数据的合并包括个案的合并和变量的合并,下面以“示例数据1”和“示例数据2”。演示个案合并和变量合并的操作步骤过程。
关键词:SPSS个案合并; SPSS变量合并
一、个案合并
假设“示例数据1.csv”数据库中记录了ID为1~15的15名研究对象的“age (年龄)”、“gender (性别)”、“grade (年级)”、“hight (身高)”和“weight (体重)”5个变量数据。“示例数据2.csv”数据库中记录了ID为16~30的15名研究对象的以上5个变量数据,现需要将两个数据库的数据进行合并。本文案例可从“附件下载”处下载。
① 按照上述数据读取方法同时打开“示例数据1.csv”和“示例数据2.csv”。
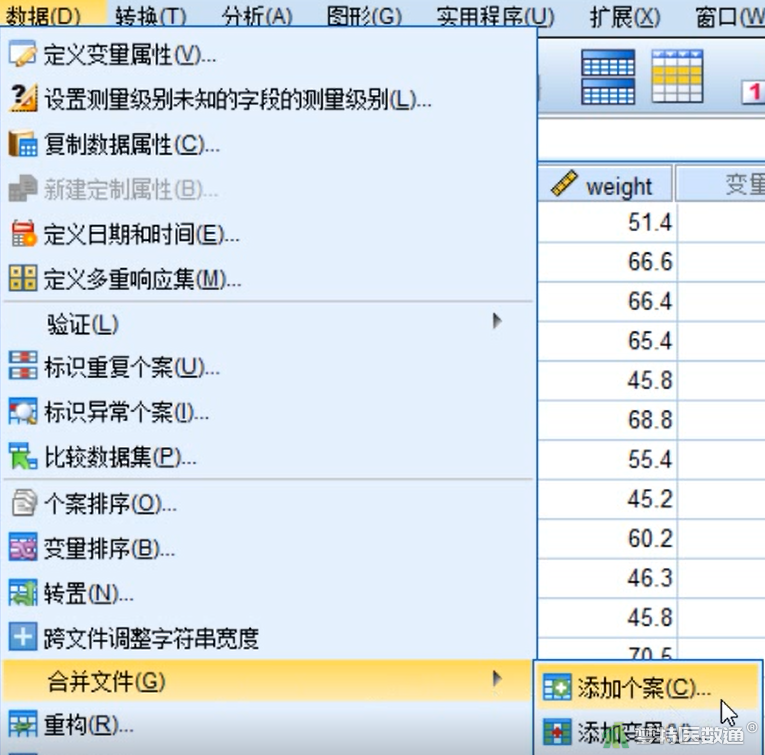
② 在“示例数据1”中选择“数据”—“合并文件”—“添加个案”(图1)。
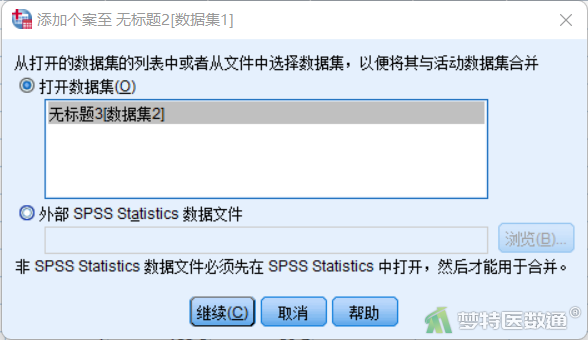
③ 在“添加个案至”对话框中选择需要添加的数据库,因为“示例数据2.sav”文件已打开,所以可以在“打开数据集”中直接选中该文件。如果需要添加的数据文件未打开,可以选中下方的“外部的SPSS Statistics数据文件”后点击“浏览”,选择本地文件。最后点击“继续”(图2)。
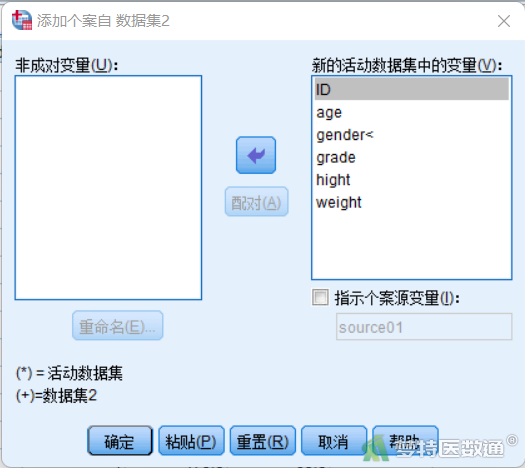
