预测模型目前已运用至临床各学科,本文选择了呼吸系统相关疾病肺结核治疗不成功的临床预测模型进行解读。文献来源于Lauren S. Peetluk等发表的A Clinical Prediction Model for Unsuccessful Pulmonary Tuberculosis Treatment Outcomes (https://pubmed.ncbi.nlm.nih.gov/34214166/)。我们首先根据Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis (TRIPOD)提供的Checklist对该案例进行详细解读,其后使用PROBAST: A Tool to Assess the Risk of Bias and Applicability of Prediction Model Studies (评估预测模型研究偏倚风险和适用性的工具)对该研究的偏倚风险和适用性进行评价。
关键词:床预测模型; 诊断模型; 预后模型; 报告规范; TRIPOD; 偏倚风险; 适用性
在临床预测模型文献解读——呼吸系统代表性文献:肺结核治疗不成功的临床预测模型(上)一文中按TRIPOD条目清单解读了【条目1~9】,本文继续根据【条目10~17】进行文献解读。
(七) 统计分析方法
【条目10a】描述在统计分析中如何处理预测因子(建模过程中)
【解读】作者根据霍夫丁D统计量(Hoeffding D statistic)考察了预测因子间的共线性,通过限制性立方样条(设置5个节点)评估了连续性变量(年龄、BMI、教育年数、血红蛋白)与结局风险之间的非线性关系,发现仅有年龄与结局风险间为非线性关系,因此转化为分类变量(18-24.9、25-34.9、35-44.9、45-54.9、≥50)进行主分析,拟合限制性立方样条作为敏感性分析(图10-1)。

