在SPSS中,一般线性模型一元方差分析(单变量方差分析)适合于多种实验设计模型,在分析不同类型的资料时,有些过程是相同的,故本文先介绍其一般过程。
关键词:SPSS; 一般线性模型; 一元方差分析
SPSS主菜单“分析(Analyze)”下的“一般线性模型(general linear model)”过程含有4个子模块:一元方差分析/单变量方差分析(univariate ANOVA)、重复测量方差分析(repeated measures ANOVA)、多变量方差分析(multivariate ANOVA)和方差成分分析/方差分量分析(variance components analyze)。一元方差分析主要适用于:
- 研究主效应的实验设计方案:包括完全随机设计(completely randomized design)、随机区组设计/配伍设计(randomized block design)、交叉设计(crossover design)、拉丁方设计(latin square design)
- 考虑交互作用的实验设计方案:包括析因设计(factorial design)、正交设计(Orthogonal design)
- 误差项变动的特殊实验设计方案:包括嵌套设计(nested design)、重复测量设计(repeated measures design)、裂区设计(split-plot design)
- 协方差分析(analysis of covariance,ANCOVA)
一、主对话框
(一) 调用模块
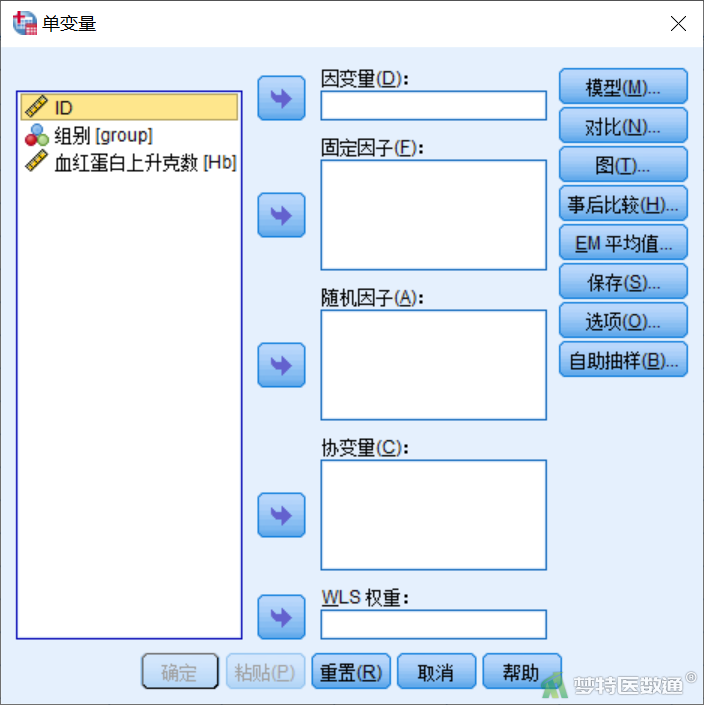
从菜单选择“分析(Analyze)”—“一般线性模型(General Linear Model)”—“单变量(Univariate)” (图1)。弹出“一元/单变量(Univariate)”主对话框(图2)。
(二) 主页面介绍
- 因变量/反应变量(Dependent Variable):只限选入1个变量,且为定量变量。
- 固定因子(Fixed Factor(s)):适于固定效应模型。该因素为分类(组)变量,可选入1个或多个。
- 随机因子(Random Factor(s)):当应用随机效应模型或混合效应模型时,将随机变量选入。
- 协变量(Covariate(s)):与因变量有关的定量变量,协方差分析时选用。
- WLS权重(WLS Weight):变量加权。用于加权最小二乘分析。
二、模型(Model)介绍
点击图2右侧“模型(Model)”按钮,弹出“单变量:模型(Univariate:Model)”对话框(图3)。
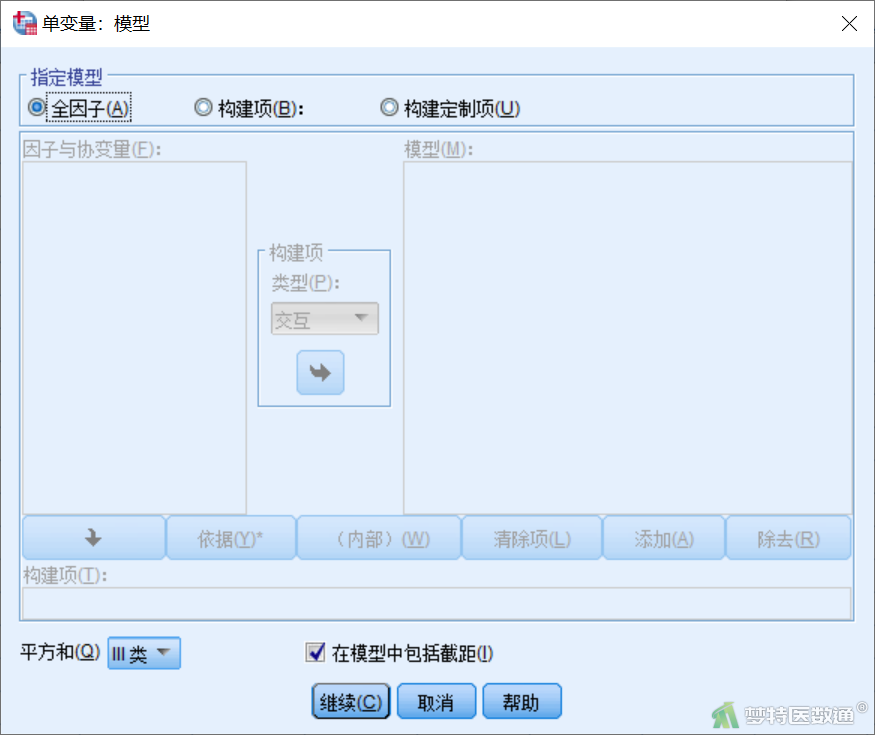
