在前面文章中介绍了多重线性回归分析的假设检验理论(链接),本篇文章将实例演示在Python软件中实现多重线性回归分析的操作步骤。
关键词:Python; 多重线性回归; 多元线性回归; 多重共线性; 自变量选择; 逐步回归; 模型拟合评价; 哑变量设置
一、案例介绍
某社区医师从本社区的糖尿病患者中随机抽取50名,收集了他们的性别(Gender,0=女,1=男)、经济水平(Income,1=低收入,2=中等收入,3=高收入)、空腹胰岛素(Fasting insulin,mmol/L)、糖化血清蛋白(Glycosylated serum protein)和空腹血糖(FBS,mmol/L),欲探究空腹血糖是否受到其他几项指标的影响。部分数据见图1。本案例数据可从“附件下载”处下载。
二、问题分析
本案例的目的是分析空腹血糖是否受到其他几项指标的影响,由于因变量是定量资料,初步考虑可使用多重线性回归分析。但需要满足以下7个条件:
条件1:样本量是自变量个数的5~10倍。本案例有4个自变量,样本量为50,满足该条件。
条件2:自变量若为连续变量,需要与因变量之间存在线性关系,可通过绘制散点图予以考察。
条件3:各观测值之间相互独立,即残差之间不存在自相关。通过研究设计和数据收集的过程分析,可判断本案例中观测值之间不存在互相影响的情况。该条件还可通过软件分析后辅助判断。
条件4:不存在显著的多变量异常值,该条件需要通过软件分析后判断。
条件5:自变量之间无多重共线性,该条件需要通过软件分析后判断。
条件6:残差符合正态(或近似正态)分布,该条件需要通过软件分析后判断。
条件7:残差大小不随所有变量取值水平的变化而变化,即方差齐性,可通过绘制残差图进行判断。
三、软件操作及结果解读
(一) 导入数据
import pandas as pd #导入pandas包
df = pd.read_csv(r"多重线性回归.csv")
pd.set_option('display.max_rows', 10) #最多显示10行数据
df
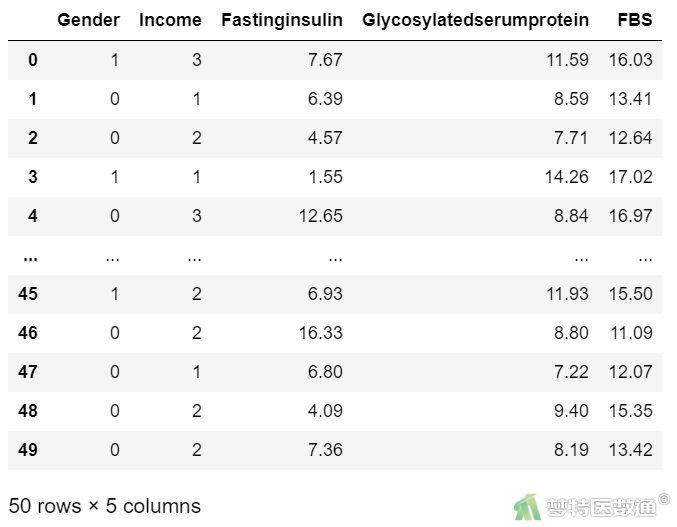
在数据栏目中可以查看全部数据情况,数据集中共有5个变量和50个观察数据,5个变量分别为性别(Gender)、经济水平(Income)、空腹胰岛素(Fastinginsulin,mmol/L)、糖化血清蛋白(Glycosylatedserumprotein)和空腹血糖(FBS,mmol/L)。