④ 出现“添加个案自”对话框,左侧为两个文件中“非成对变量”列表框,默认显示两个文件中变量名称不一致的变量,变量名称后带*表示该变量是当前活动数据集中的变量,变量名称后带+表示该变量是外部待合并数据文件中的变量。右侧为“新的活动数据集中的变量”列表框,显示需要合并的个案变量,默认显示两个文件中变量名称一致的变量,如果需要对两个文件中变量名称不一致的变量进行合并,需要对默认设置进行更改,可以选中非成对变量框中两个变量,然后点击“配对”按钮进行手动匹配。此示例中两个文件中的变量名称完全一致,可以保持默认设置,点击“确定”则完成个案合并。
二、变量合并
假设“示例数据1.csv”数据库中记录了ID为1~15的15名研究对象的“age”、“gender”和“grade”三个变量数据,“示例数据2.csv”数据库中记录了ID为1~15的15名研究对象的“hight”和“weight”两个变量数据,现需要将两个数据库的数据进行合并。
① 按照上述数据读取方法同时打开“示例数据1.csv”和“示例数据2.csv”。
② 在“示例数据1”中选择“数据”—“合并文件”—“添加变量”(图4)。
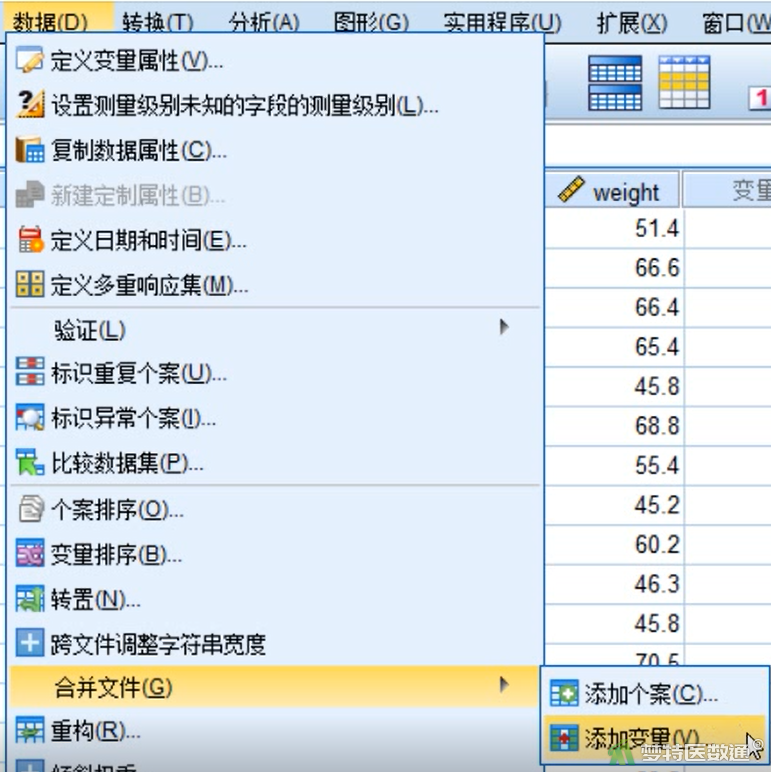
③ “变量添加自”对话框和“添加个案自”对话框功能及页面相似。在此处选择需要添加的数据库后点击“继续”。
④ 出现“变量添加自”对话框,在“合并方法”页面中选择“基于键值的一对一合并”(图5)。