- 定义模型/指定模型(Specify Model)
- 全因子/全因素模型(Full Factorial):系统默认。包括所有因素的主效应和所有因素各种组合的交互效应分析,但不包括与协变量的交互效应分析。
- 构建项/自定义模型1 (Build Terms):自行规定待分析的因素主效应和部分交互效应,可包括因素与协变量的交互效应。
- 构建项/自定义模型2 (Build Custom Terms):可逐个设定每个变量的嵌套项。主要用于裂区设计和嵌套设计资料的分析。
- 因子和协变量(Factors&Covariates):选入的分析因素及协变量。
- 构建项类型(Build Term(s) Type):当选择“构建项/自定义模型1 (Build Terms)”或“构建项/自定义模型2 (Build Custom Terms)”时,此框被激活,用户可自已选择主效应因素和交互效应因素,所选项均显示在此框内。选择“构建项/自定义模型1 (Build Terms)”时,在“因子和协变量(Factors&Covariates)”框内选择某个或某几个因素后,该选项生效,各选项含义如下:
①交互(Interaction):考虑所有因素不同水平各种组合的交互效应,为系统默认。
②主效应(Main effects):只考虑主效应,不考虑交互效应。
③所有二阶(All2-way):考虑所有2个因素的交互效应。
④所有三阶(All3-way):考虑所有3个因素的交互效应。
⑤所有四阶(All4-way):考虑所有4个因素的交互效应。
⑥所有五阶(All5-way):考虑所有5个因素的交互效应。
选择“构建项/自定义模型2 (Build custom terms)”时,最下方的一排功能键被激活。选择变量,点击向下箭头,变量进入“构建项(Build Term)”下方的框,分析单个变量主效应时,直接击“添加(Add)”按钮。若要分析与另一个变量的交互效应,击“依据(By*)”按钮,选入另一变量。分析嵌套设计资料时,把上一级变量选入“模型(Model)”后,将下一级变量选入“构建项(Build Term)”下方的框,点击“内部(Within)”按钮,再选入上一级变量,击“添加(Add)”按钮设置生效。点击“清除项(Clear Term)”按钮清除“构建项(Build Term)”框内变量,点击“除去(Remove)”按钮清除“模型(Model)”内变量。
- 平方和(Sum of squares Type Ⅲ):计算离差平方和方法。
