因子分析的核心思想是寻找公因子,以达到降维的目的,探索性因子分析和验证性因子分析是其两大主要类型。探索性因子分析(exploratory factor analysis, EFA)主要是为了初步找出因子个数以及因子下各个观测变量的组成、相关程度,以进一步为改进因子结构提供依据。在量表的效度评价中,探索性因子分析和验证性因子分析(confirmatory factor analysis, CFA)较为常用。本文实例演示在jamovi软件中进行探索性因子分析的操作步骤。
关键词:jamovi; 主成分分析; 探索性因子分析; 验证性因子分析; 多元统计分析
一、案例介绍
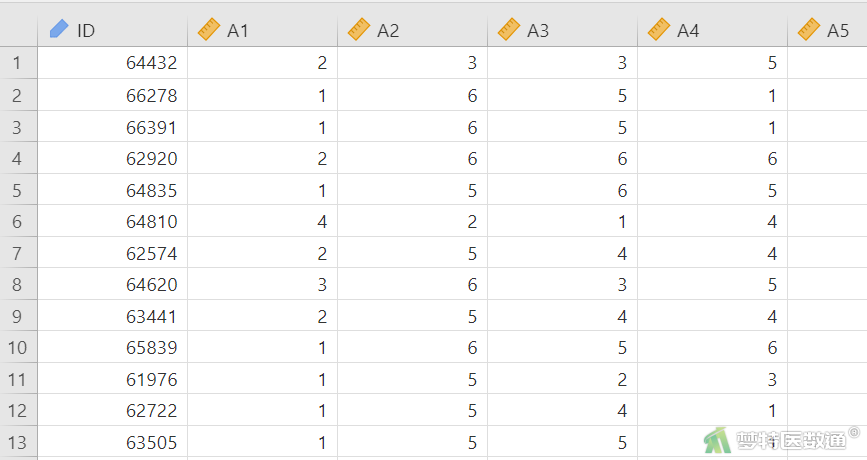
使用一份心理人格量表调查了250名受试者,所用量表包含A1~A5(其中A1为反向条目)、C1~C5(其中C4、C5为反向条目)、E1~E5(其中E1、E2为反向条目)、N1~N5,O1~O5(其中O2、O5为反向条目) 5个维度(A、C、E、N和O)共25个条目。现希望使用探索性因子分析对此份量表数据的结构效度进行分析,并对量表进行改进。部分数据见图1,本案例数据可从“附件下载”处下载。
二、问题分析
由于本研究的量表是一个初步量表,已经初步设置了5个维度及其相应的条目,因此分析时最好选用探索性因子分析,并且固定因子数目为5。但需要满足4个条件:
条件1:数据是以量表形式进行整理和呈现的,对于非量表类数据不合适。本研究是一个初步量表,并设置了相应维度和对应的条目,该条件满足。
条件2:样本例数>分析条目数的5倍,总样本通常不低于100。本研究25个条目,其5倍数量为125,总样本250满足该条件。
条件3:Kaiser-Meyer-Olkin (KMO)系数≥0.6。该条件需要通过软件分析后判断。
条件4:Bartlett检验有统计学意义(P<0.05)。该条件需要通过软件分析后判断。
三、软件操作及结果解读
(一) 数据整理
由于条目中存在反向计分条目,为了后续计算、结果解读的方便,在进行数据分析之前先将反向计分条目进行转换。
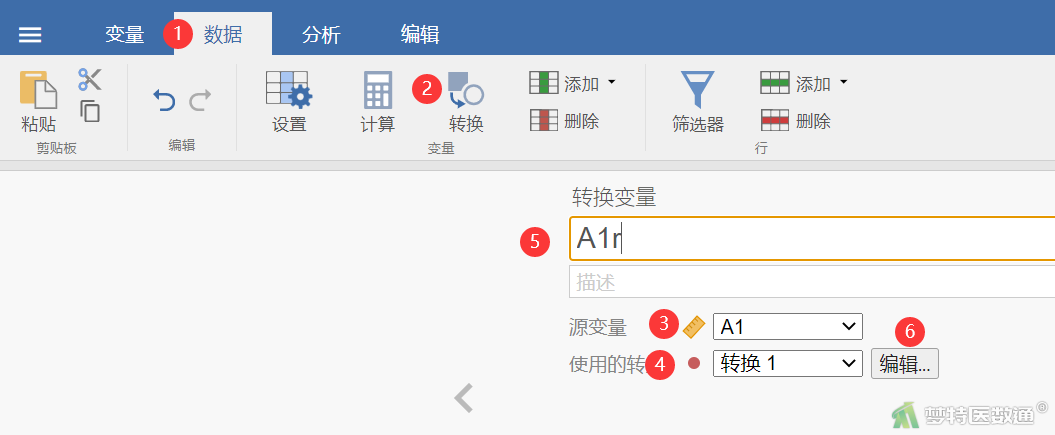
(1)选择“数据”—“转换”;在“源变量”中选择“A1”,表示需要对条目“A1”进行转换;然后在“使用的转换(翻译为‘转换用于’更好)”中选择“创建新的转换(翻译为‘转换后创建一个新的变量’更好)”,表示转换成一个新的条目,此时右边的“编辑”按钮变为可编辑状态;在“转换变量”中输入“A1r”,表示新条目的名字;点击“编辑”(图2)。
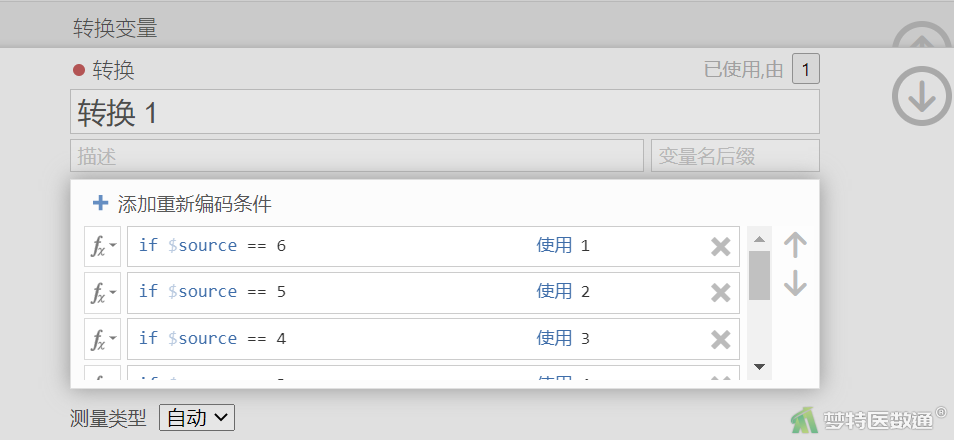
(2)点击“添加重新编码条件”,在公示框中“if $source”后选择“==”,并输入“6”,在“使用”后输入“1”,表示将条目中的“6”替换为“1”;其余以此类推(图3)。
(3)此时在数据集中生成了一列新的条目“A1r”(图4),是反向计分条目A1的正向计分条目。