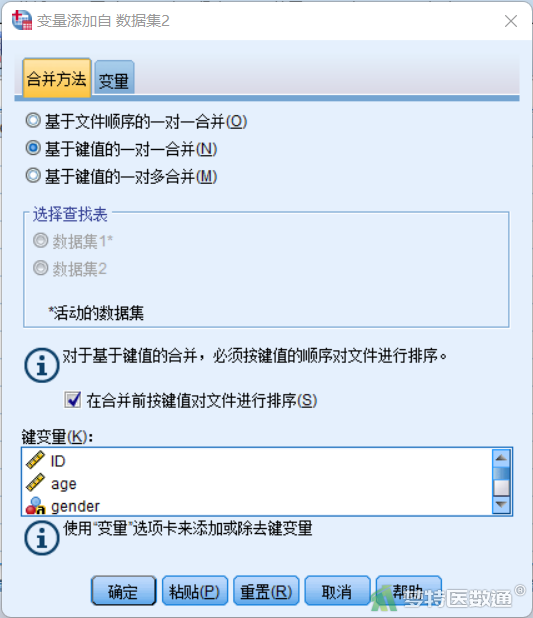
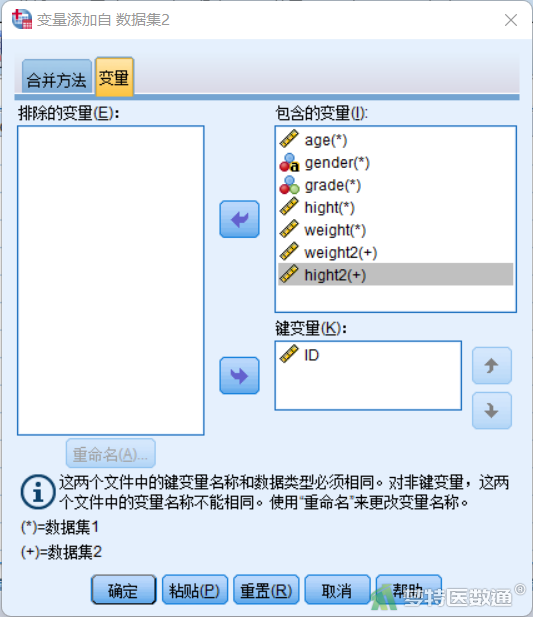
⑤ 在“变量”页面左侧为“排除的变量”列表框,此处显示不参与合并的变量。右侧“包含的变量”列表框显示参与合并的变量,其变量名后面都有*或+号,*表示该变量名是当前活动数据集中的变量,+表示该变量名是外部待合并数据文件中的变量。下方“键变量”列表框显示基于以下变量信息识别同一个案,默认放入两个文件中变量名称一致的变量(图6)。
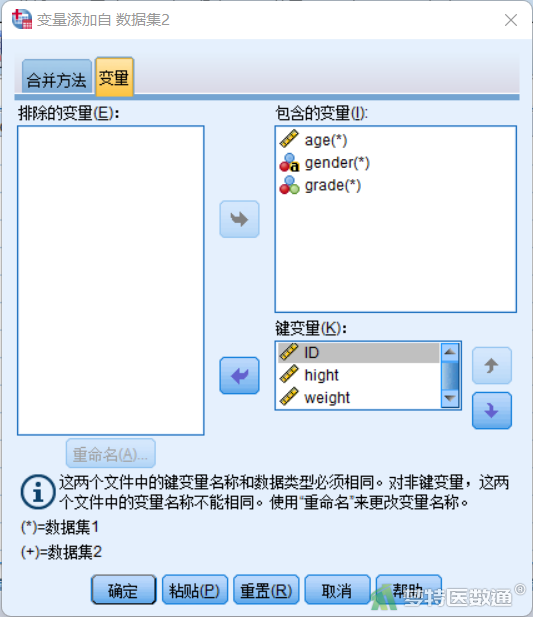
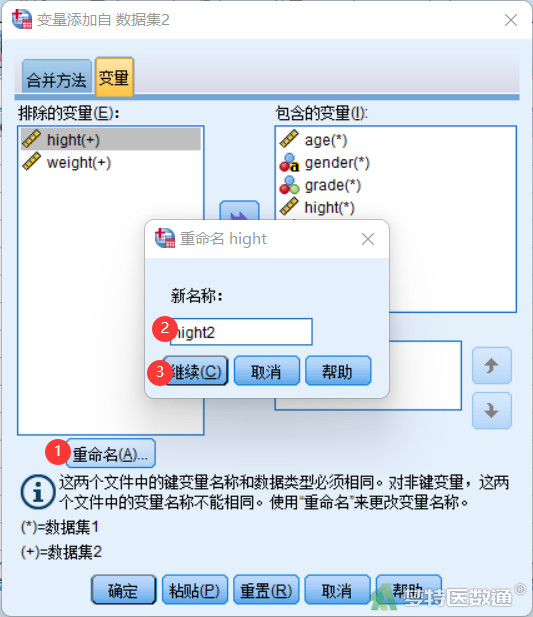
⑥ 在本示例中,关键变量选择“ID”。变量“hight”和“weight”选入左侧排除变量列表框后无法选入右侧纳入变量列表框,因为和右侧已有的变量名称有重复,若仍要合并,需要点击下方的“重命名”进行名称的更改。此处点击排除变量列表框中的变量“hight”,点击“重命名”后出现“重命名”对话框,输入“新名称”,此处改为“hight2”,点击“继续”,则完成对“hight”的重命名(图7)。相同的方法将“weight”改为“weight2”,然后可以将“hight2”和“weight2”选入右侧纳入变量列表框,最终如图8所示,点击“确定”(图8)。
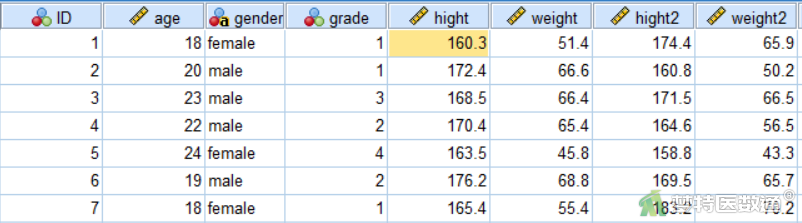