【条目10b】描述模型的类型、建模的全过程(包括预测因子的筛选)和内部验证的方法
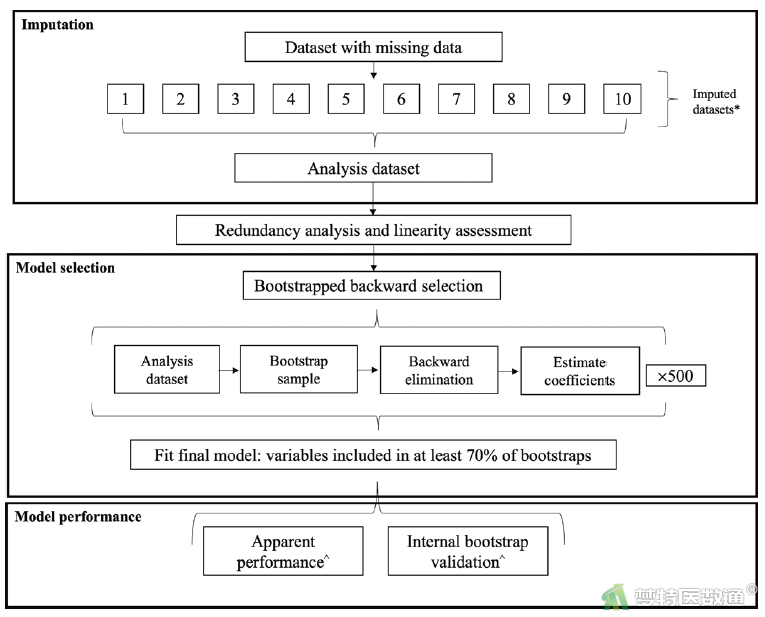
【解读】如前所述,该研究是开发肺结核治疗不成功的预后模型,由于未考虑结局的发生时间,所以采用的统计模型是二分类logistic回归模型。作者通过Bootstrap法进行500次抽样,在每个bootstrap样本中通过逐步向后法筛选重要的预测因子;将在500次筛选中被选中频率≥70%的预测因子纳入到最后的模型中进行建模;在敏感性分析中,将频率放宽至50%,再次选择预测因子建立模型。每个候选预测因子在每个数据集被选中的频率详见补充材料Supplementary File 5. Comparison of each model selection methods 。作者通过Bootstrap法进行了内部验证。建模流程详见原文的Figure 1(图10-2)。
同时,作者还通过模型近似法和LASSO回归进行了预测因子的筛选、建模和验证,并对多种方式建立的模型进行了比较,详细信息可查阅原文补充材料的S5 Table. Comparison of coefficients and coefficients and model performance across model selection methods和S5 Text. Alternative modeling approaches methods。
而且,作者考虑了CD4、HIV病毒载量和乙酰化可能带来的预测能力的增量,将上述预测因子加入前期建立的模型后进行了比较(图10-3)。

另作者使用自己的数据通过两种方式对Costa-Veiga model进行了外部验证:第一种是使用已有模型的系数计算出自己数据中研究对象的预后指数后进行外部验证,第二种是使用已有模型的预测因子基于自己数据重新拟合模型以对模型系数进行更新(图10-4)。

【条目10c】描述模型验证中预测值是如何计算的