(4)以此类推对其余反向计分条目进行转换。
(二) 适用条件判断
1. 条件3判断(MSA检验)
(1) 软件操作
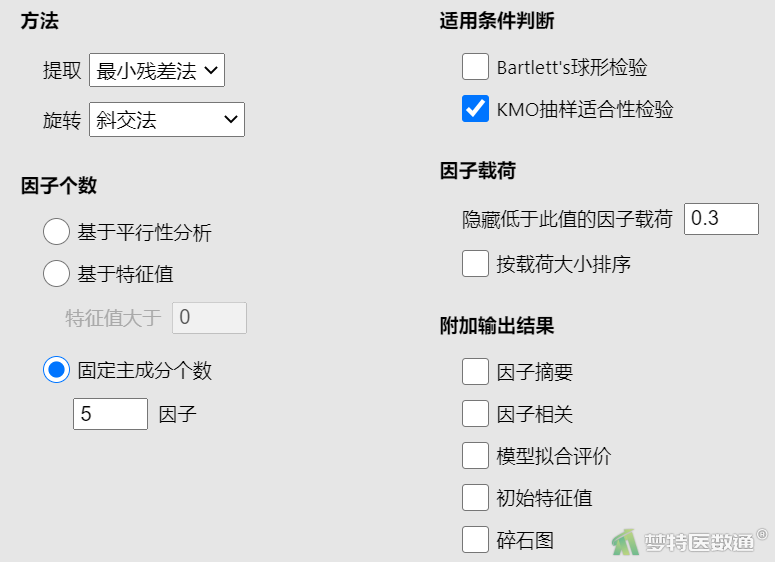
①选择“分析”—“因子”—“探索性因子分析”,将需要分析的25个条目(反向计分条目需要选择转换后的条目)选入右侧“变量”框(图5)。