⑦ 在数据视图窗口可以看到合并后的变量(图9)。
三、数据筛选
在数据分析过程中,有时需要选择一部分数据进行分析,即选择满足一定条件的个案,比如,选择血红蛋白浓度大于160 g/L的个案人群,选择年龄大于60岁的个案人群。可以利用条件抽取、挑选出或删除符合/不符合一定条件的个案,如删除有缺失值的个案。这时就要使用数据筛选功能。以“示例数据1”演示筛选出“gender”中为“male”以及“grade”中为“2”的个案,数据筛选操作步骤:
① 同时打开“示例数据1.csv”文件。
② 选择“数据”—“选择个案” (图10)。
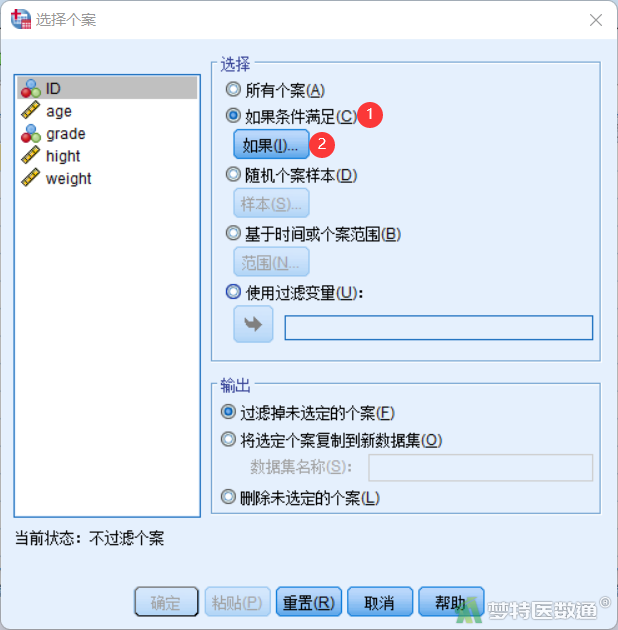
③ 在“选择个案”对话框中选择“如果条件满足”,点击下方的“如果”按钮。
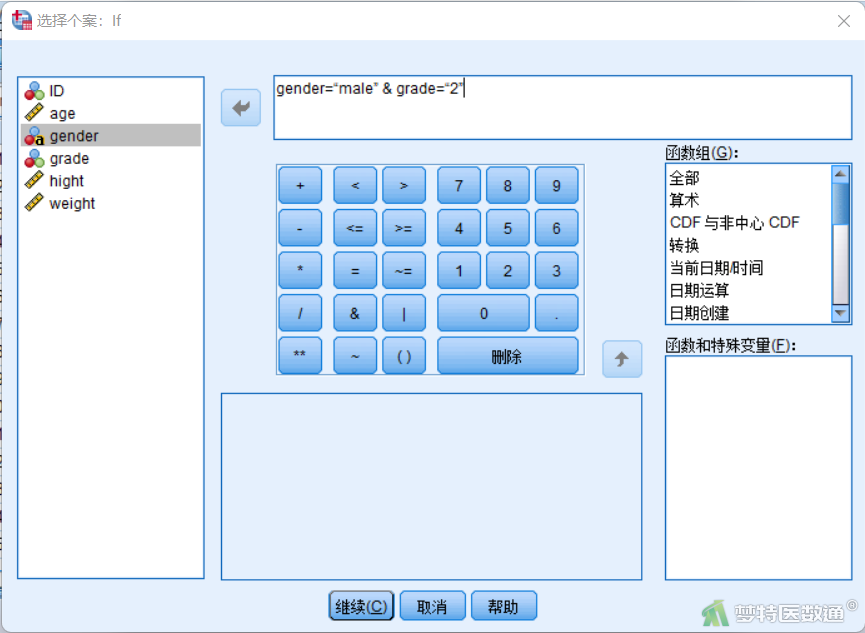
④ 在选择个案条件设置窗口中,右上方输入框输入相应的条件:gender=“male” & grade=“2”,注意需要同时满足的条件用“&”连接(图12)。
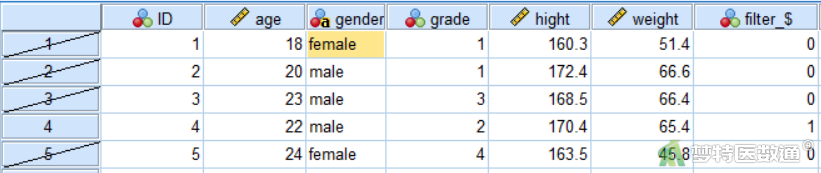
⑤ 在数据视图窗口可以看到筛选后的数据,最右侧新生成表示筛选结果的变量“filter_$”,分别以“0”和“1”表示筛选失败和筛选成功的个案。该结果也可以在最左侧的行号中看到,有斜杠的表示筛选失败(图13)。