【解读】暂未看到文中有相关的描述。
【条目10d】描述模型性能以及多个模型比较(如有)的评价指标
【解读】该研究通过C统计量来评估模型的区分度,通过校准图、校准截距、校准斜率和Hosmer-Lemeshow拟合优度检验评估模型的校准度,总体模型拟合用Brier评分进行评价,通过决策曲线分析评估了预测模型的净收益。在内部验证中,作者报告了乐观度校正的模型表现(图10-5)。

如【条目10b】所述,作者通过不同变量筛选方式建立了多个模型,以及使用50%的频率选择Bootstrap逐步向后法确定的预测因子建模,并通过Birer评分、校准斜率、校准截距、C统计量对三个模型进行了评价与比较(图10-6)。

另外,考虑到HIV相关的信息和异烟肼乙酰化转态的预测价值增量,使用似然比检验、净重分类指数(NRI)、综合判别改善指数(IDI)等进行了模型的比较(图10-7)。

【条目10e】如有,描述模型验证后进行的更新(如再校准)
【解读】该研究为预测模型的开发与内部验证,不涉及模型的更新。
(八) 风险分层
【条目11】描述进行风险分层的细节(如有)
【解读】根据临床相关性和未来研究的潜在效用,作者预先设定了截断值,将研究对象划分为3个风险组:预测风险阈值<10为低风险组,10-20为中风险组,≥20为高风险组,并计算了相应的灵敏度、特异度、阳性预测值和阴性预测值(图11)。

(九) 数据集比较
【条目12】明确训练集和验证集在研究场景、纳入排除标准、结局指标和预测因子方面的差异
【解读】该研究采用的是内部验证,无独立的或随机/非随机分组而得的验证集,因此该条目不适用。
四、结果
(一) 研究对象
【条目13a】建议绘制流程图,描述研究对象在整个研究中的流动情况,包括出现结局和未出现结局的研究对象数量;如适用,对随访时间进行概述