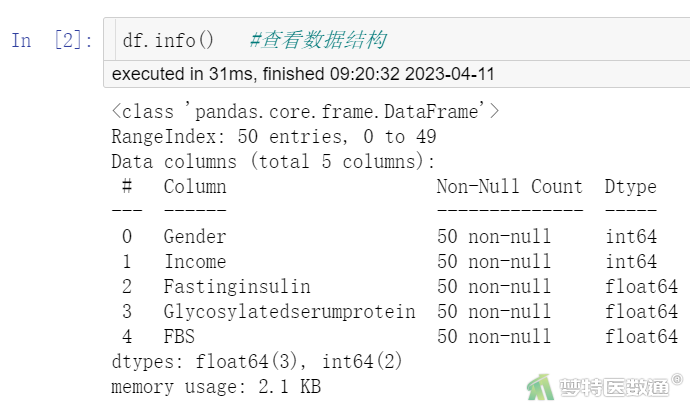
如果数据集较大也可使用如下命令查看数据框结构(图2):
df.info() #查看数据结构
(二) 适用条件判断
1. 条件2判断(连续型自变量和因变量之间存在线性关系)
(1) 软件操作
df.loc[df['Gender']==0,'Gender']='女' df.loc[df['Gender']==1,'Gender']='男' df.loc[df['Income']==1,'Income']='低收入' df.loc[df['Income']==2,'Income']='中收入' df.loc[df['Income']==3,'Income']='高收入'#转换为分组变量并添加标签 df
import seaborn as sns
import matplotlib.pyplot as plt
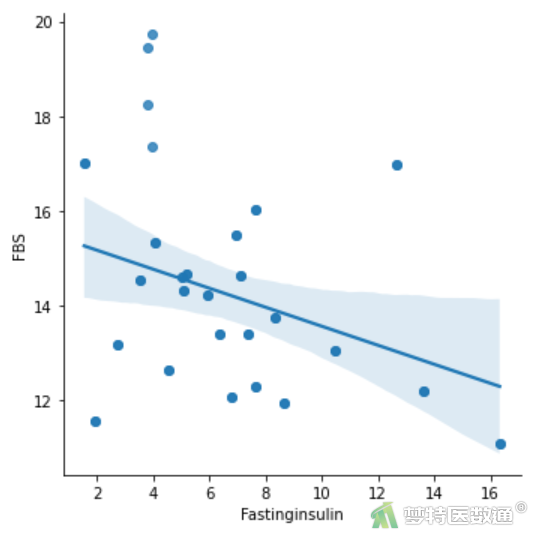
sns.lmplot(x='Fastinginsulin',y='FBS',data=df,
legend_out=False,#将图例呈现在图框内
truncate=True#根据实际的数据范围,对拟合线做截断操作
)
plt.show()#空腹胰岛素与空腹血糖的关系
sns.lmplot(x='Glycosylatedserumprotein',y='FBS',data=df, legend_out=False, truncate=True ) plt.show()#糖化血清蛋白与空腹血糖的关系
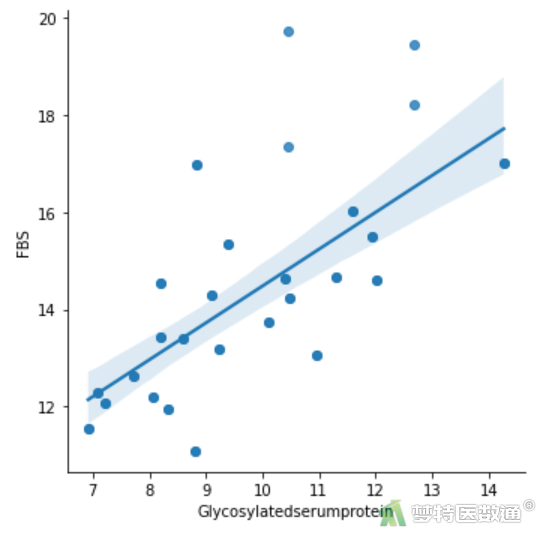
(2) 结果解读
散点图结果(图4、图5)显示,“空腹胰岛素”、“糖化血清蛋白”与因变量之间均存在线性关系。案例数据满足条件2。
2. 条件3判断(各观测值之间相互独立)
因为分类变量无法直接放入模型,这里需要对其进行转换,而多重线性回归模型中对分类变量最常用的处理方法之一便是将其转化成虚拟变量(设置哑变量)。在Python中可通过删除参照水平设置哑变量。
(1) 软件操作