计算离差平方和方法有4种方法供选择,即Type I、Type Ⅱ、Type Ⅲ和Type IV,系统默认Type Ⅲ。Type Ⅲ是应用最多的方法,它适于平衡或非平衡设计,而且是完整数据(with no empty cells)。Type I适于嵌套设计资料;Type Ⅱ适于平衡设计,且只做主效应分析;Type Ⅳ是基于Type Ⅲ的一种推广,适于平衡或非平衡设计,且为不完整数据(with empty cells)。需要指出,对于平衡设计的完整数据,4种方法的结果完全相同。
- 在模型中包括截距(Include Intercept in Model):系统默认。
三、对比(Contrasts)介绍
对比(Contrasts):因素内的水平间差值比较。
点击图2右侧“对比(Contrasts)”按钮,弹出“单变量:对比(Univariate:Contrasts)”对话框(图4),有6种方法可供选择。
四、图(Plots)介绍
图(Plots):交互效应轮廓图。
点击图2右侧“图(Plot)”按钮,弹出“单变量:交互效应轮廓图(Univariate:Profile Plots)”对话框(图5)。将各因素不同水平组合的均数在一维图形上标出,以直观地描述主效应和交互效应。最多可同时设置3个因素;
- 水平轴(Horizontal Axis):横轴代表的因素。
- 单独的线条(Separate Lines):不同线代表的因素。
- 单独的图(Separate Plots):分图代表的因素。
- 图(Plots):用于绘制图形的因素。
- 图表/图形类型(Chart Type):用于图形类型的选择。
- 折线图(Line Chart):绘制折线图。
- 条形图(Bar Chart):绘制条形图。
- 误差条形图(Error Bars):绘制误差条形图。
- 包括误差条形图(Include Error Bars):绘制包括误差线的条形图。
- 置信区间(95%)(Confidential Interval(95.0%)):均数的95%置信区间。
- 标准误差/均数标准误(Standard Error/Standard Error of mean):默认加减2个标准误,通常修改为1。
- 包括总平均数的参考线(Include Reference Line For Grand mean):在所有观测值的均数处绘制一条水平参考线。
- Y轴从0开始(Y axis starts at 0)
五、多重比较(Post Hoc)
点击图2右侧“事后比较(Post Hoc)”按钮,弹出“单变量:实测平均值的事后多重比较(Univariate: Post Hoc Multiple Comparisons for Observed Means)”对话框(图6)。
- 假定等方差(Equal Variances Assumed):满足方差齐性的多重比较方法,共有14种供选择。