【解读】在结果部分的第一段和第二段,作者描述了该研究共纳入944例合格的研究对象,随访过程中191例(20%)出现兴趣结局(治疗不成功),753例治疗成功。治疗不成功组的中位随访时间为107 (IQR, 41-176)天,治疗成功组的中位随访时间为186 (IQR, 179-205)天(图12)。但未根据纳入排除标准详细描述研究对象的纳入和排除的过程及相对应的例数,也未给出研究对象的整体随访时间的中位数(四分位间距)。

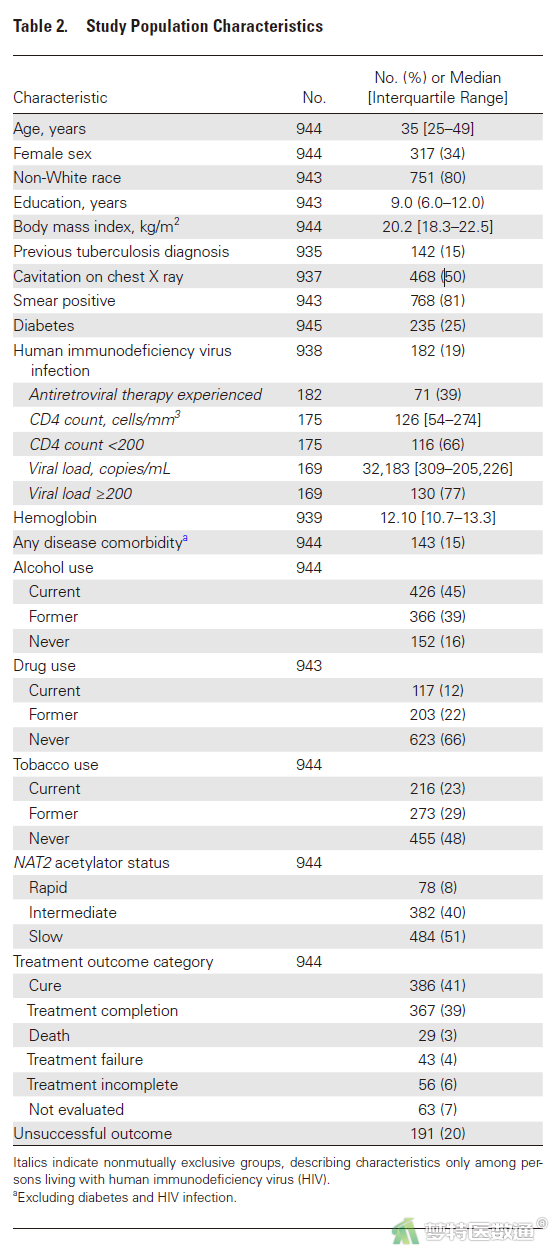
【条目13b】描述研究对象的特征(基线人口统计学特征、临床特征、候选预测因子),包括有预测因子和结局指标缺失的研究对象数量
【解读】在Table 2中(图13),作者对候选预测因子的分布或构成情况进行了描述,从各个变量对应的研究对象总例数来看,种族、受教育年数、结核既往史、胸片空洞、痰涂片结果、HIV感染情况、血红蛋白、吸毒等变量有缺失值;另外,还指出914例研究对象不存在任何预测因子的数据缺失。
另外,本研究共944例研究对象,但Table 2中糖尿病这一变量对应的例数为945,估计为笔误。
【条目13c】对训练集和验证集一些重要变量(如,人口统计学特征、预测因子和结局指标)的分布差异进行描述
【解读】该研究进行的是内部验证,此条目不适用。
(二) 模型建立
【条目14a】给出每次分析中涉及的研究对象和结局事件的数量
【解读】该研究的主分析是采用多重填补后的汇总数据进行预测因子筛选、建模和验证,研究对象例数为944例,发生结局例数为191 (图14)。从文中的相关描述可知,敏感性分析中使用了多重填补法得到的10个完整的填补数据集进行建模和验证,研究对象例数和结局数与前述相同;同时,还通过完整案例法进行了敏感性分析,即剔除有缺失的研究对象,则应为914例,但正文和补充材料中均未见到对应的结局例数。

【条目14b】报告候选预测因子与结局间未校正的关联及关联程度 (如有)