#设置哑变量#
df1 = pd.get_dummies(df,columns=['Income'])
df1.drop('Income_低收入',axis = 1,inplace=True) #通过删除低收入水平,将其设置为参考变量
df1
通过逐个增加自变量的方法建立多个模型,以查看每个自变量与因变量的关联是否有统计学意义;另外对多个模型进行比较,以确定最佳模型。
#建立模型#
from statsmodels.formula.api import ols #固定格式:因变量 ~ 自变量(+ 号连接),小写的ols函数才会自带截距项,OLS 则不会
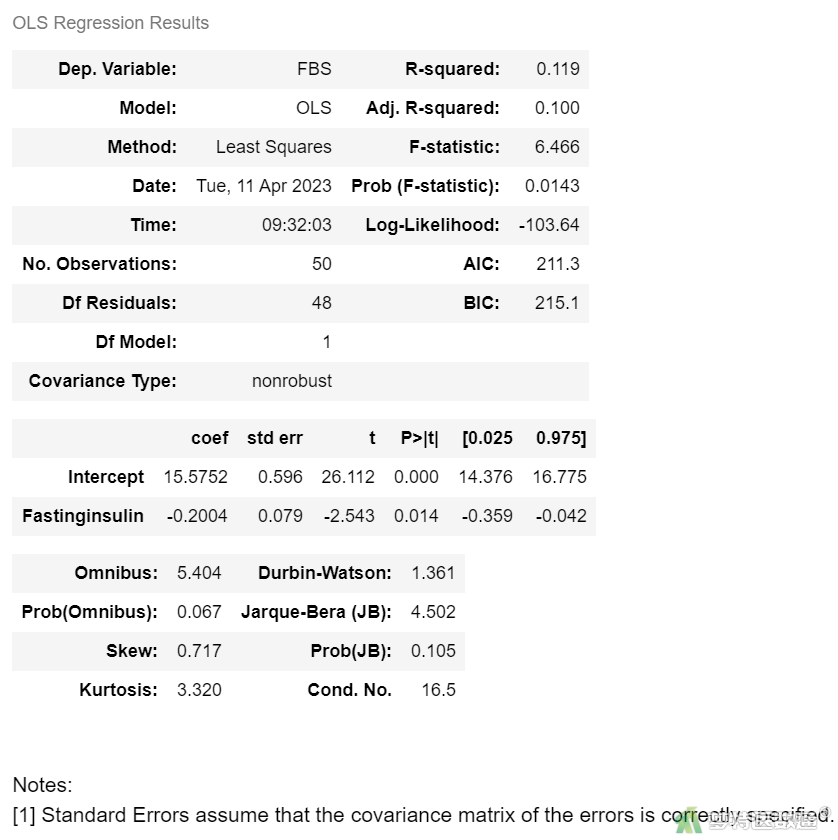
lm1 = ols('FBS ~ Fastinginsulin', data=df1).fit()
lm1.summary()
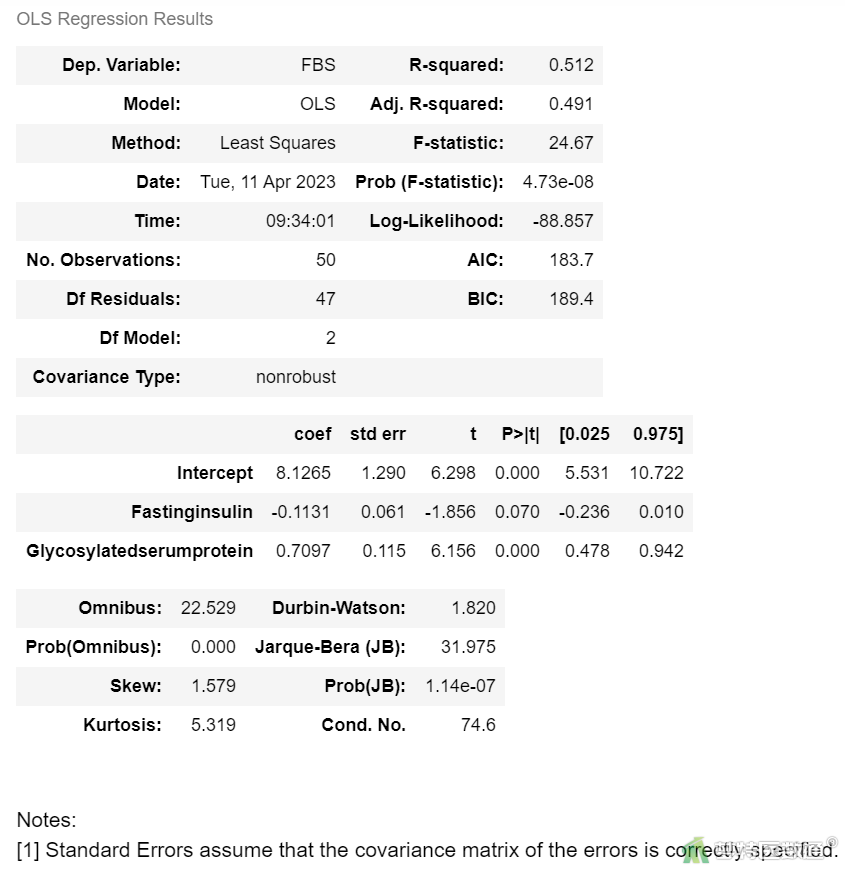
lm2 = ols('FBS ~ Fastinginsulin + Glycosylatedserumprotein', data=df1).fit()
lm2.summary()
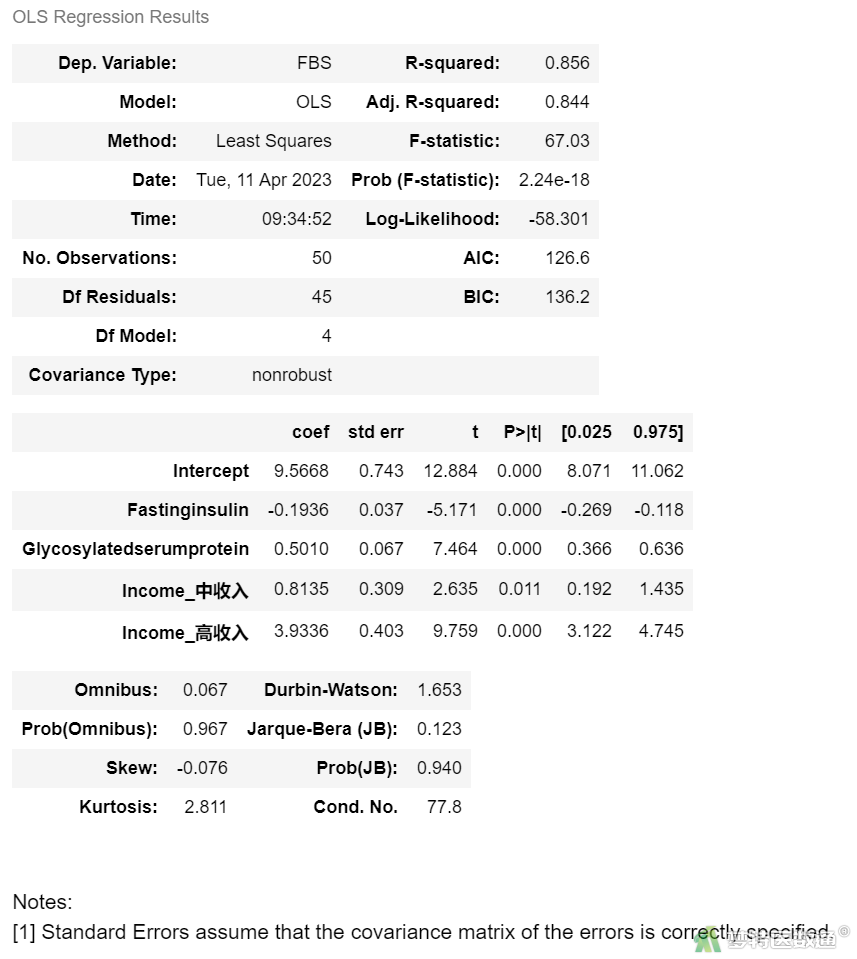
lm3 = ols('FBS ~ Fastinginsulin + Glycosylatedserumprotein + Income_中收入 + Income_高收入', data=df1).fit()
lm3.summary()
lm4 = ols('FBS ~ Fastinginsulin + Glycosylatedserumprotein + Income_中收入 + Income_高收入 + Gender', data=df1).fit()
lm4.summary()
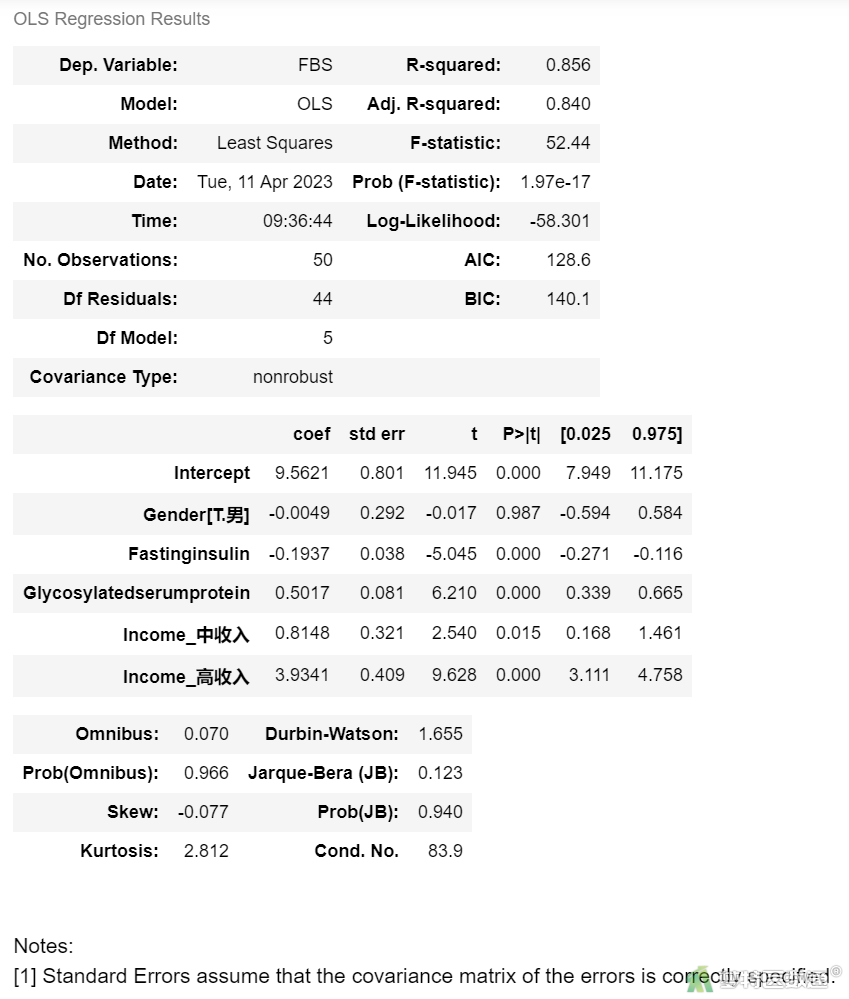
根据赤池信息准则 (Akaike Information Criterion,AIC),lmgre1选择了AIC最低的变量Fasting insulin,然后逐个加入变量,根据AIC信息准则选择最优模型lm3AIC最小,为最优模型
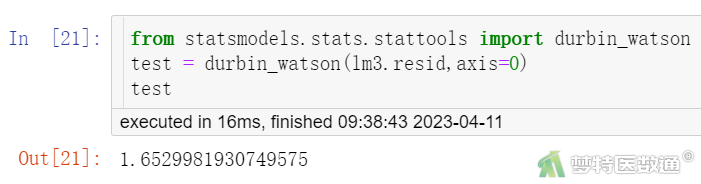
