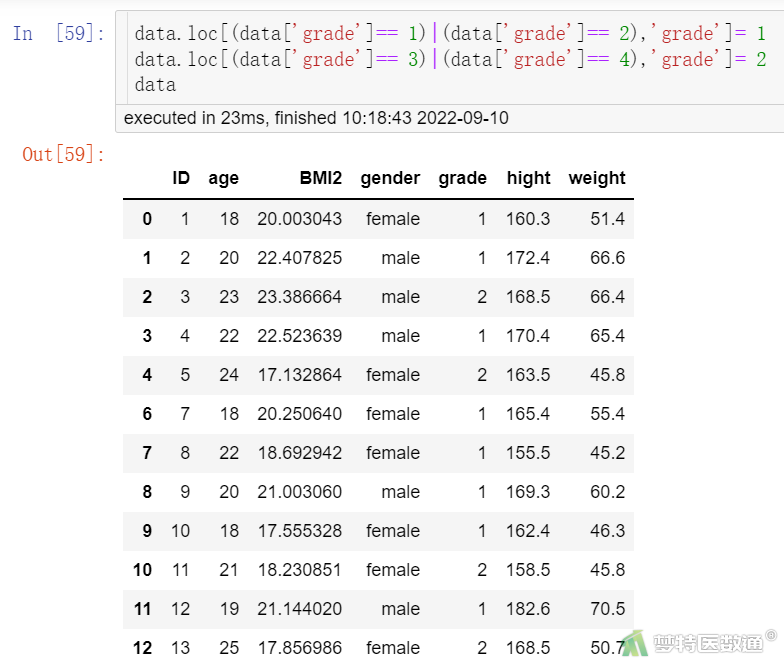
在进行数据分析之前,有时需要对变量进行相应调整,比如对于“示例数据1”,原来的“grade (年级)”变量中“1”代表大一,“2”代表大二,“3”代表大三,“4”代表大四,后面的研究中需要将大一和大二合并,大三和大四合并,此时就需要对“grade”这个变量重新编码,结果见图10。
data.loc[(data['grade']== 1)|(data['grade']== 2),'grade']= 1 data.loc[(data['grade']== 3)|(data['grade']== 4),'grade']= 2 data