【解读】该研究未进行单因素分析,主分析中是在500次Bootstrap抽样后,通过逐步向后法筛选预测因子,并用被选中频率≥70%的预测因子进行建模和验证以及评价,直接给出的是校正后的偏回归系数,并无表示未校正的预测因子与结局指标间关联程度的回归系数或OR值等。此条目不适用。
(三) 模型详情
【条目15a】给出能对个体进行预测的完整预测模型信息(即,所有预测因子的回归系数、模型截距、既定时间点的基准生存率)
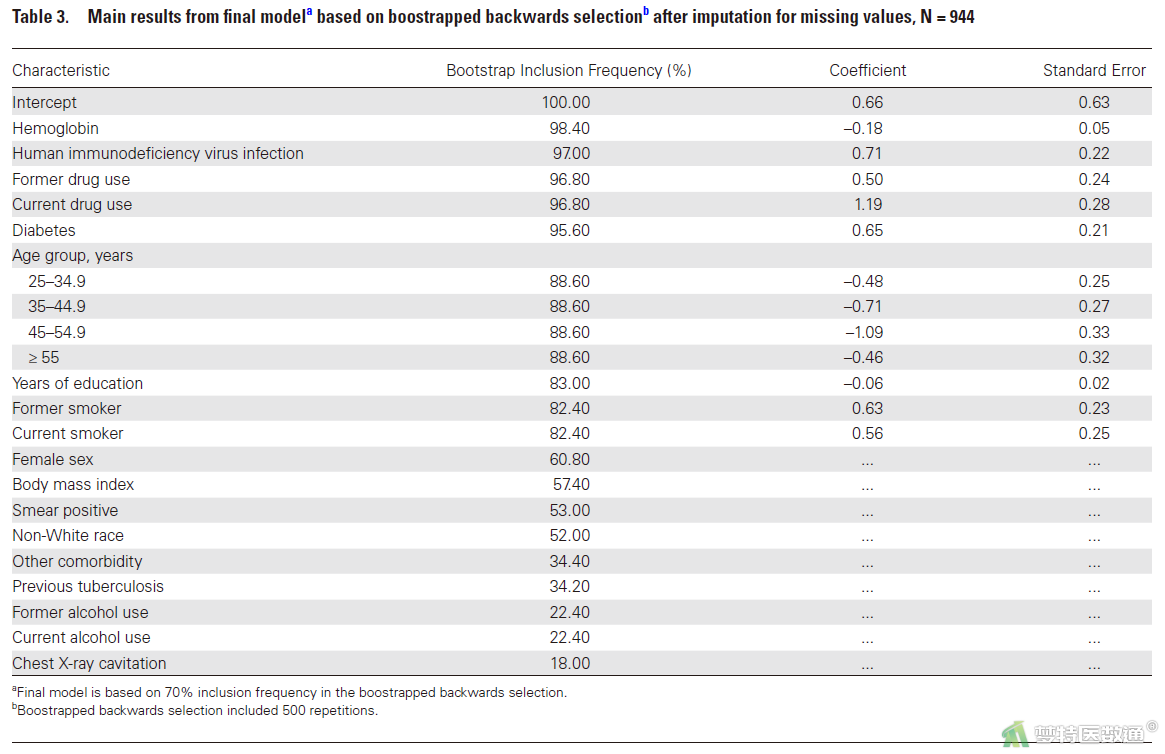
【解读】在正文的Table 3中,作者给出了最终模型中纳入的预测因子(血红蛋白、感染HIV、吸毒、糖尿病、年龄分组、受教育年数、吸烟情况)、对应的系数和截距以及标准误。另外,在补充材料中还给出了各种敏感性分析中得到的预测因子及其变量系数等信息(图15-1)。
【条目15b】说明如何使用预测模型
【解读】作者根据模型中预测因子的系数和截距以及分类logistic模型的公式,建立了预测肺结核治疗不成功的公式(图15-2),根据该公式可以得到肺结核初治者将来治疗不成功的风险值/概率;但文章中的公式表达似乎有误,模型的截距为0.66,血红蛋白的系数为-0.18,公式中写成了0.660.18*[hemoglobin],应为0.66-0.18*[hemoglobin]。而且,作者还将所建立的预测模型转化为静态列线图(见原文的Figure 3,图15-3);同时,为了方便应用,作者还基于shinyapp开发了网页应用程序,并给出了网址(https://lauren-peetluk.shinyapps.io/tb_outcome_risk_calculator)。在该网页程序中,使用者只需要在相应的预测因子中输入或勾选患者的信息,即可得到将来治疗不成功的概率(图15-4)。
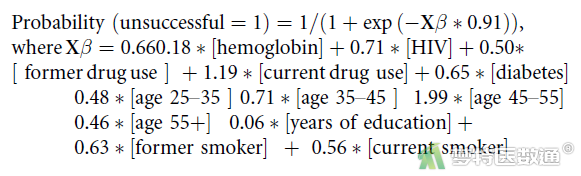
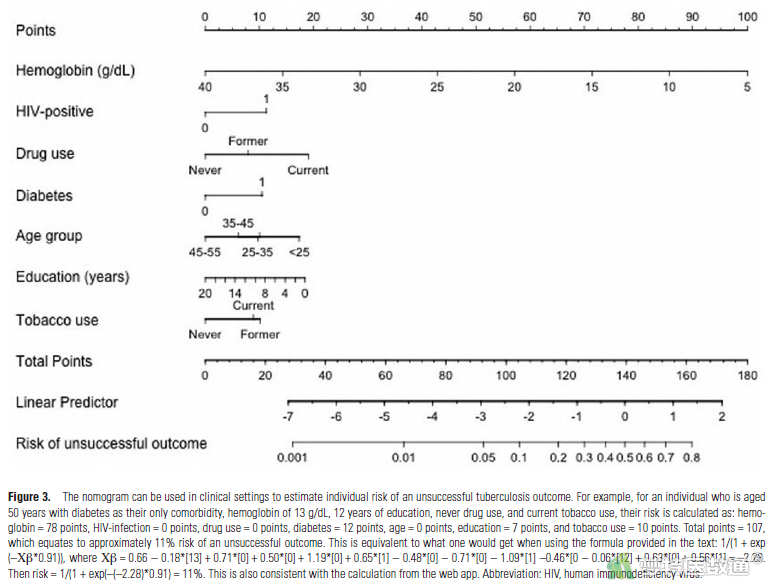