Durbin-Watson检验通常用来检测残差是否存在自相关,Durbin-Watson检验值分布在0~4之间,越接近2,观测值相互独立的可能性越大。需要注意的是,判断观测值是否独立,主要取决于研究设计和数据收集阶段的质量控制,Durbin-Watson检验最好用于辅助判断。
##判断独立性##
from statsmodels.stats.stattools import durbin_watson test = durbin_watson(lm3.resid,axis=0) test
(2) 结果解读
“durbinWatsonTest (Durbin–Watson自相关检验)”结果(图11)显示,DW Statistic为1.653,说明观测值相互独立,本研究数据满足条件3。
3. 条件4判断(不存在显著的多变量异常值)
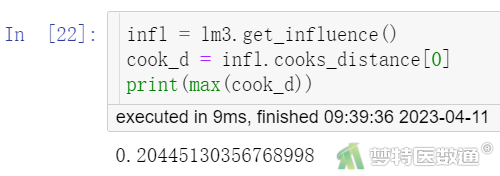
库克距离 (Cook’s distance)用来判断强影响点是否为因变量的异常值点。一般认为当D<0.5时不是异常值点,当D>0.5时认为是异常值点。
(1) 软件操作
##计算cook距离##
infl = lm3.get_influence() cook_d = infl.cooks_distance[0] print(max(cook_d))
(2) 结果解读
“Cook’s distance”结果(图12)显示,最大Cook’s D (distance)为0.204<0.5,提示不存在显著异常值,本研究数据满足条件4。
4. 条件5判断(多重共线性判断)
(1) 软件操作
##共线性诊断##
data_ls = df1[['Fastinginsulin','Glycosylatedserumprotein','Income_中收入','Income_高收入','FBS']].copy() from statsmodels.stats.outliers_influence import variance_inflation_factor vif = [variance_inflation_factor(data_ls.drop(['FBS'],axis = 1), i) for i in range(data_ls.drop(['FBS'],axis = 1).shape[1])] pd.DataFrame(data = zip(data_ls.drop(['FBS'],axis = 1),vif),columns = ['变量','vif'])