②在“因子个数”中选择“固定主成分个数”,并在框中输入“5”,在“适用条件判断”中勾选“KMO抽样适合性检验”(图6)即可。

(2) 结果解读
“KMO抽样适合性检验”结果(表1)显示,“整体”MSA系数为0.808,提示数据抽样充分,结构很适合进行因子分析。
KMO系数是抽样适合性检验(measure sampling adequacy)的系数,该检验是对原始条目之间的简单相关系数和偏相关系数的相对大小进行检验,如果原始数据中确实存在公因子,则各条目之间的偏相关系数应该很小,这时KMO值接近于1,因此,数据适合于因子分析。在因子分析中,该指标的最低标准为0.60,0.61~0.70为勉强适合,0.71~0.80为适合,0.81~0.90为很适合,>0.90为非常适合。
如果分析过程中出现KMO值分析结果报错或不存在的情况可从以下几个方面进行核查和改进:
- 是否存在异常值;
- 是否放入了无序多分类数据进行分析;
- 样本量是否过少,样本量过少容易导致相关系数过高;
- 分析条目之间的相关系数过低或过高:系数过低(比如小于0.2或没有显著性),信息重叠度低无法有效浓缩信息,会导致KMO值较低;系数过高(比如大于0.8),会导致严重共线性,可能无法输出KMO值;分析条目之间的相关系数值介于0.3~0.7之间较好。
2. 条件4判断(Bartlett检验)
(1) 软件操作
在“适用条件判断”中勾选“Bartlett’s球形检验”(图7)。


(2) 结果解读
“Bartlett’s球形检验”结果(表2)显示,χ²=2204.278,P<0.001,拒绝零假设,提示数据结构适合进行因子分析。
Bartlett检验的零假设是研究数据之间的相关矩阵是一个完美矩阵,即所有对角线上的系数为1,非对角线上的系数均为0。在这种完美矩阵的情况下,各条目之间没有相关关系,即不能将多个条目简化为少数的成分,没有进行探索性因子分析的必要。因此希望拒绝Bartlett检验的零假设。
(三) 因子载荷分析
EFA分析最重要的目的就是判断维度和题目对应关系是否与专业预期符合,主要依据就是判断各条目在预期维度上的载荷是否合理。
1. 软件操作
在“因子载荷”中的“隐藏低于此值的因子载荷”框中输入“0.3”,表示在结果表格中将载荷低于0.3的系数隐藏掉,这样方便阅读(图6),结果见表3。

2. 结果解读
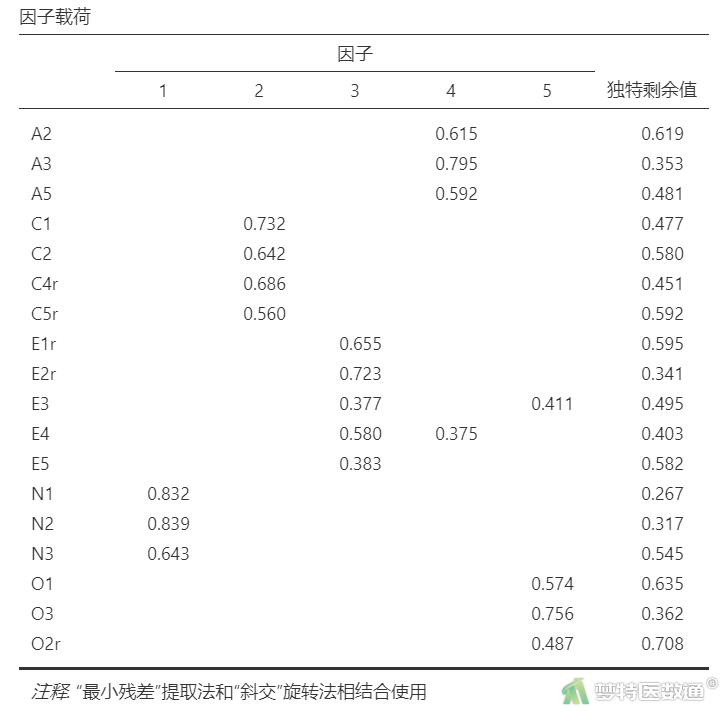
“因子载荷”结果(表3)列出了各个条目在每个维度上的因子载荷,一般要求>0.4。可见A1r~A5均在维度4下面,且均载荷>0.4;C1~C5r均在维度2下面,并且均载荷>0.4;E1r~E5在维度3下面均有载荷>0.4,但E3还在维度5下有一定载荷(0.386),E4还在维度4下有一定载荷(0.362),这种现象叫做“混乱不清”;N1~N5在维度1下面均有载荷>0.4,但N4还在维度3下有一定载荷(0.453);O1~O5r中有四个在维度5下,且载荷>0.4,但O4却落在了维度4下,出现了“错分”的情况。
在EFA分析过程中最重要的就是处理“错分”现象,让条目落在预期专业的维度下面。对于“混乱不清”的现象,则根据具体情况灵活处理。此处,先删除O4条目后重新分析。
3. 改进分析
删除O4条目后重新分析因子载荷的情况(表4)显示,各个条目均在本维度下具有较好的载荷(>0.4),已不存在“错分”的情况。但N4同时在维度1和维度3下面具有较高的载荷(>0.4),存在较为严重的“混乱不清”现象,因此,需要删除N4。