常用的方法有LSD (least-significant difference, 最小显著差值)法、SNK多重比较(Student-Neuman-Keuls test)、Scheffe法、Tukey 法、Duncan法、Bonferroni法等。其中,LSD法最敏感,Scheffe 法较不敏感,SNK多重比较、Bonferroni 法和Tukey法应用较多。多重比较一般在方差分析有统计学意义的情况下应用,若方差分析无统计学意义,无论多重比较的结果如何,都不应采纳。14种方法的最后一种为Dunnett法,是唯一一种用于多个处理组和一个对照组比较的方法。选择此项,可激活“控制类别(Control Category)”栏,栏中设定第1组(First)或最后1组(Last)为对照组供选择。“检验(Test)”栏中确定单、双侧检验。
- 不假定等方差(Equal Variances Not Assumed):不满足方差齐性的多重比较方法,共有4种供选择。
“塔姆黑尼T2(Tambane's T2)”表示基于t检验的保守的多重比较方法。“邓尼特T3(Dunnett's T3)”表示基于学生化极大模的多重比较方法。“盖姆斯-豪厄尔(Games-Howell)”表示非参数检验多重比较方法。“邓尼特(Dunnett's C)”表示基于学生化极差的多重比较方法,是一种置信区间的方法。以上方法可选择1种或多种进行分析。系统默认多重比较的显著性水平为0.05。
六、均数估计(EM Means)
点击图2右侧“EM 平均值(EM Means)”按钮,弹出“单变量: 估算边际平均值(Univariate:Estimated Marginal Means)”对话框(图7)。
- 因子与因子交互(Factor(s)and Factor Interactions):选人模型的主效应与交互效应项,如欲估计个别或全部因素的均数,选择这些因素,并送入右框
- 显示下列各项的平均值(Display Means for):显示框内因素的均数估计,包括均数、标准误及置信区间。
- 比较主效应(Compare Main Effects):比较各因素不同水平的主效应。选此项后,“置信区间调整(Confidence Interval Adjustment)”框被激活,有3种多重比较方法供选择,即LSD 法、Bonfferoni法和Sidak法。
七、保存(Save)
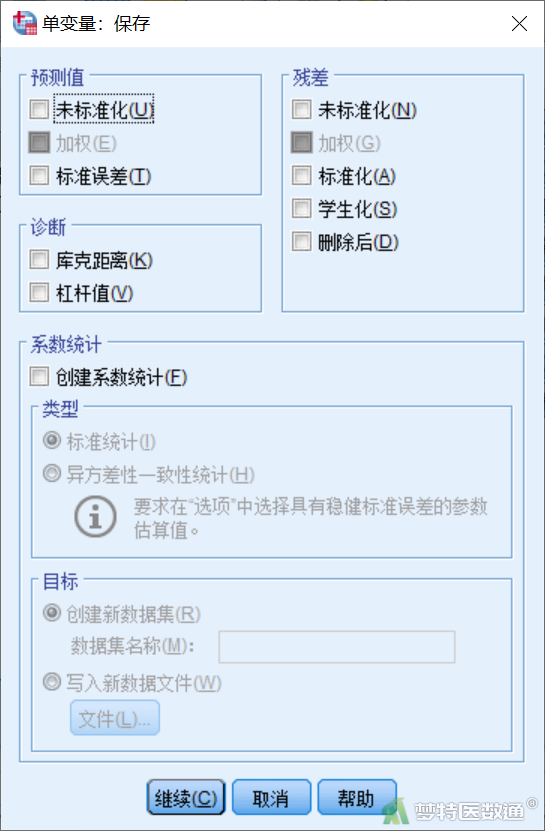
可将预测值、残差、Cook距离(Cook's Distance)等存为数据文件中的新变量,多用于回归分析。
点击图2右侧“保存(Save)”按钮,弹出“单变量: 保存(Univariate:Save)”对话框(图8),勾选需要保存的变量即可。