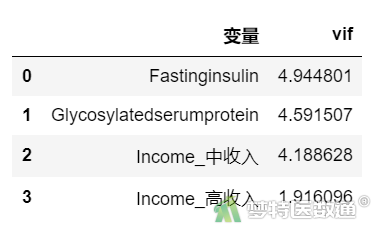
(2) 结果解读
“vif (variance inflation factor,方差膨胀因子)”结果(图13)显示,所有自变量的VIF均<10,提示自变量之间不存在严重共线性问题。
5. 条件6判断(残差服从正态分布)
(1) 软件操作
##正态性检验##
from scipy.stats import shapiro shapiro(lm3.resid)

##Q-Q图##
import statsmodels.api as sm #导入statsmodels.api包 import pylab sm.qqplot(lm3.resid,line='q') pylab.show()
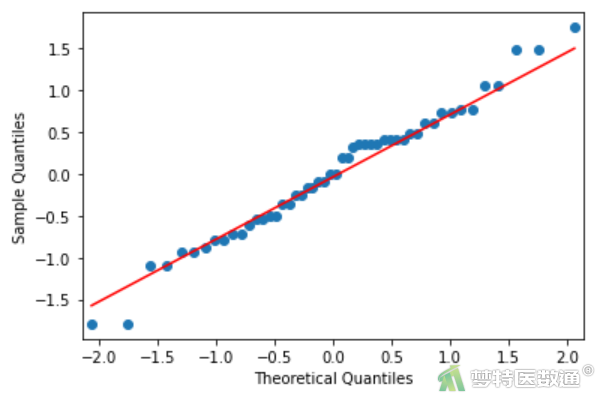
(2) 结果解读
“Shapiro-Wilk (夏皮罗-威尔克正态性检验)”(图14)显示,P=0.7>0.1,提示残差服从正态分布。残差的Q-Q图(图15)中各散点基本围绕对角线分布,也提示残差服从正态分布。因此,判定本研究数据满足条件6。
6. 条件7判断(方差齐)
(1) 软件操作
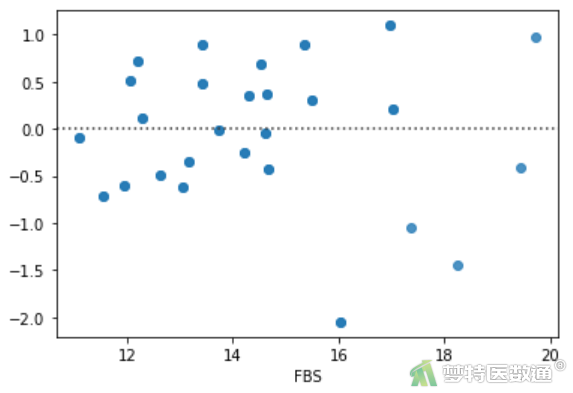
##残差图##
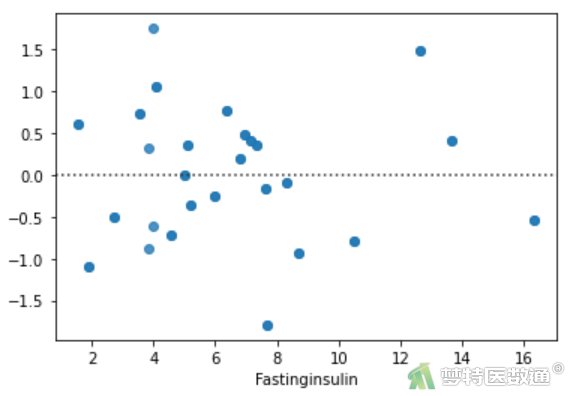
import matplotlib.pyplot as plt import seaborn as sns sns.residplot(df1.loc[:,'FBS'],lm3.resid) plt.show()
sns.residplot(df1.loc[:,'Fastinginsulin'],lm3.resid) plt.show()
sns.residplot(df1.loc[:,'Glycosylatedserumprotein'],lm3.resid) plt.show()
(2) 结果解读