删除N4条目后重新分析因子载荷情况见表5。可见各个条目均在本维度下具有较好的载荷(>0.4),已不存在“错分”的情况。尽管E3和E4存在“混乱不清”现象,但是其在别的维度下的均载荷<0.4,对此种情况可删除也可保留。本案例中暂且保留。

条目出现“错分”和“混乱不清”是EFA分析过程中常见的现象,但最为关注的是“错分”情况,需要优先处理,一般是待处理完条目“错分”情况后再处理“混乱不清”的现象。
对出现“混乱不清”的条目,通常是按照条目落在非预期维度下的载荷系数高低进行逐个删除,一般在非预期维度下载荷系数>0.4的条目先删除。对于在非预期维度下载荷系数<0.4的条目多根据专业意义和条目数量进行综合考虑。如果该条目具有重要的专业意义,必须保留,或者该维度下剩余的条目数不多(如只有3条),则可先予以保留。
(四) 公因子方差
公因子方差反映了提取的主成分对各个条目信息的代表程度,一般要求公因子方差>0.4。jamovi在EFA分析后,在“因子载荷”表格(表5)中的“独特剩余值”表示每个条目被提取的主成分不能解释的部分,即1-公因子方差。一般要求<0.6,本案例结果(表5)显示,存在8个条目的公因子方差<0.4。按照独特剩余值从大到小,并综合考虑条目的专业意义及该维度内剩余的条目数进行逐步删除、分析,本案例逐步删除了C3、A1r、N5、A4、O5r后,分析结果见表6。尽管仍然存在3个条目的独特剩余值>0.6,但考虑到该维度内剩余的条目数不能太少,所以均予以保留。
【注意】
- 每个条目删除后,其余条目的公因子方差值(或独特剩余值)会重新计算,因此根据公因子方差删除条目时,要按照独特剩余值从大到小的顺序逐个删除。
- 根据公因子方差删除条目时,除了考虑独特剩余值的大小以外,该条目的专业意义和维度内剩余条目数也需要加以考虑。如果该条目具有重要的专业意义,则必须保留;若该维度下剩余的条目数不多(如只有3条),则可先予以保留。
(五) 方差解释率
EFA分析的主要目的是通过选取的主成分因子(维度)对数据进行降维,但同时也要注意应尽可能多的包含对数据变异的解释。
1. 软件操作
在“附加输出结果”中,勾选“因子摘要”(图8),结果见表7。

2. 结果解读
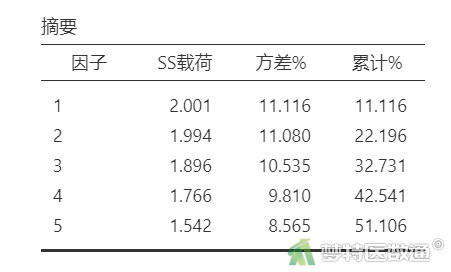
“摘要”结果(表7)显示,每个主成分因子(维度)的解释率都>5%,累计方差解释率为51.106%。表明五个维度可以提取的量表信息程度一般,综合说明研究数据结构效度一般。
一般认为,提取的每个主成分因子至少应解释5%~10%的数据变异。关于累计解释率对于不同专业有不同要求,对于医学专业而言,一般要求提取的主成分应累积解释60%~70%的数据变异;对于社会学往往不容易达到较高的比例。此外,在EFA过程中,若使用的量表并非成熟的权威量表,往往总方差解释率不可能达到很高。但对于一个成熟、通用的量表,若累计方差解释率太低则表明数据的结构效度不是很理想。
(六) 其他指标解读
1. 因子相关性
在“附加输出结果”中,勾选“因子相关”(图9),结果见表8。
“因子间相关性”结果(表8)显示了各个维度之间的相关性,至少需要满足有一个相关性>0.3。本案例中维度2与维度3之间,维度3与维度4、维度5之间,维度4与维度5之间的相关性均>0.3。


