在单组设计的诊断试验研究中(诊断试验(Diagnosis Test)研究概述一——设计类型),使用新试验和“金标准”比较,不专门设立对照组,以评价新试验的诊断效能。其样本量的计算,可通过单样本灵敏度与特异度检验(Test for One-Sample Sensitivity and Specificity)方法实现。
关键词:样本量计算; PASS; 诊断试验; 灵敏度和特异度; 单样本诊断试验的样本量计算; 灵敏度和特异度比较的样本量计算
灵敏度和特异度是诊断试验研究中两个重要的衡量准确性的指标。灵敏度(Se)是指受试者实际有病且被诊断试验诊断为有病的概率,反映了诊断试验检出病例的能力。特异度(Sp)是指受试者实际无病且被诊断试验诊断为无病的概率,反映了诊断试验排除病例的能力。单组设计的灵敏度和特异度检验既可以用于病例-对照研究,也可用于前瞻性研究。本文将以一项前瞻性研究为例介绍单组设计灵敏度和特异度样本量的具体计算过程及注意事项。
一、案例数据
某研究者欲评价一种新方法对某种癌症的诊断效果,希望新方法的灵敏度高于标准方法。已知该癌症在目标人群中的患病率为25%,通过查阅相关文献可知标准方法(病理活检)的灵敏度为85%,特异度为80%,希望新方法的灵敏度和特异度均能达到90%。取α =0.05,β=0.2,试估计所需的样本含量。
二、案例分析
本研究是基于灵敏度和特异度检验的诊断试验用于比较待评价的诊断试验与金标准的结果,其样本量计算需要以下几个参数:
- 疾病患病率P,即目标研究总体中患有某病的预期比例或阳性个案的比例,本例为0.25
- H0和H1下的灵敏度Se0及Se1,本例Se0=0.85、Se1=0.9
- H0和H1下的特异度Sp0及Sp1,本例为Sp0=0.80、Sp1=0.9
- 检验水准α (通常取0.01至0.1),本研究取0.05
- 检验功效1-β (通常为0.8或更高),本研究取0.8
- 脱失率(DR通常不宜超过20%),本研究取10%
三、软件操作
(一) 方法选择
在左侧界面中依次选择“Procedures (程序)”—“Sensitivity and Specificity (灵敏度和特异度)”—“Test for One-Sample Sensitivity and Specificity (单样本灵敏度与特异度检验)”,见图1。
(二) 参数设置
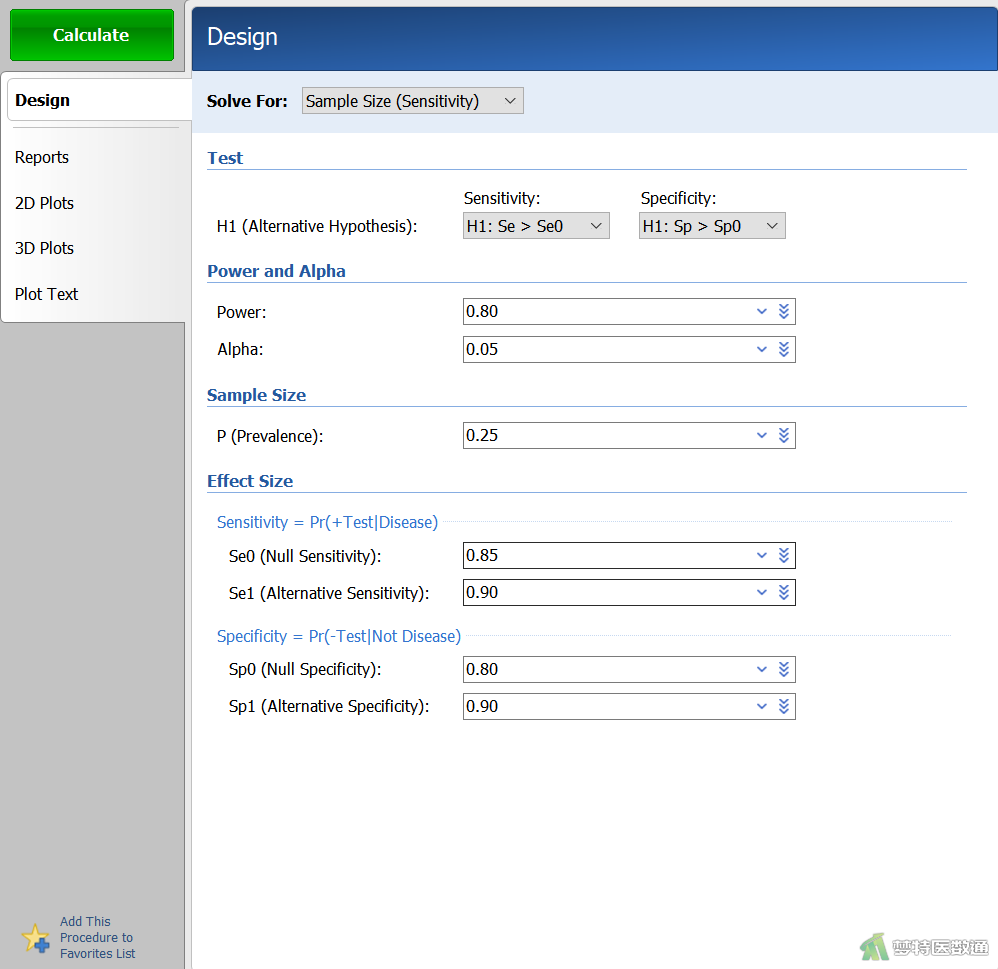
在“Design (设置)”模块中按以下参数设置相应选项(图2):
- Solve For:选择“Sample Size(Sensitivity)”,表示本计算样本灵敏度检验的样本量。
- Test:“H1(Alternative Hypothesis)”同时指定灵敏度和特异度的H1,“Sensitivity”表示灵敏度,有“H1:Se≠Se1”、“H1:Se<Se0”和“H1:Se>Se0”三种选择,本例选择“H1:Se1>Se0”。“Specificity”表示特异度,有“H1:Sp1≠Sp0”、“H1:Sp<Sp0”和“H1:Sp>Sp0”,本例选择“H1:Sp>Sp0”。