预测值和各变量值的残差分布结果(图16~18)显示其分布较为均匀,并未出现特殊的分布形式(如漏斗或者扇形),提示残差的方差齐,本研究数据满足条件7。
(三) 模型拟合
(1) 拟合优度
OLS Regression Results (图9)显示,最终模型的决定系数为0.856,校正决定系数为0.844,表明模型整体拟合较好。
(2) 模型系数
OLS Regression Resultsc (图9)的Coef部分列出了截距和自变量的“Intercept (非标准化系数)”、“Std.Error (标准误)”,统计量t值及P值。结果显示模型中的所有自变量均有统计学意义(P<0.001)。
回归模型的截距为9.567,表示自变量取值为0时,因变量的取值,并无实际专业意义。变量“空腹胰岛素”的非标准化系数(即斜率)为-0.194 (95% CI:-0.269~-0.118,P<0.001),表示“空腹胰岛素”每增加1mmol/L,空腹血糖减少0.194 mmol/L;变量“糖化血清蛋白”的非标准化系数(即斜率)为0.501 (95% CI:0.366~0.636,P<0.001),表示“糖化血清蛋白”每增加1%,空腹血糖增加0.501 mmol/L。相比“低收入”人群而言,“中等收入”人群的非标准化系数为0.814 (0.192~1.435,P=0.011),表示“中等收入”人群比“低收入”人群空腹血糖高0.814 mmol/L;相比“低收入”人群而言,“高收入”人群的非标准化系数为3.934 (3.122~4.745,P<0.001),表示“高收入”人群比“低收入”人群空腹血糖高3.934 mmol/L。
据此可以写出本案例的回归方程为:
空腹血糖 = 9.567 - 0.194×空腹胰岛素 + 0.501×糖化血清蛋白+ 0.814×(经济水平=中等收入) + 3.934×(经济水平=高收入)
根据此方程输入相关自变量数值即可对空腹血糖进行预测。
四、结论
本研究采用多重线性回归模型考察“空腹血糖”是否受到性别、经济水平、空腹胰岛素和糖化血清蛋白的影响。通过绘制散点图,提示空腹胰岛素和糖化血清蛋白与空腹血糖之间存在线性关系,通过专业判断和Durbin-Watson检验提示数据之前相互独立,通过库克距离分析,提示数据不存在需要删除的异常值;通过方差膨胀因子和容忍度判断自变量之间不存在严重多重共线性,通过Shapiro-wilk检验及绘制残差Q-Q图,提示残差服从正态分布;通过绘制残差图,提示残差方差齐。满足多重线性回归分析条件。