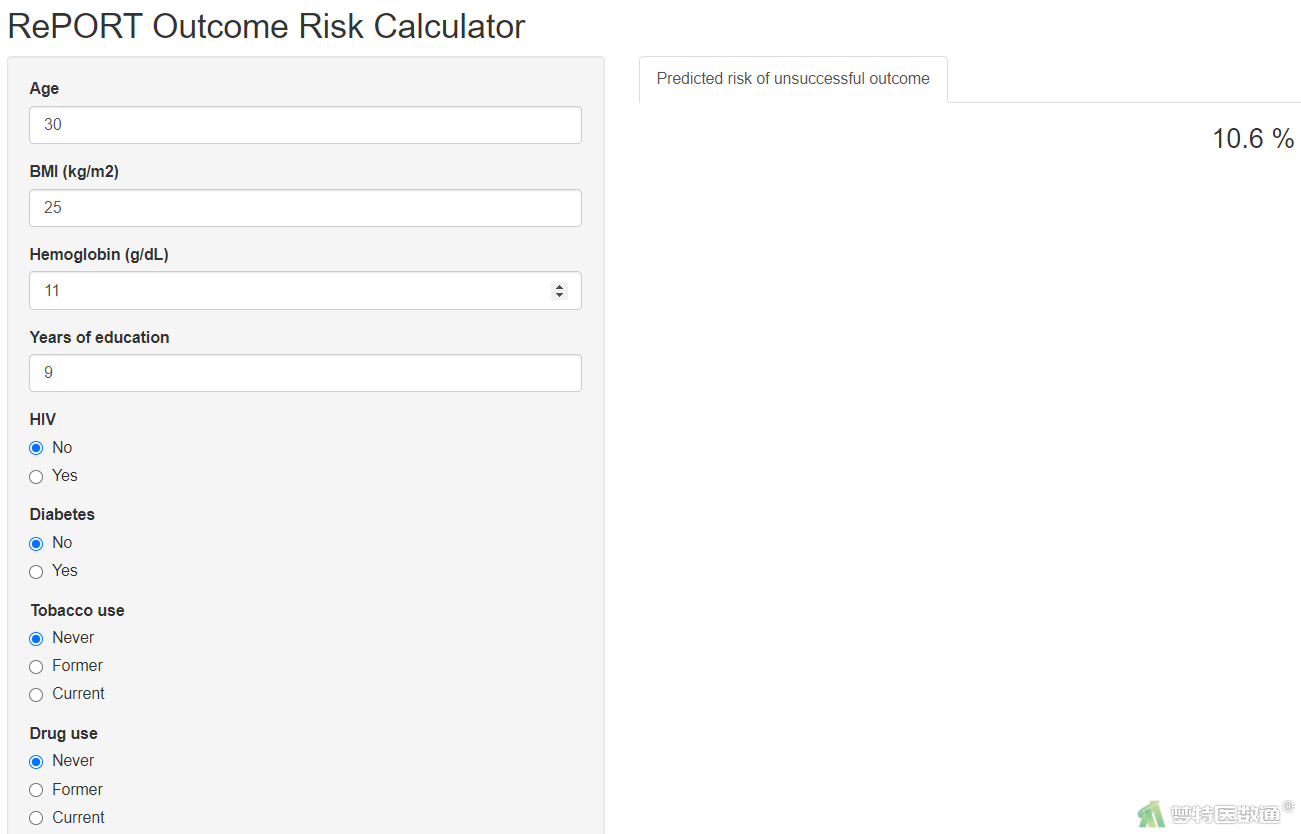
另外,根据模型的预测值进行了分层,医护人员等根据分层标准快速地将肺结核初治者分为低、中和高风险组,识别其风险程度:当预测的风险值<10%,则将来肺结核治疗不成功的风险为低风险;当预测的风险值为10%-20%,则将来肺结核治疗不成功的风险为中风险;当预测的风险值≥20%,则将来肺结核治疗不成功的风险为高风险(图15-5)。
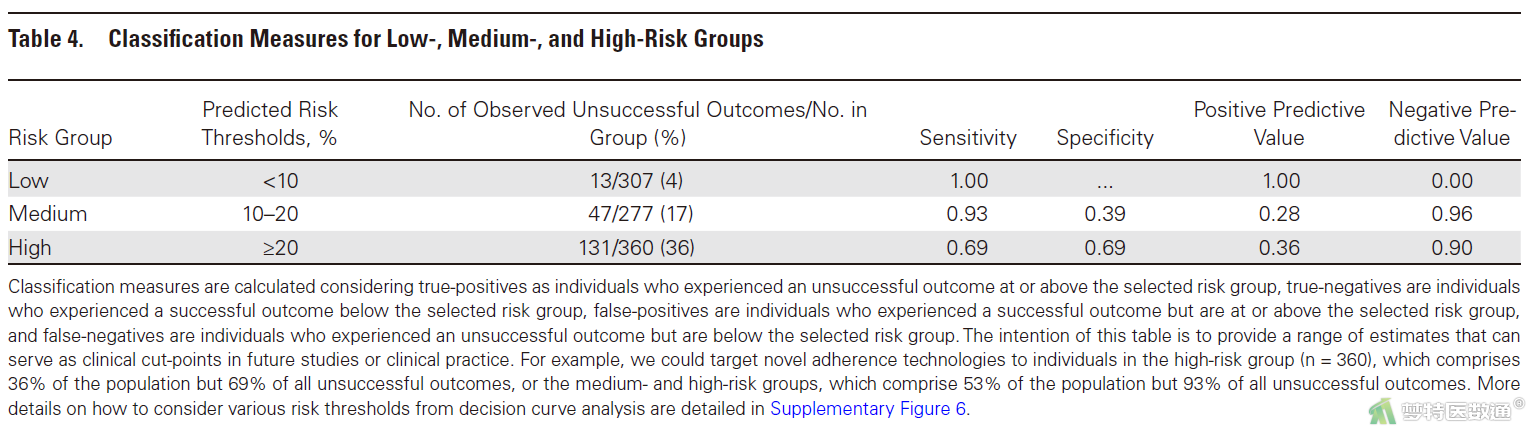
(四) 模型性能
【条目16】报告评价预测模型性能的指标及95%置信区间
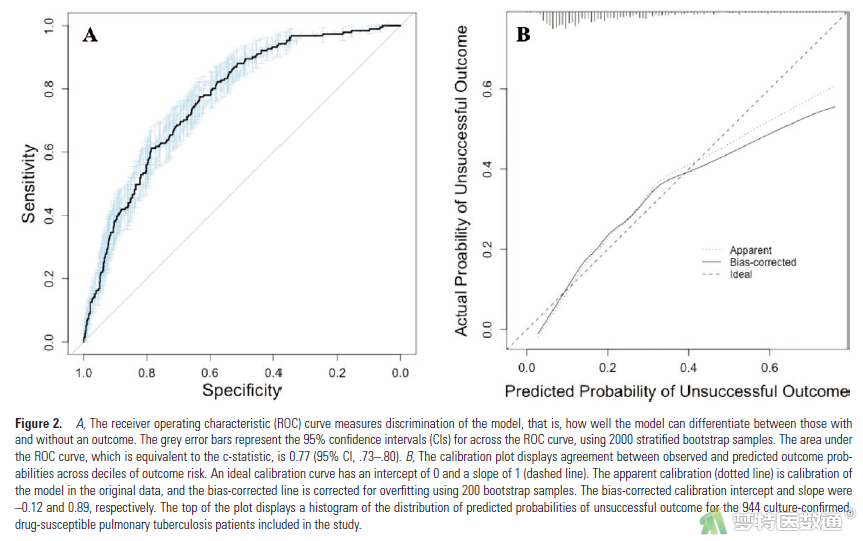
【解读】作者从区分度(ROC曲线、C统计量/乐观度校正的C统计量)、校准度(Hosmer-Lemeshow 拟合优度检验的结果、Brier评分、校准曲线、校准斜率/乐观度校正的校准斜率、校准截距/乐观度校正的校准截距)和临床净收益(决策曲线分析)三个角度报告了新建立的预测模型性能评价结果,通过似然比检验、净重分类指数(NRI)、综合判别改善指数(IDI)等考察了抗逆转率病毒治疗(ART)史、CD4<200、HIV载量≥200和NAT2加入模型后模型性能的增量。
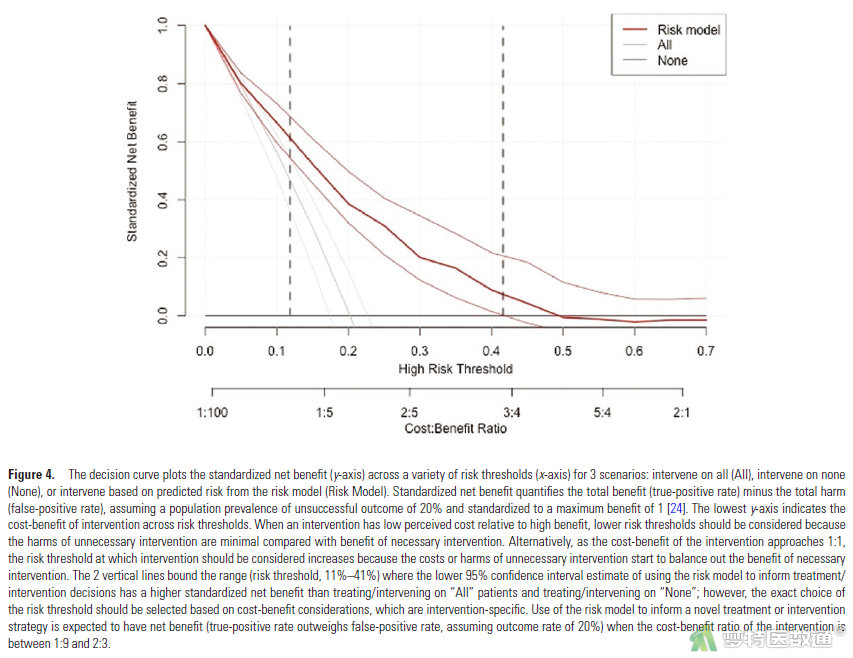
预测模型的ROC曲线如原文Figure 2A所示,C统计量为0.77 (0.73-0.80),乐观度校正的C统计量为0.75 (0.71-0.78),表明模型的区分度良好。校准度曲线如原文Figure 2B所示,在预测概率对于0.40时,校准曲线和标准曲线很接近,校准度良好;Brier评分为0.14,H-L检验的P值为0.1(>0.05),乐观度校正的校准截距和斜率分别为-0.12和0.89 (图16-1、图16-2)。决策曲线如原文Figure 4所示,当成本-收益比在1:9至2:3之间,或风险阈值在11%-41%之间时,基于该模型进行决策可获得净收益(图16-3、图16-4)。