- Power and Alpha:Power为把握度,填写“0.80”;Alpha为检验水准,填写“0.05”。
- Sample Size:“P(Prevalence)”指定疾病的患者率P,即研究总体中患有该病的预期比例或阳性个案的比例,该值必须介于0~1之间。本例为0.25。
- Effect Size:“Se0 (Null Sensitivity)”设定H0下的灵敏度Se0。Se0通常为灵敏度的基线值或标准值,必须介于0~1之间,本例为0.85;“Se1(Alternative Sensitivity)”设定H1下的灵敏度Se1,即新方法的灵敏度,本例为0.90。“Sp0 (Null Specificity)”设定H0下的特异度Sp0。Sp0通常为特异度的基线值或标准值,必须介于0~1之间,本例为0.80;“Se1(Alternative Specificity)”设定H1下的特异度Se1,即新方法的特异度,本例为0.90。
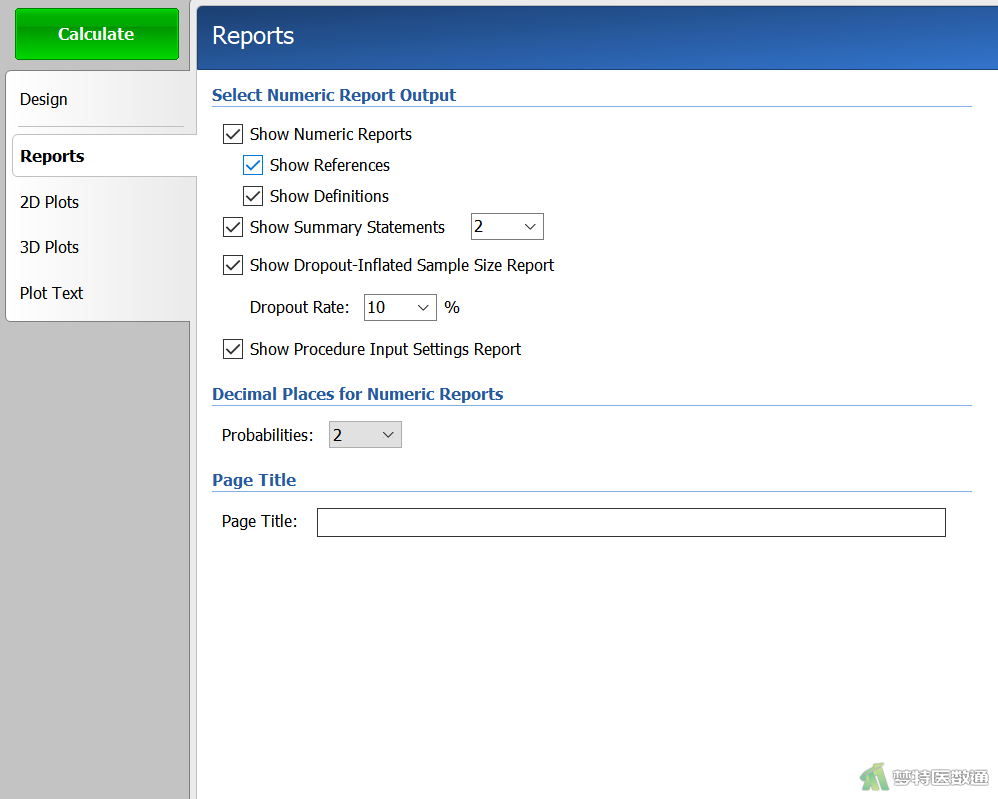
(三) 脱失率设置
在“Reports (结果报告)”模块中,勾选“Show Dropout-Inflated Sample Size Report (报告脱失样本量)”,在“Dropout Rate”中填写“10%”(图3),表示按照10%的脱失率计算样本量。设置好上述参数后点击“Calculate (计算)”。
四、结果及解释
图4列出了该研究设计的相关参数和样本量计算结果,可知计算的样本例数(N)为1124,其中患病人数N1=1124×0.25=281,无病人数N2=N×(1-P)=843。

图5“References (参考文献)”列出了该计算过程中参考的相关文献;“Report Definitions (报告定义)”列出了各个参数的具体解释;“Summary Statements (报告概述)”为整个分析报告的摘要。

图6“Dropout-Inflated Sample Size (脱失样本量)”为考虑了脱失率的样本量(N'),也是研究实际开展过程中需要达到的最低样本量,本研究中为1249,其中患病人数N1=N×P=1249×0.25=312.25≈312,无病人数N2=N×(1-P)=936.75≈937。

图7为此次样本量估算整个过程的详细参数设置汇总。

五、结论
本研究为单组设计的灵敏度和特异度检验的样本量计算,可通过灵敏度与特异度检验实现。已知某癌症在目标人群中的患病率为25%,通过查阅相关文献可知标准方法(病理活检)的灵敏度为85%,特异度为80%,希望新方法的灵敏度和特异度均能达到90%。取α =0.05,β=0.2,则需要1124例研究对象,其中患病人数N1=1124×0.25=281,无病人数N2=N×(1-P)=843。若考虑10%的脱失率,则至少需要1249例研究对象,其中患病人数N1=1249×0.25=312.25≈312,无病人数N2=N×(1-P)=936.75≈937。