多重线性回归分析结果解读为,在其他变量不变的情况下,“空腹胰岛素”每增加1 mmol/L,空腹血糖减少0.194 mmol/L (β=-0.194,P<0.001);“糖化血清蛋白”每增加1%,空腹血糖增加0.501 mmol/L (β=0.501, P<0.001);“中等收入”人群比“低收入”人群空腹血糖高0.814 (β=0.814, P=0.011);“高收入”人群比“低收入”人群空腹血糖高3.934 (β=3.934, P<0.001)。
线性回归分析方程为:
空腹血糖 = 9.567 - 0.194×空腹胰岛素 + 0.501×糖化血清蛋白+ 0.814×(经济水平=中等收入) + 3.934×(经济水平=高收入)。回归模型具有统计学意义,F=67.03,P<0.001;模型可以解释84.4%的因变量的变异 (adjusted R2=0.844)。
五、分析小技巧
(一) 各观测值之间的独立性检测
判断观测值是否独立,主要取决于研究设计和数据收集阶段的质量控制,Durbin-Watson检验最好用于辅助判断。Durbin-Watson检验值分布在0~4之间,越接近2,观测值相互独立的可能性越大。且根据Pr <DW和Pr >DW,可得知正相关检验和负相关检验的P值大小,更容易客观的判断独立性。
(二) 异常值检测
- Cook’s D(库克距离)用来判断强影响点是否为因变量的异常值点。一般认为当D<0.5时不是异常值点,当D>0.5时认为是异常值点。
- 并非所有的异常点都意味着结果不好,有时候发现异常点可能会提示有更重要的信息。如果出现异常点,首先应检查数据是否录入错误,也可以选择其他相应模型来拟合,或者需要收集更多的数据来证实。
(三) 残差的正态性检测
如果残差不符合正态分布,可以考虑对因变量进行数据变换,使其服从正态分布后再拟合线形回归模型。
(四) 残差的方差齐性检测
残差的方差齐是指在自变量取值范围内,对于任意自变量取值,因变量都有相同的方差。线形回归中,残差的方差齐实际上要比残差正态分布重要。如果这一条件不满足,可对因变量进行变量变换,使其满足残差方差齐,也可以采用加权回归分析,消除方差的影响。