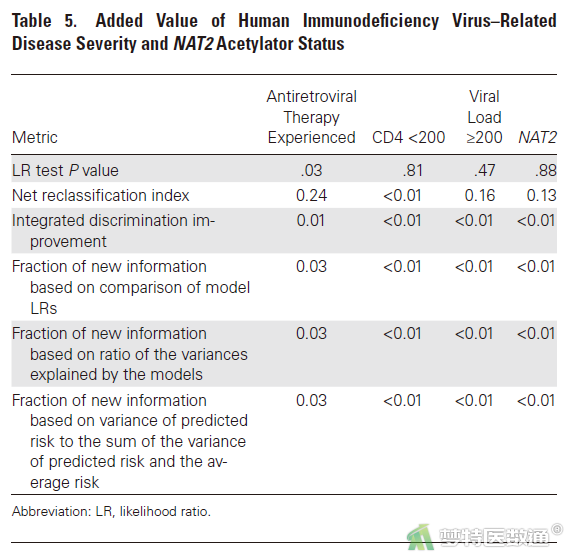
加入抗逆转率病毒治疗史后,新模型与前期建立模型的似然比检验有统计学意义,对应的NRI和IDI分别为0.24和0.01,而CD4、病毒载量和NAT2的模型性能增量无统计学意义(图16-3),其他信息详见原文Table 5 (图16-5)。
(五) 模型更新
【条目17】报告模型更新的结果,即新模型的详情和性能
【解读】该研究不涉及预测模型的更新,此条目不适用。 关于TRIPOD声明的更多内容,详见Moons KG等作者发表的文章“Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD): explanation and elaboration (https://pubmed.ncbi.nlm.nih.gov/25560730/)”,曹煜隆等作者发表的文章“个体预后与诊断预测模型研究报告规范——TRIPOD声明解读(http://www.cjebm.com/article/10.7507/1672-2531.201912032)”。关于PROBAST偏倚风险评价的更多内容,详见Wolff RF等作者发表的文章“PROBAST: A Tool to Assess the Risk of Bias and Applicability of Prediction Model Studies (https://pubmed.ncbi.nlm.nih.gov/30596875/)”,陈茹等作者发表的文章“预测模型研究的偏倚风险和适用性评估工具解读 (http://chinaepi.icdc.cn/zhlxbx/ch/reader/view_abstract.aspx?file_no=20200530&flag=1)”。