八、选项(Options)
点击图2右侧“选项(Options)”按钮,弹出“单变量: 选项(Univariate: Options)对话框(图9)。
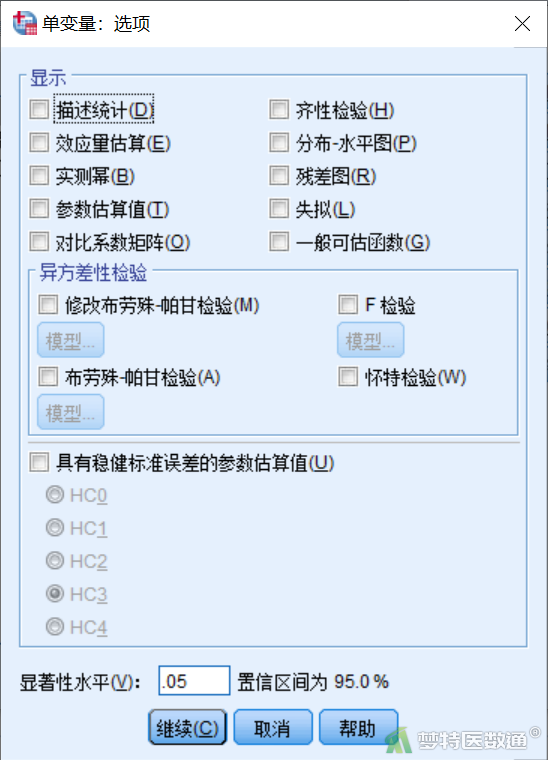
- 显示(Display):输出选项。
- 描述统计(Descriptive Statistics):描述统计量,包括均数、标准差和样本量。
- 效应量估计(Estimates of Effect Size):估计效应值大小的偏eta平方统计量。
- 实测幂(Observed Power):观察检验效能。由样本推算得来,与理论检验效能不同。
- 参数估算值(Parameter Estimates):参数估计,包括回归系数及其标准误、t检验等。
- 对比系数矩阵(Contrast Coefficient Matrix):水平间差值比较的系数矩阵。
- 齐性检验(Homogeneity Tests):检验因变量的方差在不同的因素组合下是否相同。
- 分布-水平图(Spread vs.Level Plot):不同因素组合的均数与标准差(方差)的散点图。
- 残差图(Residual Plot):残差、观察值及预测值3变量相关散点图。
- 失拟(Lack of Fit):失拟检验,检验模型拟合是否有意义。
- 一般可估函数(General Estimable Function):水平间比较的一般线性组合函数。
- 异方差性检验(Heteroskedasticity Test):检验随机误差是否与自变量取值有关。有4种检验方法可选,即Modified Breusch-Pagan test、Breusch-Pagan test、F test和 White’s test。
- 具有稳健标准误差的参数估算值(Parameter Estimates with Robust Standard Errors):基于稳健性标准误的参数估计。有HCO~HC4等5种协方差矩阵稳健估计方法可选。
- 显著性水平(Significance level ):系统默认显著性水平为0.05,可自定义,置信区间为95.0%,不可调整。
九、自展法(Bootstrap法)
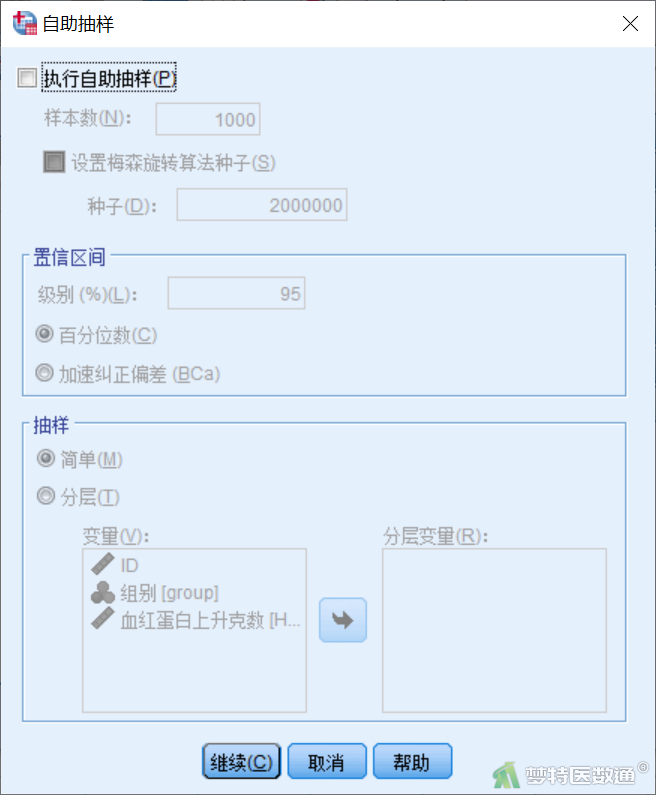
点击图2右侧“自助抽样(Bootstrap)”按钮,弹出“自助抽样(Bootstrap)”对话框(图10)。
该法对观测数据集进行有放回的随机抽样,进行假设检验和参数估计,特别适用于那些难以用常规方法导出参数的区间估计和假设检验等问题。它对数据的样本量和是否服从正态分布不做要求,但计算量较大。