(五) 变量筛选
- 多重回归分析中,变量的筛选一般有向前筛选(selection=forward)、向后筛选(selection=backward)、逐步筛选(stepwise)三种基本策略。
- 向前筛选是变量不断进入回归方程的过程。首先,选择与因变量具有最高线性相关系数的变量进入方程,并进行回归方程检验;其次,在剩余的变量中寻找与因变量偏相关系数最高的变量进入回归方程,并对新建立的回归方程进行检验;一直重复这个过程,直到再也没有可进入方程的变量为止。
- 向后筛选是变量不断剔除出回归方程的过程。首先,所有变量全部引入回归方程,并对回归方程进行检验,然后在回归系数不显著的变量中,剔除t检验值最小的变量,并对模型进行检验;直到回归方程中所有变量的回归系数均显著,则回归模型确定。
- 逐步筛选在向前筛选的基础之上,结合向后筛选策略,在每个变量进入方程后再次判断是否存在可以剔除方程的变量。因此,逐步筛选在引入变量的每一个阶段都提供了剔除不显著变量的机会。
(六) 回归模型
在进行回归分析时,要注意避免对数据的过渡挖掘,不能将回归模型分析的结果随意延伸到自变量取值范围以外的数值。也不能随意将模型分析结果延伸到因果关系。
(七) 模型评价
常见的回归模型评价指标有:决定系数R2、校正决定系数adjusted R2和均方根误差RMSE等。实际分析时,可以综合多个指标,并结合模型所反映的实际情况来判断。
- 决定系数R2 (determination coefficient)反映了因变量的变异能够被自变量解释的比例,或者说方程中的自变量解释了因变量变异的多少。R2越大,表示方程中自变量解释能力越强。但该指标有一缺陷,即其值随着自变量的增多而增加,即使加入无意义的变量,该指标值也会随之增加,因此不能较好地反映模型优劣。
- 校正决定系数adjusted R2(adjusted determination coefficient) 是对决定系数的修正。当有统计学意义的变量进入方程时,该指标随之增大,而当无统计学意义的变量进入方程时,其值减小。值越大表明模型越好,是衡量模型优劣的重要指标之一。
- 均方根误差RMSE主要反映模型的估计精度,值越小越好。一般会随模型中自变量个数增加而减小,这一性质与校正系数相似。