关键词:Python; Python软件的特点; Python数据分析
一、Python是什么
Python是一种多用途、面向对象、交互式、解释型编程语言,同时具有代码优美、可读性强、跨平台性等诸多特点。Python创始者为荷兰程序员Guido van Rossum,其于1989年圣诞节期间开始了Python的编写工作(图1为Python官网页面)。
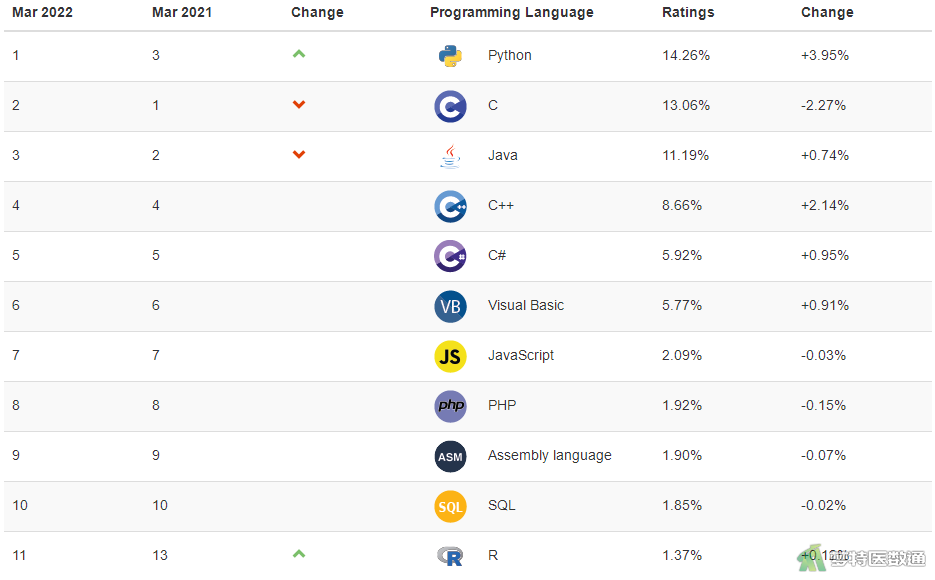
根据最新的TIOBE排行榜,Python已超越C语言和Java语言,位居编程语言第一的位置(图2)。目前Python已经被广泛应用于web开发、网络编程、网络爬虫、云计算、游戏开发、数据分析、图像识别、人工智能等众多领域,在医学领域Python也被广泛应用。
二、Python语言的特点
(一) 免费开源
Python是一门遵循GPL协议的免费开源的编程语言,任何开发者都可以自由地阅读、修改和发布它的源代码,开发者在开发和发布自己的程序时,不需要支付任何费用,也无须担心版权问题,即便是作为商业用途,Python仍然是免费的。
(二) 简单易学
Python语言语法非常接近于自然语言(英语),易于于学习和阅读代码,即便是编程语言初学者也能够轻松的开始Python的学习之旅。
(三) 可移植性
Python是一门跨平台的编程语言(可移植性强),如果代码里不涉及操作系统底层的引用,几乎可以无缝跨平台运行,支持的平台包括Windows、Linux、macOS、AIX、HPUX等。
(四) 丰富的资源库
Python具有丰富的官方及第三方资源库,比如数据分析相关的有Numpy、Pandas、Matplotlib、Scipy、Scikit-learn等资源库,这些库可以为Python提供更多的数据结构、算法、机器学习、绘图等功能支撑,是解决数据发掘、数据分析以及AI算法的必备工具。
三、Python与数据分析
在数据分析方面,Python在数据分析交互、统计分析方法、数据可视化及AI等方面都有非常成熟的库和活跃的社区,使得Python已经成为处理数据分析任务的重要解决方案。下面简单介绍部分常用的数据分析科学计算库。
(一) Numpy
Numpy是Python科学计算基础库,许多科学计算库均建立在Numpy的基础上。Numpy为Python数据分析提供高效快速的数组处理能力及算法支持能力。Numpy提供的功能有:
- 提供高效的矩阵运算和数组处理函数。
- 提供丰富的统计学计算函数,如聚合函数(均值、方差、标准差计算等)、指数函数、对数函数、三角函数、傅里叶变换等。
- 提供随机数、高级索引管理等工具。
- 实现C、C++语言库的扩展功能。
- 实现numpy对象的本地化保存和加载功能。
(二) Pandas
Pandas可提供便捷、高效的数据结构和分析函数。Pandas基于Numpy模块开发,兼具高性能的数组计算能力和数据处理能力。比如借助Pandas中DataFrame数据结构及数据处理函数,可以使开发者很轻松的实现复杂的数据处理和分析工作(DataFrame是一个面向列的二维表结构)。
(三) Scipy
SciPy 是一个开源的 Python 算法库和数学工具包。提供丰富的科学计算模块,如最优化、积分、线性代数、拟合、快速傅里叶变换、信号处理、图像处理、假设检验、常微分方程求解器等。主要包括以下功能或模块:
- 提供假设检验类分析,包括student's检验、Mann-Whitney U检验、Chi-square检验等等,由scipy.stats模块提供相关计算函数。
- 提供连续分布相关函数,如正态分布、t分布、F分布等,由scipy.stats模块提供相关计算函数。
- 提供信号处理工具scipy.signal模块。
- 提供线性代数计算scipy.linalg模块。
- 提供图像处理工具scipy.misc模块。
- 提供快速傅里叶变换scipy.fft模块。
- 提供稀疏矩阵计算工具scipy.sparse模块。
(四) Scikit-learn
Scikit-Learn是Python专门针对机器学习应用而开发的开源框架。Scikit-learn主要包含6大部分算法,分别为:数据预处理、分类、回归、聚类、数据降维和模型选择。部分功能介绍如下:
- Preprocessing:数据预处理,包括数据转换、编码、标准化等。
- Classification:分类算法,处理二分类、多分类算法,如逻辑回归、随机森林、支持向量机(SVM)、最近邻(KNN)、朴素贝叶斯、神经网络等。
- Regression:回归算法,包括线性回归、支持向量机回归(SVR)、岭回归、Lasso、弹性网络等。
- Clustering:聚类,算法包括K-均值聚类(k-Means)、均值漂移(mean-shift)、谱聚类(spectral clustering)等。
- Model selection:模型选择,算法包括网格搜索(grid_search)、交叉验证(cross_validation)、度量函数(metrics)、学习曲线(learning_curve)等。