2. 模型拟合评价
常用判断指标包括:
(1)模型整体拟合判断:P>0.05;
(2)卡方/自由度比(χ²/df):<3;
(3)近似均方根误差(root mean square error of approximation,RMSEA):<0.1为合适,<0.05为优秀;
(4)塔克·刘易斯指数(Tucker Lewis index,TLI):>0.9为合适,>0.95为优秀;
(5)贝叶斯信息准则(Bayesian information criterion,BIC):越小越好。
在“附加输出结果”中,勾选“模型拟合评价”,结果见表9。
“模型拟合评价”结果(表9)显示,模型整体拟合P<0.001,表示模型拟合较差;χ²/df=124.052/73=1.70<3,满足要求;近似均方根误差=0.053<0.1,为合适;TLI指数=0.922>0.9,为合适。

3. 碎石图
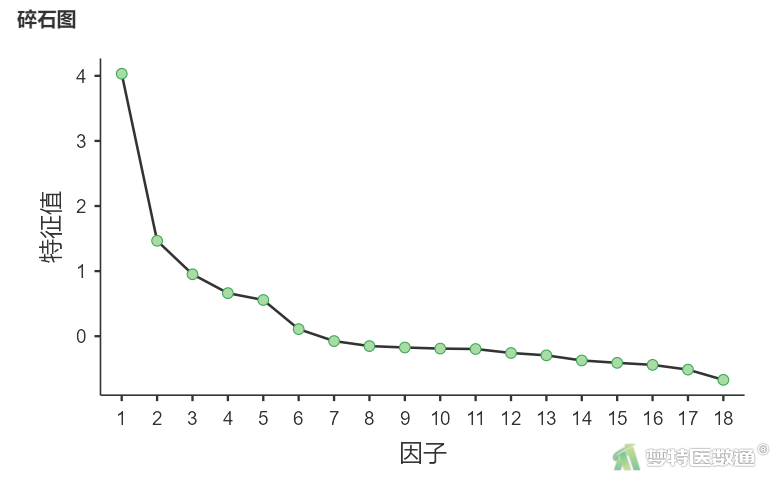
在“附加输出结果”中,勾选“碎石图”(图10),结果见图11。
“碎石图”(图9)以图形化的方式展示了因子的特征值变化,可见前五个因子后迅速变缓,辅助提示提取5个维度较为合适。

4. KMO检验系数和Bartlett检验结果
KMO检验系数和Bartlett检验结果会随着条目的改变而发生变化。本案例分析,最终“KMO抽样适合性检验”结果(表10)显示,“整体”MSA系数为0.796,提示数据抽样充分,结构很适合进行因子分析。“Bartlett’s球形检验”结果(表11)显示,χ²=1546.166,P<0.001,提示数据结构适合进行因子分析。
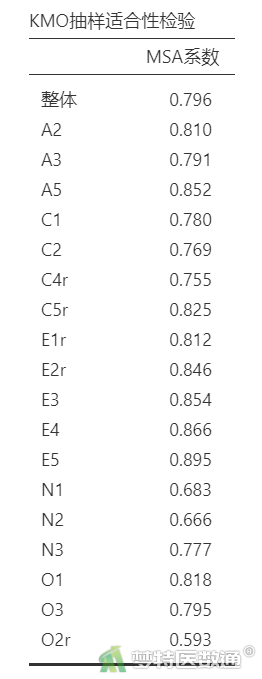
表10

四、结论
本研究采用探索性因子分析方法评估心理人格量表的结构效度情况。初始量表数据结构合理(KMO检验系数为0.808,Bartlett’s球形检验结果为P<0.001),提示数据可以进行探索性因子分析。
通过判断条目是否与预期专业维度相匹配删除了O4和N4两个条目,通过公因子方差判断删除了C3、A1r、N5、A4、O5r五个条目,最终保留18个条目构成5个维度。最终量表的KMO检验系数为0.796,Bartlett’s球形检验结果为P<0.001。五个维度分别解释11.116%、11.080%、10.535%、9.810%和8.565%的总数据变异,累计解释51.106%的数据变异。综上所述,该研究数据结构效度水平一般。
五、分析小技巧
- 结构效度分析结果不理想如何处理?
结构效度分析,是综合各项指标进行综合判断,包括KMO检验系数和Bartlett检验结果、因子载荷系数、公因子方差、方差解释率、累积方差解释率等。分析过程中,往往不是一步到位,而是需要删除条目,重复进行多次,以使维度和条目对应关系符合预期,找出最优结果;最为关键的就是使维度和条目对应关系与专业预期符合。
- 非量表数据的结构效度不能通过EFA分析怎么办?
对于非量表数据的结构效度,往往只需要使用文字描述问卷的设计过程,包括参考依据、问题设计与思路如何保持一致性、是否进行过预测试和专家团队的评估、对问卷进行过哪些修改处理等。